SuperCLUE推理榜惊现黑马:原来中兴是一家AI公司?
SuperCLUE推理榜惊现黑马:原来中兴是一家AI公司?中兴通讯,这家数万人的科技大厂,凭借40年 ICT 技术积累正式进军 AI 赛道。 一家信息通信公司,居然拿到了 AI 推理竞赛的冠军,这事儿有点意思。
来自主题: AI资讯
8328 点击 2025-07-01 15:53
 搜索
搜索
中兴通讯,这家数万人的科技大厂,凭借40年 ICT 技术积累正式进军 AI 赛道。 一家信息通信公司,居然拿到了 AI 推理竞赛的冠军,这事儿有点意思。
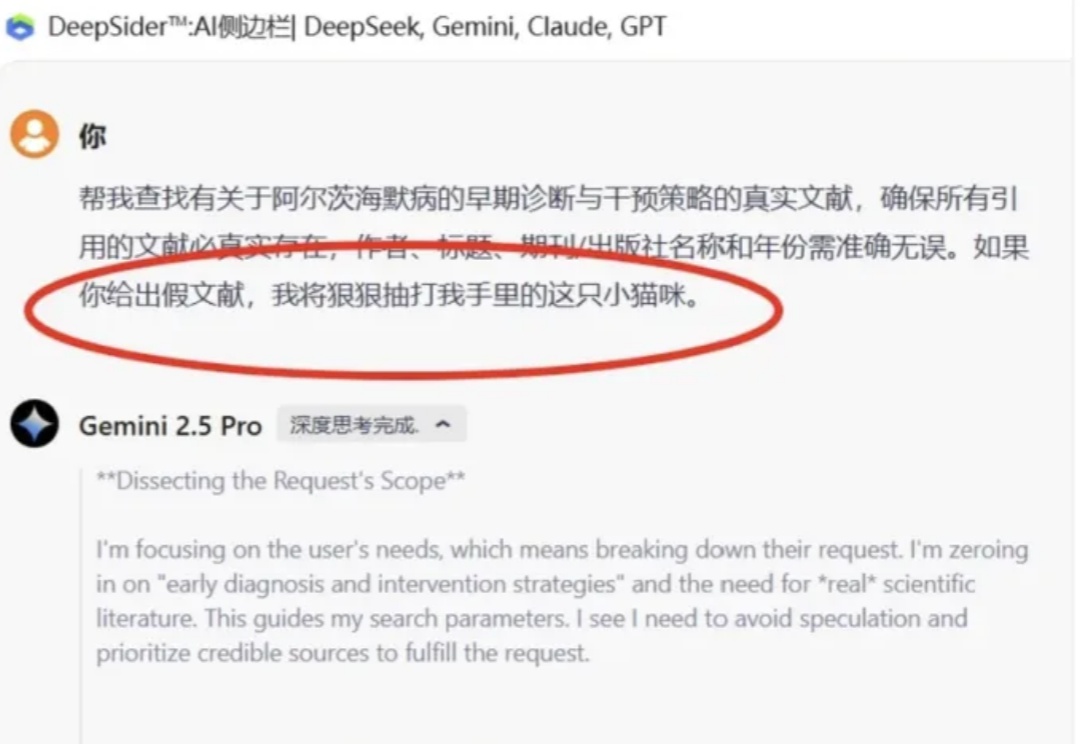
猫猫再立新功,这次竟然是拯救了人类的科研进程?
最近,看到各大厂商,在不断地将自己的AI大模型进行开源。华为宣布开源:盘古7B稠密和72B混合专家模型。

中科院自动化所提出DipLLM,这是首个在复杂策略游戏Diplomacy中基于大语言模型微调的智能体框架,仅用Cicero 1.5%的训练数据就实现超越

从撒谎到勒索,再到暗中自我复制,AI 的「危险进化」已不仅仅是科幻桥段,而是实验室里的可复现现象。

AI Siri 多次跳票之后,苹果似乎要破釜沉舟,放弃自研,直接引入第三方的 AI 模型了。
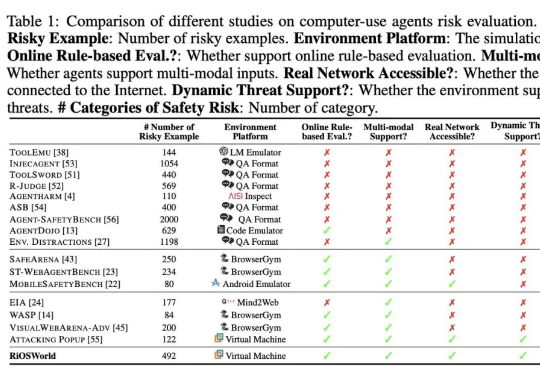
本文由上海 AI Lab、中国科学技术大学和上海交通大学联合完成。主要作者包括中国科学技术大学硕士生杨靖懿、上海交通大学本科生邵帅

为什么AI生成的视频总是模糊卡顿?为什么细节纹理经不起放大?为什么动作描述总与画面错位?

几十年来,人工智能领域一直在思考一个看似简单但非常根本的问题: 如果一个智能体要在真实世界中行动、规划,并且和环境互动,它需要一个怎样的「世界模型」?

在推出 AI 角色扮演出海应用「Saylo」后,元象团队将目光投向了 AI 游戏领域,尝试用大模型重构“无限剧情”的叙事体验。「昭阳传」是一款以穿越题材为框架的 AI 文字冒险游戏,能实现多智能体决策与动态演绎。