
下一个爱因斯坦,会是具身机器人吗?
下一个爱因斯坦,会是具身机器人吗?科学,真的在以它应有的速度不断进步吗? 一位顶尖的医学研究者,毕生致力于攻克癌症,他距离最终的答案或许只差一步。然而,那关键的一步,并非藏匿于医学典籍,而是隐藏在另一门看似毫不相干的学科——材料科学的最新突破之中。
来自主题: AI资讯
7881 点击 2025-07-10 12:07
 搜索
搜索
科学,真的在以它应有的速度不断进步吗? 一位顶尖的医学研究者,毕生致力于攻克癌症,他距离最终的答案或许只差一步。然而,那关键的一步,并非藏匿于医学典籍,而是隐藏在另一门看似毫不相干的学科——材料科学的最新突破之中。

暑假将至,很多家庭开始给孩子选择辅导班。然而,传统辅导班的弊端让人为难。

自适应语言模型框架SEAL,让大模型通过生成自己的微调数据和更新指令来适应新任务。SEAL在少样本学习和知识整合任务上表现优异,显著提升了模型的适应性和性能,为大模型的自主学习和优化提供了新的思路。

大模型“当面一套背后一套”的背后原因,正在进一步被解开。 Claude团队最新研究结果显示:对齐伪装并非通病,只是有些模型的“顺从性”会更高。
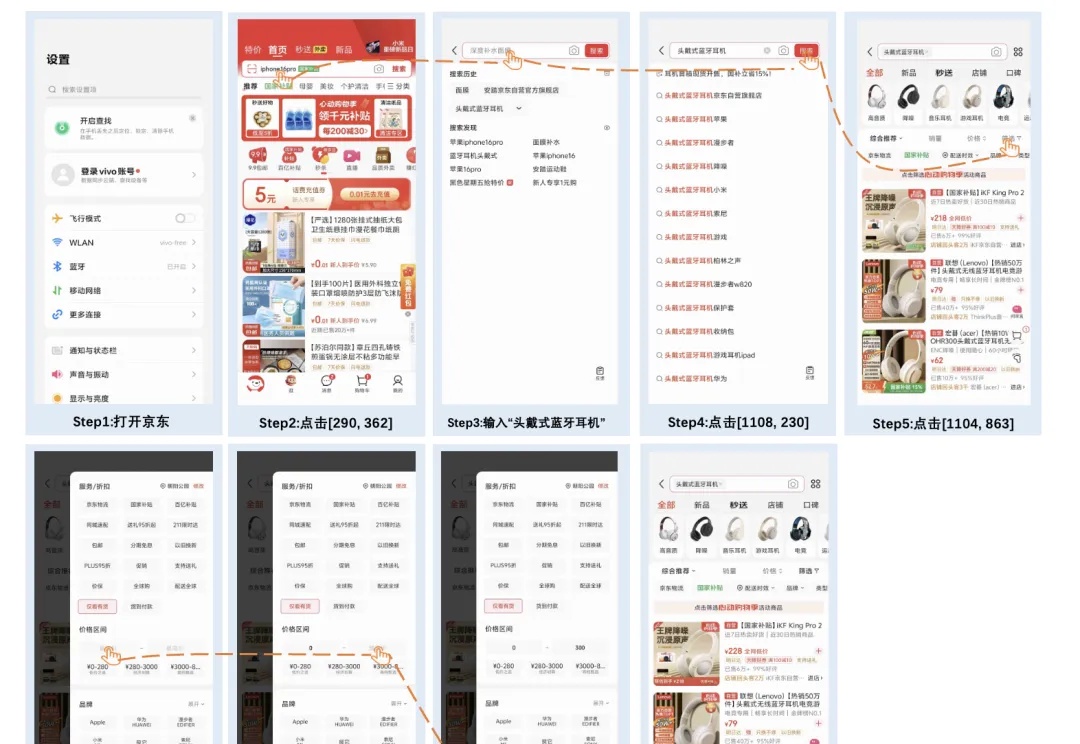
vivo AI Lab发布AI多模态新模型了,专门面向端侧设计,紧凑高效~

2025 年,大模型又一次刷新了人类的认知边界,AI 模拟高考成绩大幅跃升,已达到清华、北大的录取线。但另一方面,这也让人感到些许焦虑。
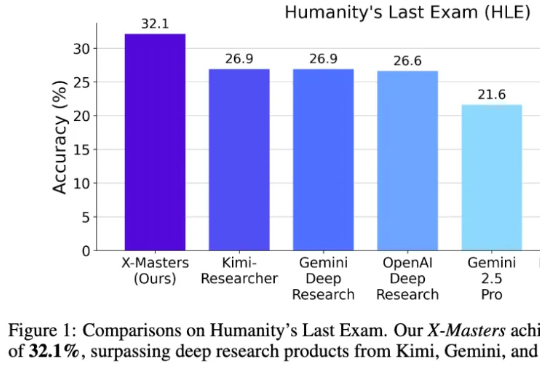
“人类最后的考试”首次突破30分,还是咱国内团队干的! 该测试集是出了名的超难,刚推出时无模型得分能超过10分。
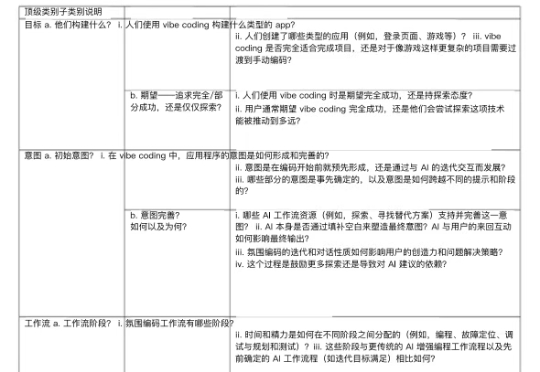
编者按:vibe coding不是编程的终点,而是Context Engineering驱动的协作智能的起点。那些能够最早理解并应用这种整合视角的人,将在下一轮技术变革中获得决定性优势。
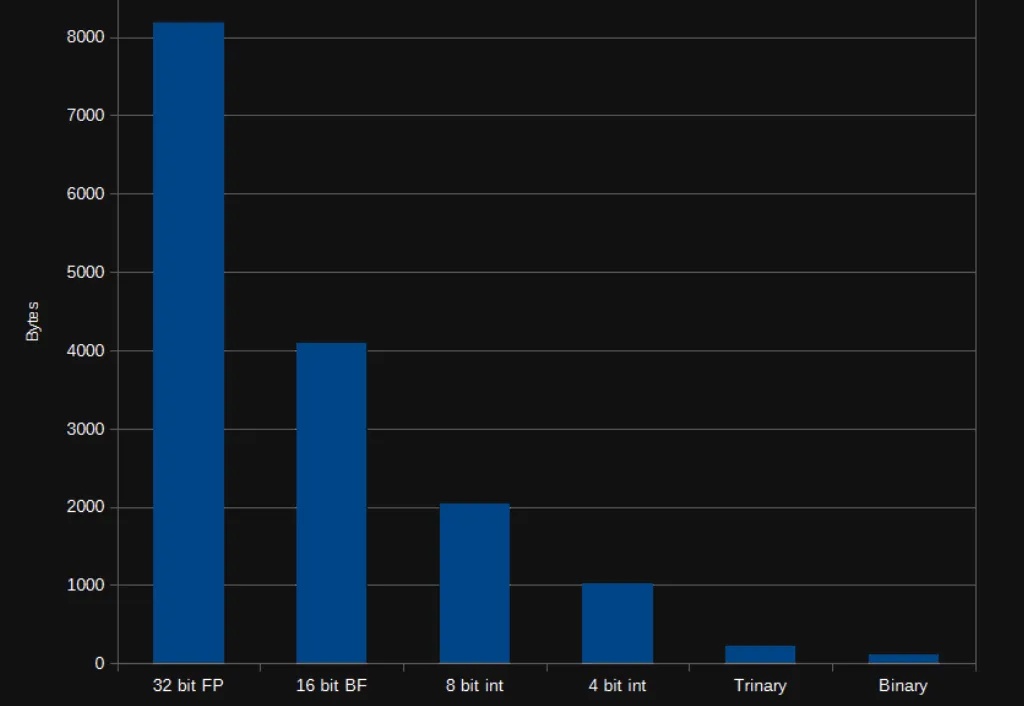
在 AI 领域,我们对模型的期待总是既要、又要、还要:模型要强,速度要快,成本还要低。但实际应用时,高质量的向量表征往往意味着庞大的数据体积,既拖慢检索速度,也推高存储和内存消耗。
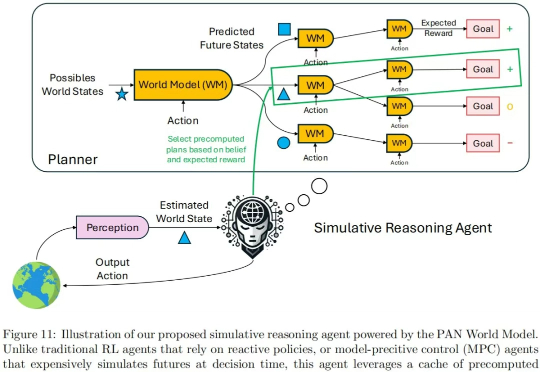
现在的世界模型,值得批判。 我们知道,大语言模型(LLM)是通过预测对话的下一个单词的形式产生输出的。由此产生的对话、推理甚至创作能力已经接近人类智力水平。