
“美国国运股”Palantir,怎么靠AI Agent大涨3000亿美元?
“美国国运股”Palantir,怎么靠AI Agent大涨3000亿美元?当全球目光都聚焦在OpenAI、Anthropic、谷歌、Meta等明星AI公司时,真正靠大模型落地大规模盈利的,却是一家相对不太知名的公司——Palantir。
来自主题: AI资讯
10663 点击 2025-07-04 12:43
 搜索
搜索
当全球目光都聚焦在OpenAI、Anthropic、谷歌、Meta等明星AI公司时,真正靠大模型落地大规模盈利的,却是一家相对不太知名的公司——Palantir。
近日,一则消息在网络上引发热议。有媒体称,“DeepSeek就AI模型违规关联王一博与‘李爱庆腐败案’,作出道歉。”
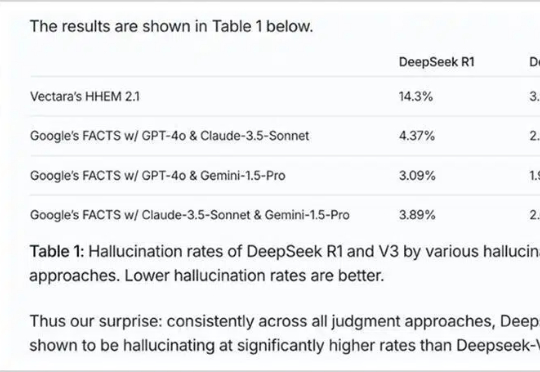
第一难当。AI变革遇上IPO盛宴,港股掀起一波资本巨浪。
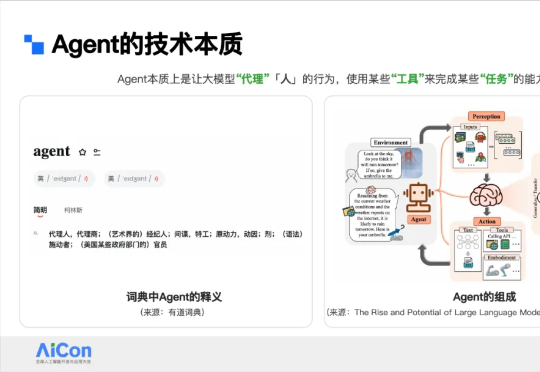
随着 AI Agent 技术的快速发展,业界许多企业开始在 Agent 方向进行深层次探索,而不仅仅是停留在“大模型 + 工具调用”的简单应用上。
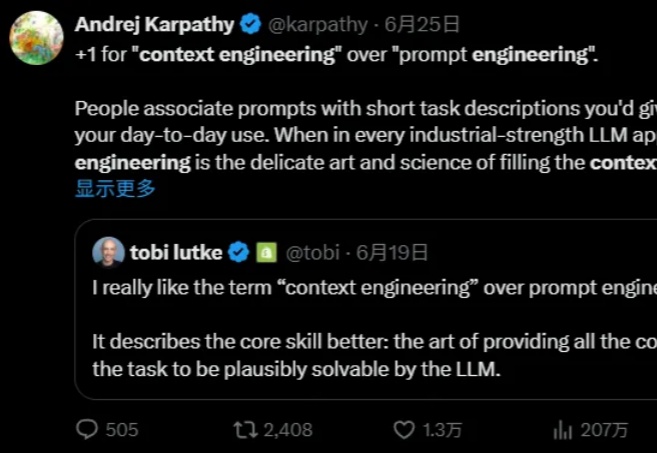
最近「上下文工程」有多火?Andrej Karpathy 为其打 Call,Phil Schmid 介绍上下文工程的文章成为 Hacker News 榜首,还登上了知乎热搜榜。

人工智能(AI),如果可以像人类一样“思考”,或许能够帮助我们理解人类的思维方式,尤其是不同心理状态(如抑郁或焦虑)的人群如何做出决策,进而为人类健康研究提供一个新视角。
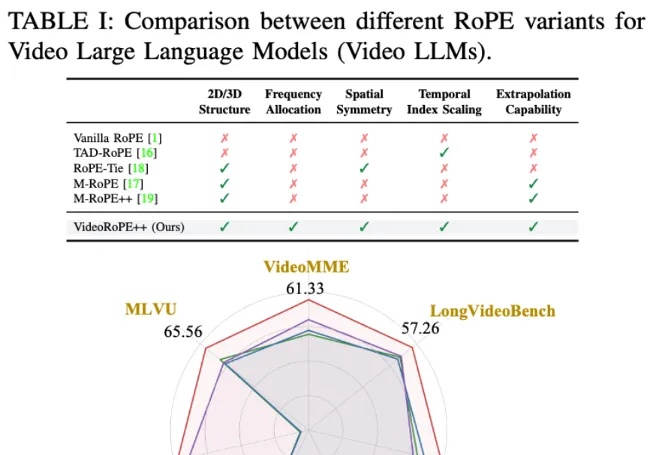
虽然旋转位置编码(RoPE)及其变体因其长上下文处理能力而被广泛采用,但将一维 RoPE 扩展到具有复杂时空结构的视频领域仍然是一个悬而未决的挑战。

DeepMind新研究揭示了当与推理无关的想法,被直接注入到模型的推理过程中时,它们却难以恢复,而且越大的模型越难恢复。
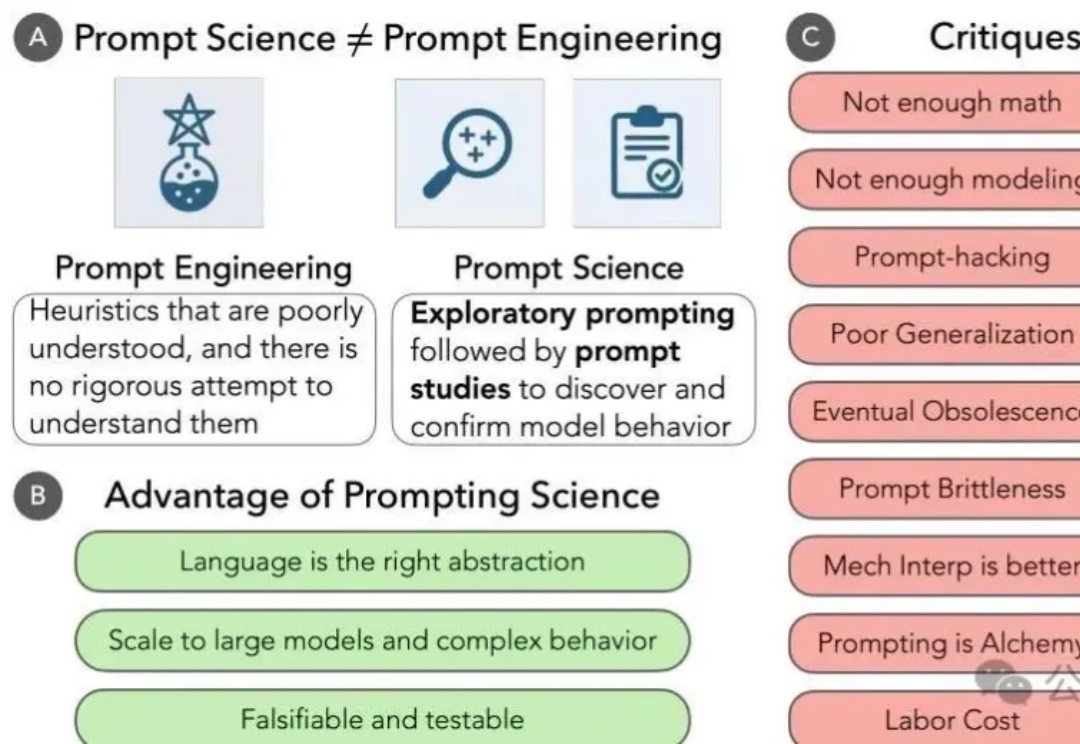
最近网上出现了一些很有趣的声音——"提示词已死"、"写提示词把自己写死了",这些文章认为随着模型变得越来越智能,精心设计提示词的时代已经过去了。但芝加哥大学的最新研究却给出了完全相反的结论:prompt不仅没有死,反而是理解大模型最重要的科学工具。
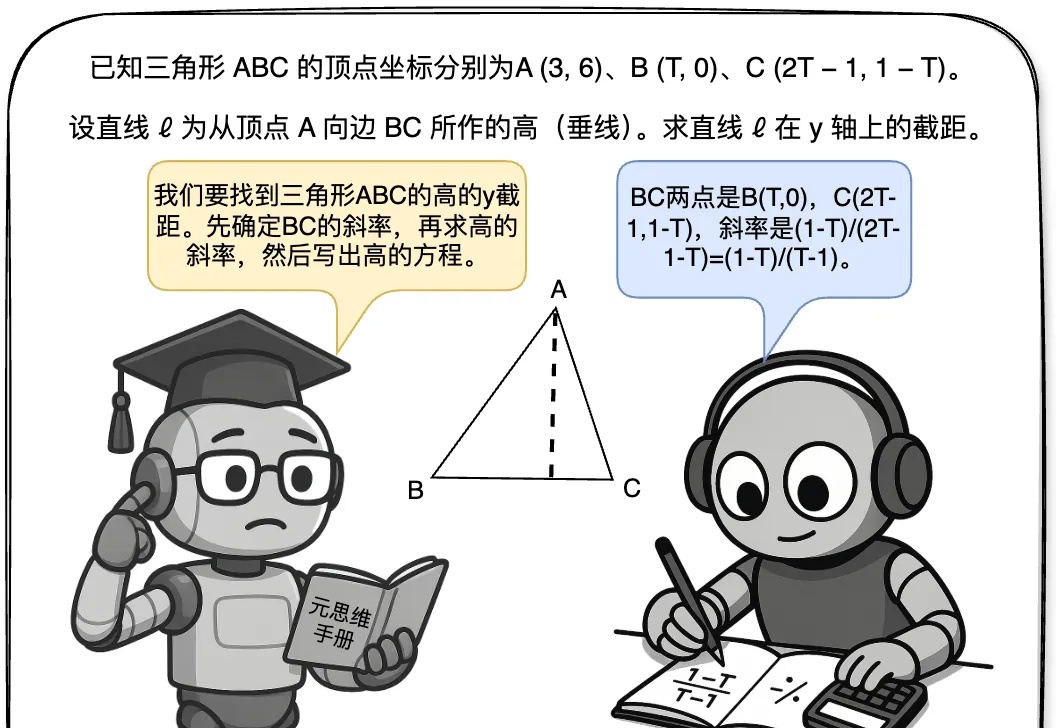
最近,关于大模型推理的测试时间扩展(Test time scaling law )的探索不断涌现出新的范式,包括① 结构化搜索结(如 MCTS),② 过程奖励模型(Process Reward Model )+ PPO,③ 可验证奖励 (Verifiable Reward)+ GRPO(DeepSeek R1)。