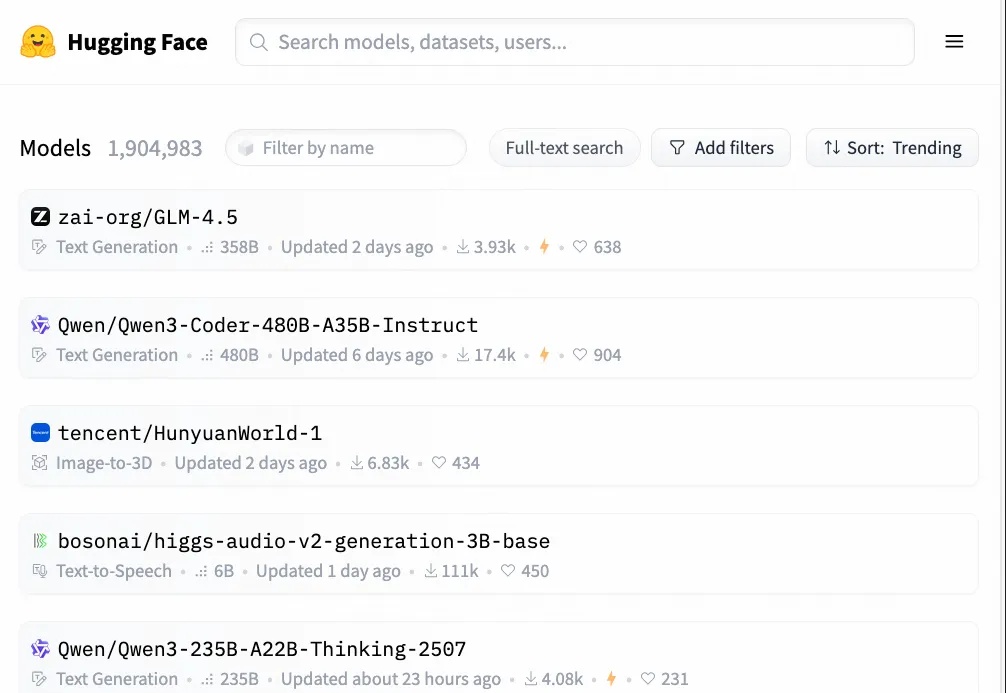
今天的开源世界,属于中国!
今天的开源世界,属于中国!家人们!燃起来了燃起来了! 今天,HuggingFace的开源大模型排行榜前10名中,竟有9个席位被中国模型占据!(深挖了一下,另外一位也是我们华人大神的项目)
来自主题: AI资讯
10499 点击 2025-07-31 10:53
 搜索
搜索
家人们!燃起来了燃起来了! 今天,HuggingFace的开源大模型排行榜前10名中,竟有9个席位被中国模型占据!(深挖了一下,另外一位也是我们华人大神的项目)
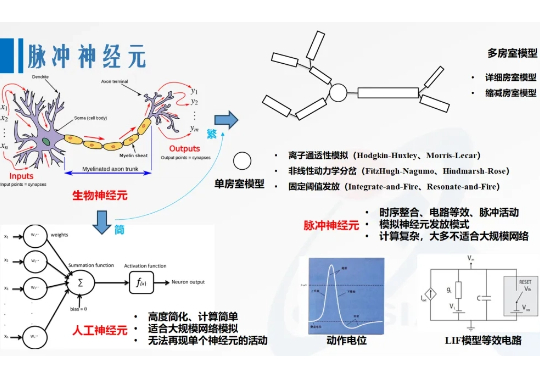
1997年,Wolfgang Maass于Networks of spiking neurons: The third generation of neural network models一文中提出,由脉冲神经元构成的网络——脉冲神经网络(SNN),能够展现出更强大的计算特性,会成为继人工神经网络后的“第三代神经网络模型”[6]。
近年来,OpenAI o1 和 DeepSeek-R1 等模型的成功证明了强化学习能够显著提升语言模型的推理能力。通过基于结果的奖励机制,强化学习使模型能够发展出可泛化的推理策略,在复杂问题上取得了监督微调难以企及的进展。

听说了吗,GPT-5这两天那叫一个疯狂造势,奥特曼怕不是真有些急了(doge)。
最近,一个长相酷似韩国影星河正宇的博主,在 TikTok 上发视频吐槽:「老婆总是喜欢乱 P 我睡觉的照片,咋整?」

太热了,实在太热了。 你能想象吗?一个AI行业展会,现在都有了一种明星演唱会的错觉。

这段时间国产 AI 模型非常热闹,各家都瞄着 Coding 和 Agent 场景,开源自己的最新模型。

WebAgent 续作《WebShaper: Agentically Data Synthesizing via Information-Seeking Formalization》中
Fireworks AI 作为新兴云服务商的一员,向开发者出租搭载 NVIDIA 芯片的服务器以运行人工智能模型。据两位知情人士透露,该公司正以 40 亿美元估值进行融资谈判,这一数字较一年前估值增长逾七倍。
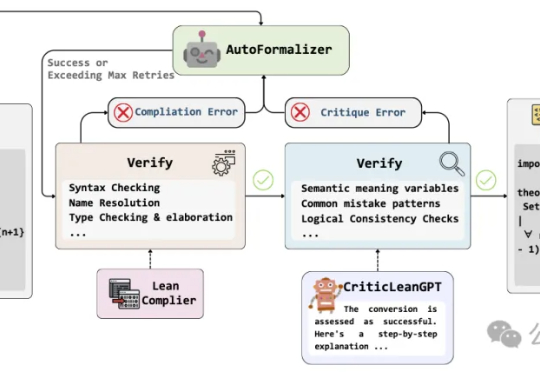
当人工智能已经能下围棋、写代码,如何让机器理解并证明数学定理,仍是横亘在科研界的重大难题。