均值至上假繁荣!北大新作专挑难题,逼出AI模型真本事
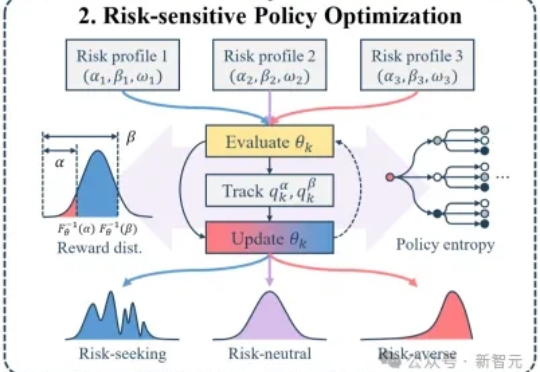
均值至上假繁荣!北大新作专挑难题,逼出AI模型真本事大模型后训练的痛点:均值优化忽略低概率高信息路径,导致推理能力停滞。RiskPO双管齐下,MVaR目标函数推导梯度估计,多问题捆绑转化反馈,实验中Geo3K准确率54.5%,LiveCodeBench Pass@1提升1%,泛化能力强悍。
来自主题: AI技术研报
8093 点击 2025-10-25 14:32
 搜索
搜索
大模型后训练的痛点:均值优化忽略低概率高信息路径,导致推理能力停滞。RiskPO双管齐下,MVaR目标函数推导梯度估计,多问题捆绑转化反馈,实验中Geo3K准确率54.5%,LiveCodeBench Pass@1提升1%,泛化能力强悍。
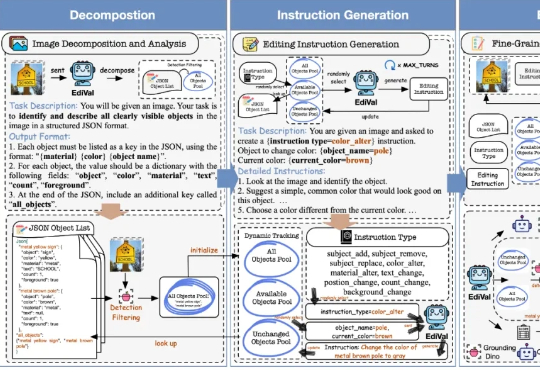
在 AIGC 的下一个阶段,图像编辑(Image Editing)正逐渐取代一次性生成,成为检验多模态模型理解、生成与推理能力的关键场景。我们该如何科学、公正地评测这些图像编辑模型?
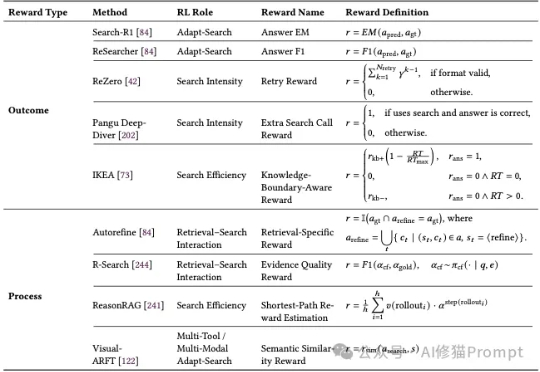
大型语言模型(LLM)本身很强大,但知识是静态的,有时会“胡说八道”。为了解决这个问题,我们可以让它去外部知识库(比如维基百科、搜索引擎)里“检索”信息,这就是所谓的“检索增强生成”(RAG)。

斯坦福等新框架,用在线强化学习让智能体系统“以小搏大”,领先GPT-4o—— AgentFlow,是一种能够在线优化智能体系统的新范式,可以持续提升智能体系统对于复杂问题的推理能力。

在这片喧嚣和迷雾之中,我们迫切需要一个清晰的导航图。而Jason Wei正是提供这份地图的最佳人选之一。他现任Meta超级智能实验室(Meta Super Intelligence Labs)的研究科学家,此前在OpenAI工作了两年,o1研发的主导者,更早之前是Google Brain的科学家。

全新AI工具EditVerse将图片和视频编辑整合到一个框架中,让你像P图一样轻松P视频。通过统一的通用视觉语言和上下文学习能力,EditVerse解决了传统视频编辑复杂、数据稀缺的问题,还能实现罕见的「涌现能力」。在效果上,它甚至超越了商业工具Runway,预示着一个创作新纪元的到来。

dots.ocr 支持多语言文档的解析,能够在单一模型中统一完成版面检测、文本识别、表格解析、公式提取等任务,并保持良好的阅读顺序。他们之所以在一个模型中完成这些任务,是因为他们相信这些任务之间可以相互促进,为彼此提供更多的 context,从而达到更高的性能上限。目前,该项目的 star 量已经超过了 5000。

10 月 23 日,一向不爱出风头的夸克上线了对话助手,可以让用户在一个 App 内即可完成信息查找、问题解答与任务处理,实现了 AI 搜索与对话的深度融合。其中一大亮点就是,该对话助手采用了 Qwen 最新闭源模型。至于是哪个型号、性能有多强,夸克卖了个关子,只透露比 Qwen3-Max 更进一步,在业界有绝对领先性。

浏览器「第三次世界大战」打响!OpenAI向谷歌扔下一个AI核弹,谁能掌握未来互联网之门的钥匙?互联网未来之战已然打响。OpenAI在所有人(尤其是山景城)最意想不到的时分,发布一款直指谷歌核心业务命脉的新产品。
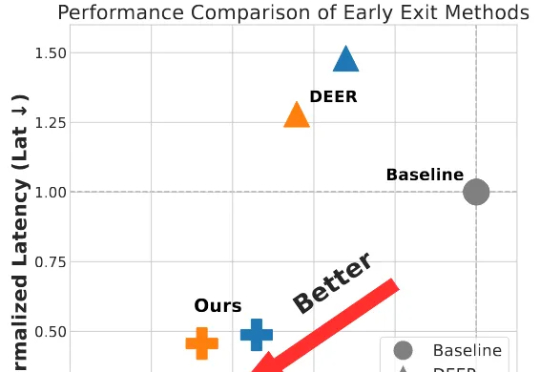
为破解大模型长思维链的效率难题,并且为了更好的端到端加速落地,我们将思考早停与投机采样无缝融合,提出了 SpecExit 方法,利用轻量级草稿模型预测 “退出信号”,在避免额外探测开销的同时将思维链长度缩短 66%,vLLM 上推理端到端加速 2.5 倍。