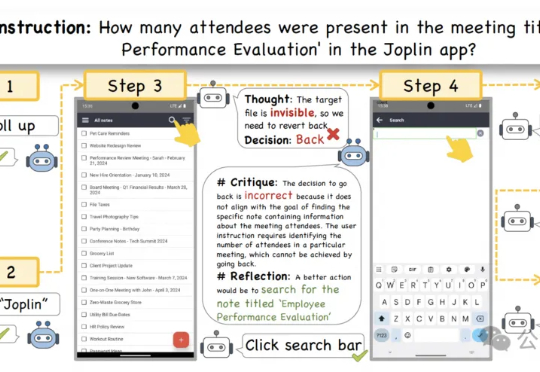
AI操作有了“紧急刹车”!通义&自动化所AI决策诊断模型,GUI智能体纠错正确率SOTA
AI操作有了“紧急刹车”!通义&自动化所AI决策诊断模型,GUI智能体纠错正确率SOTAGUI智能体总是出错, 甚至是不可逆的错误。 即使是像GPT-4o这样的顶级多模态大模型,也会因为缺乏常识而在执行GUI任务时犯错。在它即将执行错误决策时,需要有人提醒它出错了。
来自主题: AI资讯
10253 点击 2025-06-17 16:59
 搜索
搜索
GUI智能体总是出错, 甚至是不可逆的错误。 即使是像GPT-4o这样的顶级多模态大模型,也会因为缺乏常识而在执行GUI任务时犯错。在它即将执行错误决策时,需要有人提醒它出错了。

NVIDIA等研究团队提出了一种革命性的AI训练范式——视觉游戏学习ViGaL。通过让7B参数的多模态模型玩贪吃蛇和3D旋转等街机游戏,AI不仅掌握了游戏技巧,还培养出强大的跨领域推理能力,在数学、几何等复杂任务上击败GPT-4o等顶级模型。
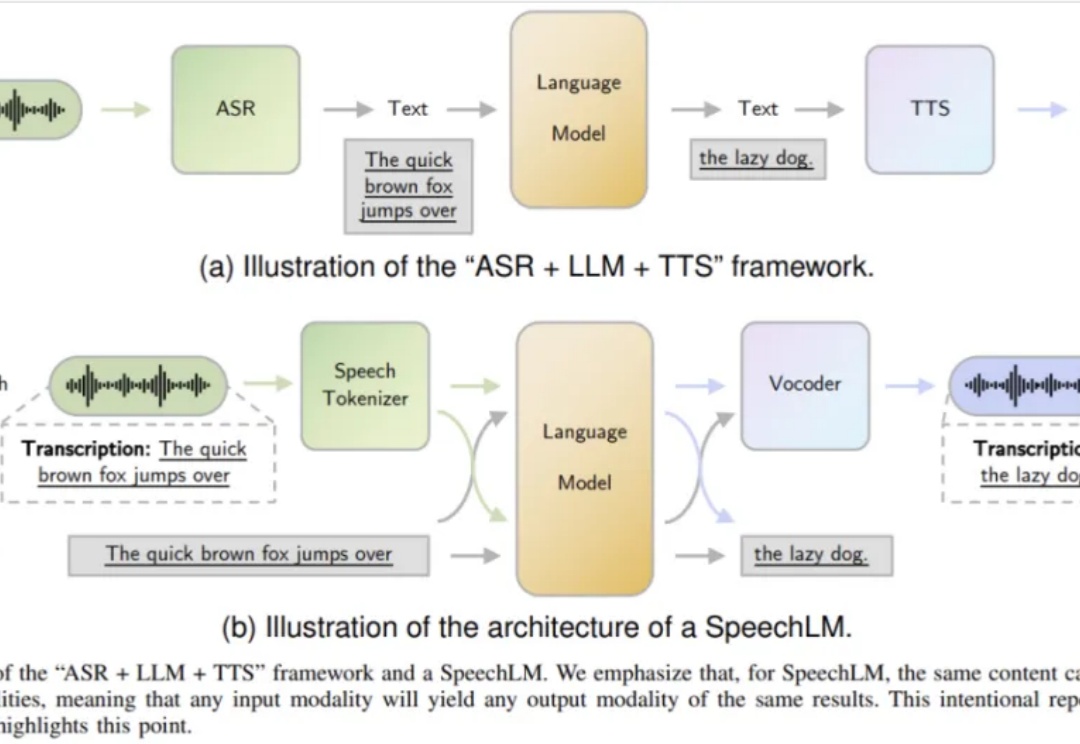
由香港中文大学团队撰写的语音语言模型综述论文《Recent Advances in Speech Language Models: A Survey》已成功被 ACL 2025 主会议接收!这是该领域首个全面系统的综述,为语音 AI 的未来发展指明了方向。

美国国防部与OpenAI签订为期一年、价值2亿美元的合同,将采用其人工智能模型

随着大模型的不断发展,多模态数据处理成为了新的热点领域。多模态生成任务主要通过整合多种类型的数据,如文本、图像、音频等,实现不同模态之间的相互转换与生成。
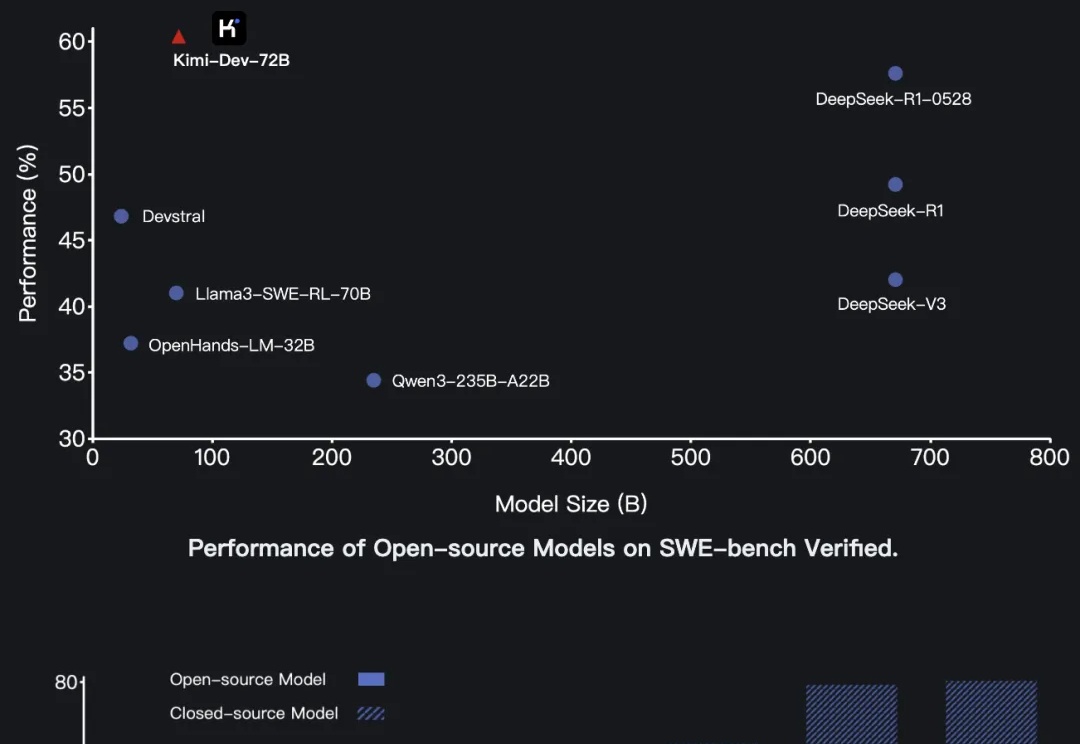
深夜,沉寂已久的Kimi突然发布了新模型—— 开源代码模型Kimi-Dev,在SWE-bench Verified上以60.4%的成绩取得开源SOTA。
在苹果AI中国版一片静默之际,阿里出牌了。

在开源模型领域,DeepSeek 又带来了惊喜。
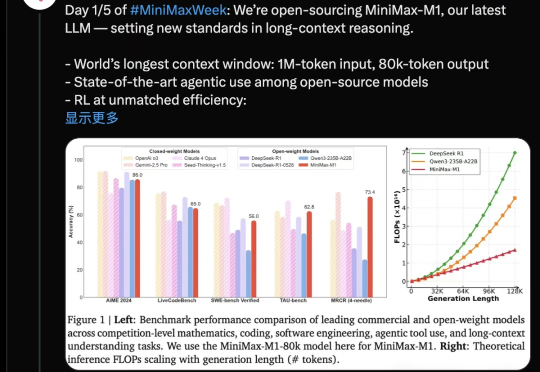
国产推理大模型又有重磅选手。MiniMax开源MiniMax-M1,迅速引起热议。

图像生成界的“大魔王”Midjourney也来卷视频生成了?!