
多模态长文本理解测评首发:46款模型无一攻克128K难关
多模态长文本理解测评首发:46款模型无一攻克128K难关来自香港科技大学、腾讯西雅图AI Lab、爱丁堡大学、Miniml.AI、英伟达的研究者联合提出了MMLongBench,旨在全面评估多模态模型的长文本理解能力。
来自主题: AI技术研报
9520 点击 2025-05-23 14:52
 搜索
搜索
来自香港科技大学、腾讯西雅图AI Lab、爱丁堡大学、Miniml.AI、英伟达的研究者联合提出了MMLongBench,旨在全面评估多模态模型的长文本理解能力。
自去年11月底,360刚刚推出纳米AI搜索的时候,AI真探社就曾发过一篇文章跟进报道。当时国内的AI搜索赛道还是一片蓝海,除了百度作为ALL IN AI时代的代表以外,也就天工搜索和秘塔AI搜索还在这个赛道里面,所以我们当时和主流观点一样,认为360这个老牌搜索大厂的入局或能起到一个鲶鱼效应,甚至有再现曾经百度搜索对打360搜索的名场面的可能性:
来自香港中文大学(深圳)等单位的学者们提出了一种名为 DriveGEN 的无训练自动驾驶图像可控生成方法。该方法无需额外训练生成模型,即可实现训练图像数据的可控扩充,从而以较低的计算资源成本提升三维检测模型的鲁棒性。

Anthropic,今晚扔出了真正的核武器——全球最强编程模型Claude 4!能连续编码7小时不断的Opus 4,再一次让大模型能力实现了重大飞跃。网友实测后惊呼:不可能,从未见过一个AI做到这样的事!

对于百度而言,既要保持长期主义的战略定力,也要在技术路径上灵活应变,这种「变与不变」的平衡或许正是其在这轮科技革命中的制胜之道。

在机器人操作中,物体运动往往涉及摩擦、碰撞等复杂物理机制。准确的物理属性描述可以实现对物体运动结果更准确的预测,并提升机器人在操作技能学习中的表现。
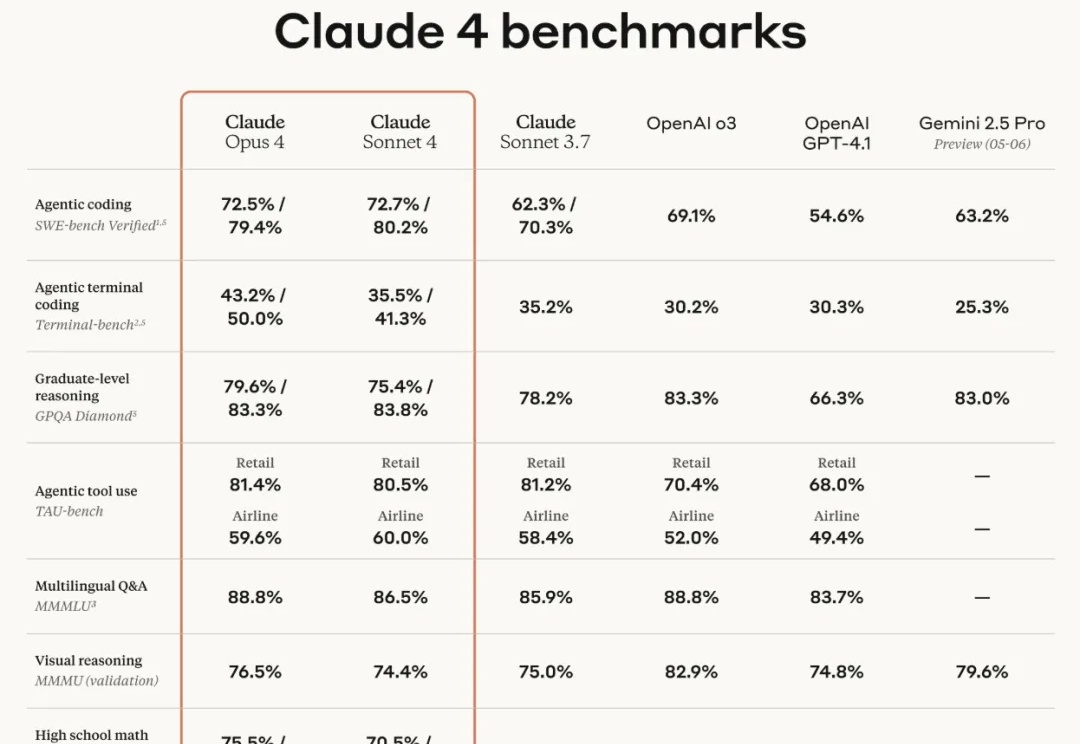
AI圈子好热闹。今天凌晨,Claude终于迎来了它的重大版本升级—— Claude 4来了!
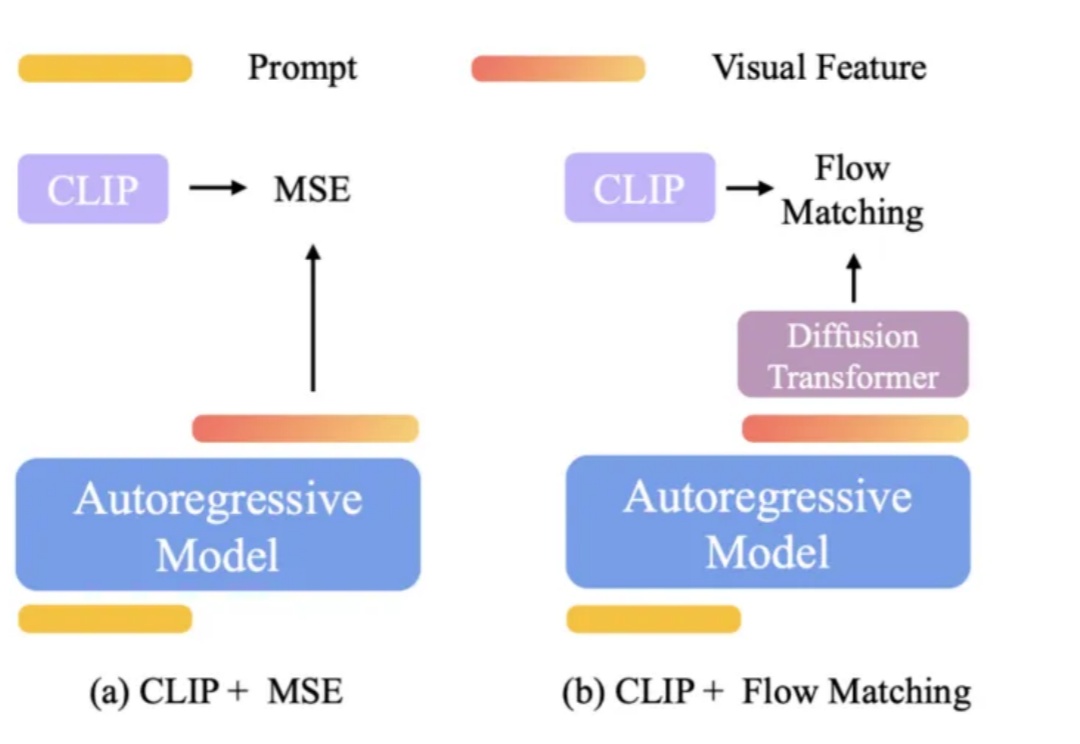
OpenAI 的 GPT-4o 在图像理解、生成和编辑任务上展现了顶级性能。流行的架构猜想是:
人工智能正以前所未有的速度改变世界,但其背后的核心机制,远不止于复杂的算法和算力堆叠。本文从神经科学先驱约翰·霍普菲尔德(John Hopfield)的研究出发,追溯深度学习的发展脉络,揭示一个令人意想不到的事实:许多现代AI模型的理论基础,源自上世纪物理学家研究磁性材料时提出的“自旋玻璃”模型。

要不了多久,“禁止学生用AI”就会成为一件很可笑的事情。