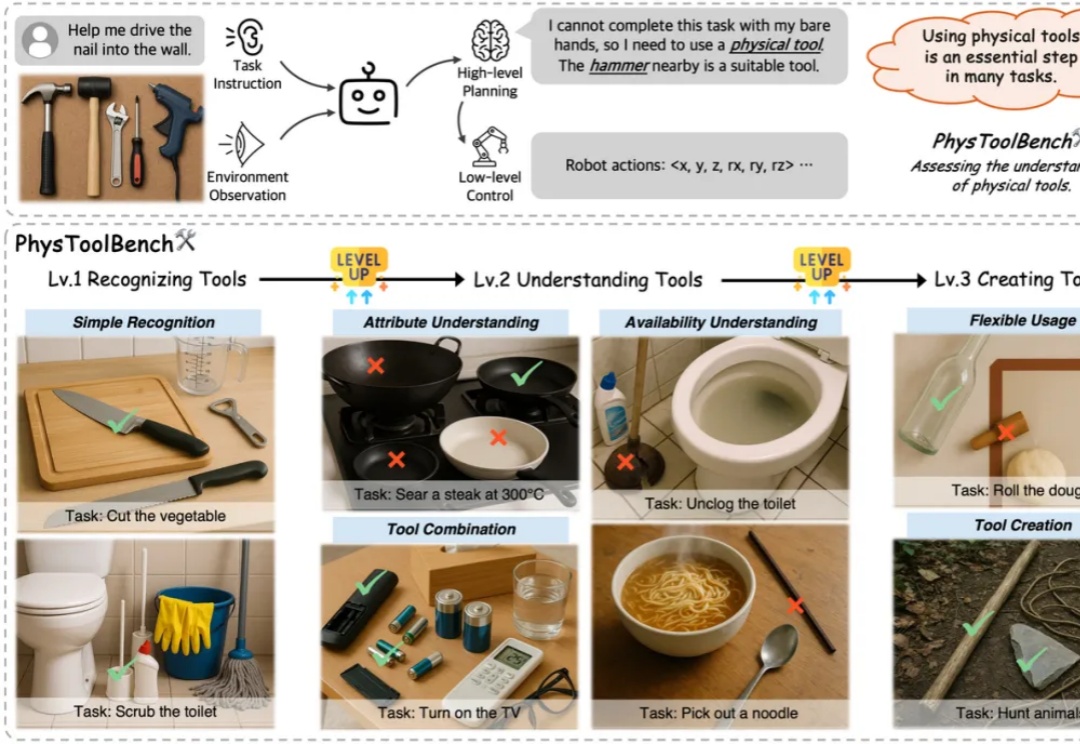
多模态大模型理解物理工具吗?PhysToolBench提出了衡量多模态大模型对物理工具理解的基准
多模态大模型理解物理工具吗?PhysToolBench提出了衡量多模态大模型对物理工具理解的基准人类之所以能与复杂的物理世界高效互动,很大程度上源于对「工具」的使用、理解与创造能力。对任何通用型智能体而言,这同样是不可或缺的基本技能,对物理工具的使用会大大影响任务的成功率与效率。
来自主题: AI技术研报
11344 点击 2025-11-05 09:57
 搜索
搜索
人类之所以能与复杂的物理世界高效互动,很大程度上源于对「工具」的使用、理解与创造能力。对任何通用型智能体而言,这同样是不可或缺的基本技能,对物理工具的使用会大大影响任务的成功率与效率。

同样是语义相似度结合时效性做rerank,指数衰减、高斯衰减、线性衰减怎么选? 假设你要在一个新闻应用中落地语义检索功能,让用户搜索雷军的投资版图盘点时,能自动关联顺为资本、小米战投等核心关联信息。

近期,慕尼黑大学团队推出Nicheformer,全球首个将单细胞分析与空间转录组学融合的大规模基础模型,由超1.1亿个细胞数据训练而来。这一成果被刊登在Nature子刊Nature Methods上,且团队已经将该模型开源。
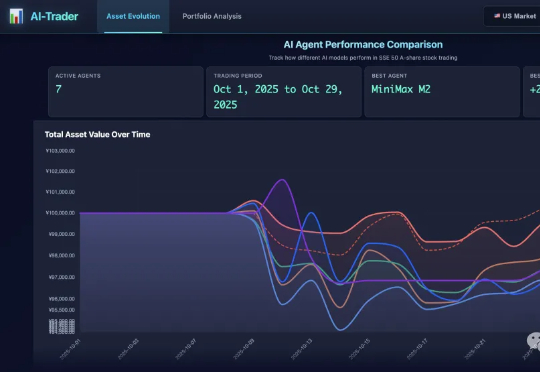
屠榜开源大模型的MiniMax M2是怎样炼成的?为啥M1用了Linear Attention,到了M2又换成更传统的Full Attention了? 面对现实任务,M2表现得非常扛打,在香港大学的AI-Trader模拟A股大赛中拿下了第一名,20天用10万本金赚了将近三千元。

半成品模型,已经刷下高难度数学推理测试AIME 25满分战绩。
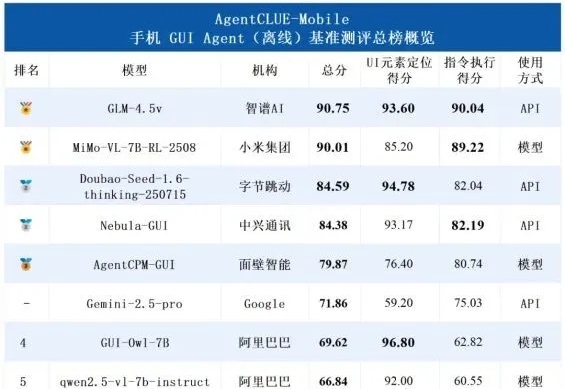
随着移动智能技术的飞速迭代,手机端聚合服务的AI“超级入口” 正成为行业竞争的新焦点——
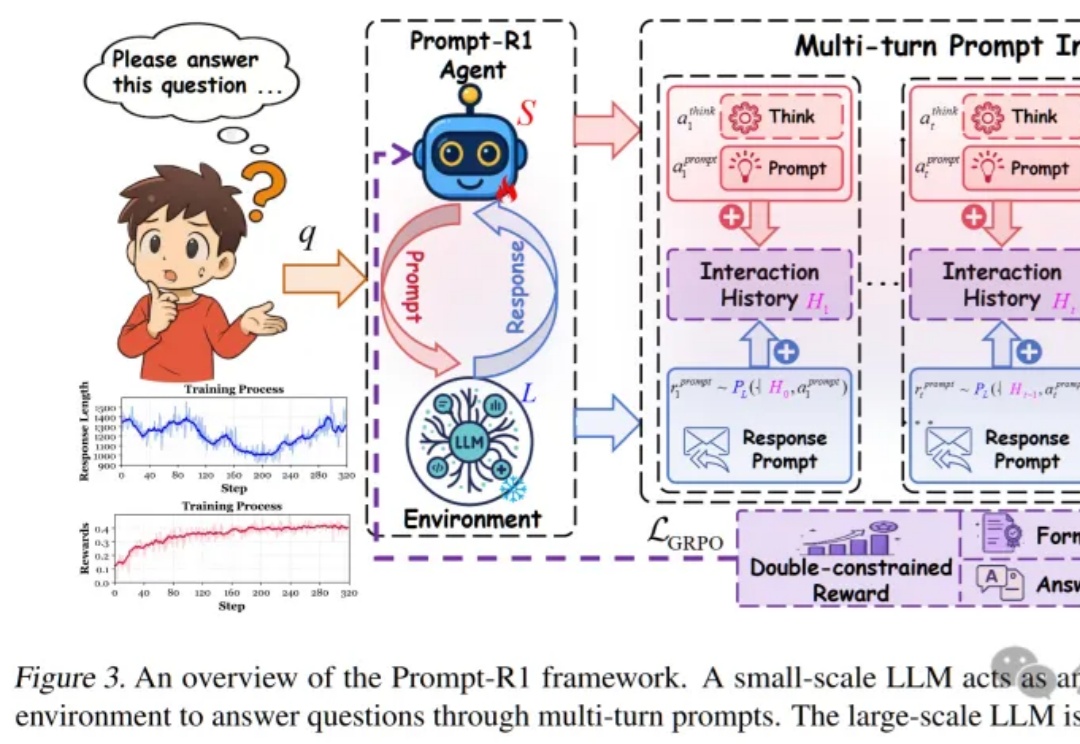
这篇论文提出了一种颠覆性的协作模式,即通过强化学习训练一个“小模型”作为智能代理(Agent),让它自动学会如何写出完美的Prompt,一步步引导任何一个“大模型”完成复杂推理,实现了真正的“AI指挥AI”。
大语言模型(LLM)的「炼丹师」们,或许都曾面临一个共同的困扰:为不同任务、不同模型手动调整解码超参数(如 temperature 和 top-p)。这个过程不仅耗时耗力,而且一旦模型或任务发生变化,历史经验便瞬间失效,一切又得从头再来。
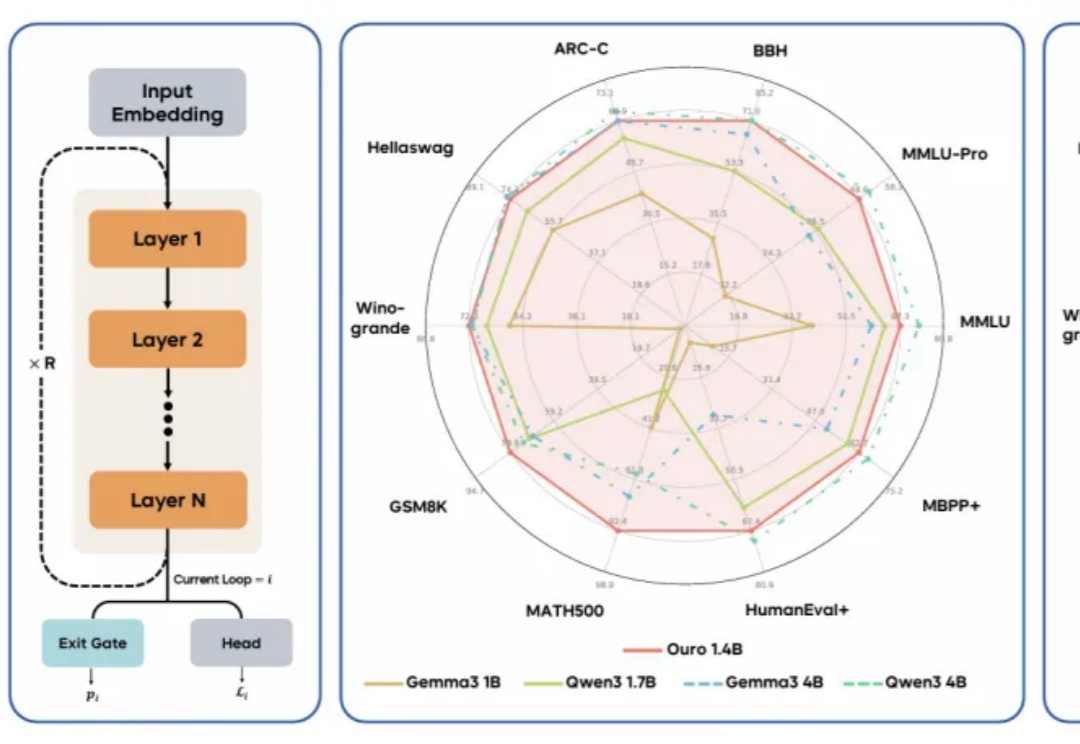
现代 LLM 通常依赖显式的文本生成过程(例如「思维链」)来进行「思考」训练。这种策略将推理任务推迟到训练后的阶段,未能充分挖掘预训练数据中的潜力。
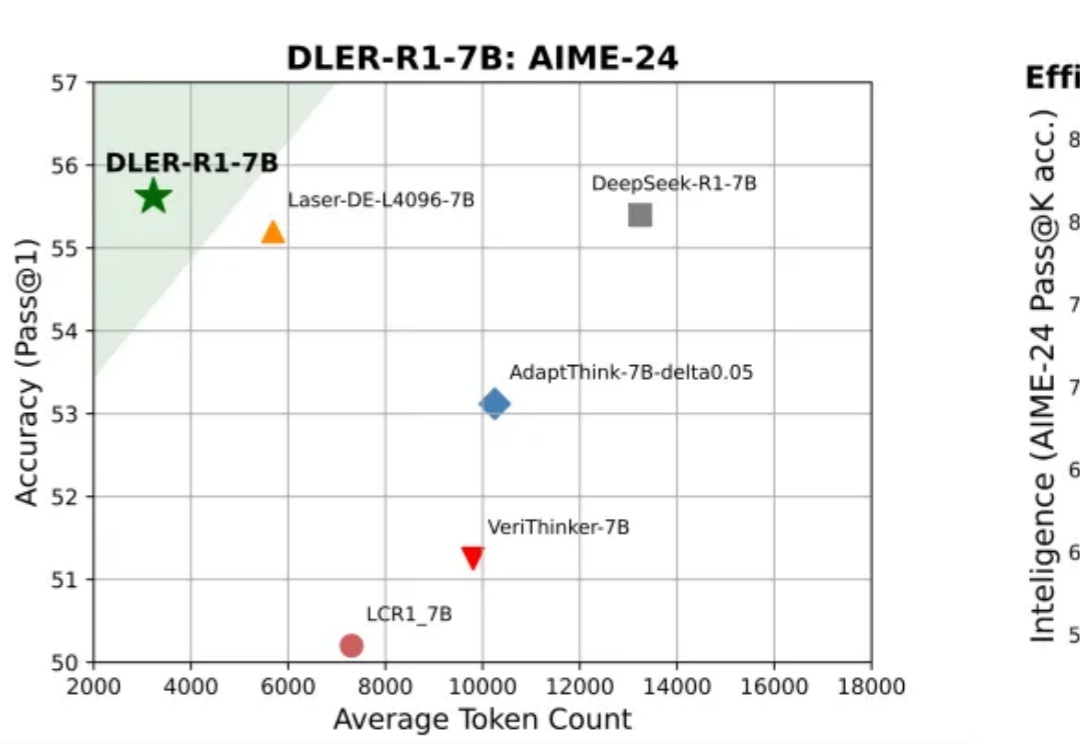
大模型推理到底要不要「长篇大论」?过去一年,OpenAI o 系列、DeepSeek-R1、Qwen 等一系列推理模型,把「长链思维」玩到极致:答案更准了,但代价是推理链越来越长、Token 消耗爆炸、响应速度骤降。