
首发 | 微面科技做出全球首个实时理解生理与情绪的基座模型,进一步布局硬件
首发 | 微面科技做出全球首个实时理解生理与情绪的基座模型,进一步布局硬件硬氪获悉,北京微面科技有限公司(以下简称“微面科技”)近日完成数百万美元融资,由顺为资本投资。
来自主题: AI资讯
10253 点击 2026-06-12 14:29
 搜索
搜索
硬氪获悉,北京微面科技有限公司(以下简称“微面科技”)近日完成数百万美元融资,由顺为资本投资。

硬氪获悉,具身智能世界模型公司「千诀科技」日前完成数亿元A轮融资,本轮由京铭资本领投,山东新动能、山东财金资本、元禾厚望、芯能创投、南创投、英诺天使基金、尚势资本、仁爱集团、玄素投资等机构共同投资,投资方阵容汇集了国家队、产业方、市场化基金及家族办公室。Maple Pledge枫承资本长期出任私募股权融资顾问。

上下文攻击、供应链渗透、AI社区崩溃……当大模型智能体真正进入开放世界,挑战远比想象中复杂。
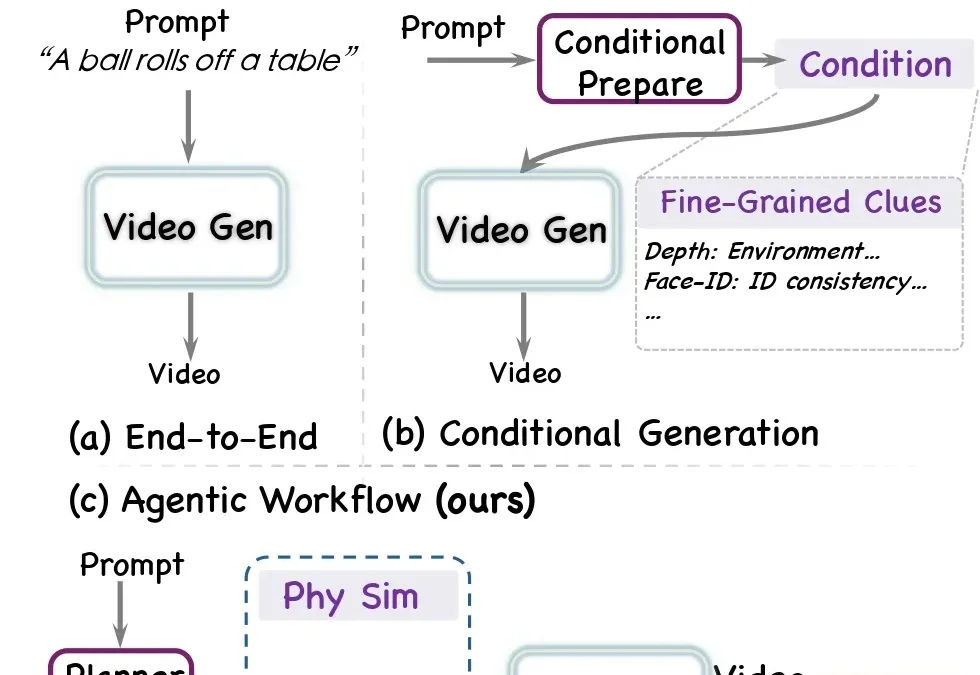
近年来,视频生成模型发展迅猛。从 Sora、Veo、Kling 到一系列开源视频生成模型,文生视频已经逼近真实影像的观感 —— 画面清晰、镜头流畅、风格可控,一句话就能生成一段观感不错的视频。
如果把一个商业化产品、一个科技公司的底层系统比作一棵树,那任意挑出一个项目,层层抽丝剥茧之后,你一定会发现,最早的年轮,一定与开源有关。

近日,Anthropic 发布了一篇引发广泛关注的文章《When AI builds itself》。文中披露了极其惊人的内部数据:截至 2026 年 5 月,Anthropic 超过 80% 的合并代码已由 Claude 编写,工程师的日常代码产出飙升了 8 倍;更令人瞩目的是,AI 智能体已经可以自主提出假设、执行长达数百小时的强化安全实验。

多模态长记忆在“看得准、找得到、想得清”三大环节的底层逻辑与工程避坑指南。
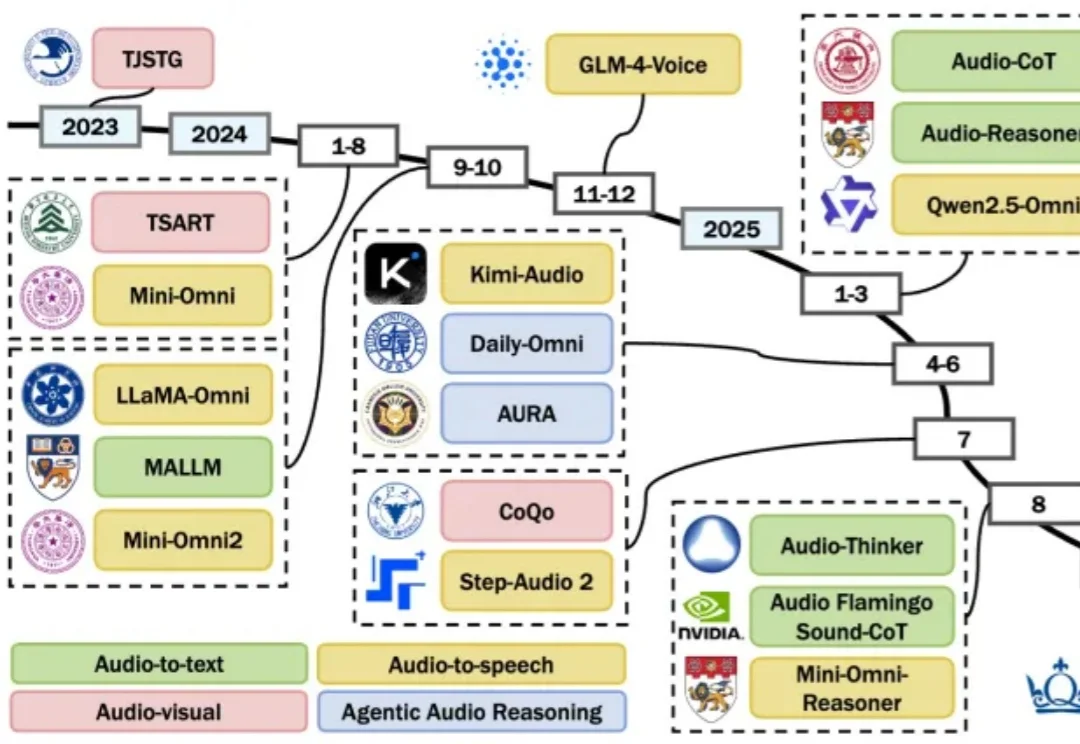
想象这样一个惬意的周末: 空调带来阵阵凉意,你靠在沙发上看书,突然耳边传来“哒哒哒”的小碎步声,接着,玄关门边传来了一阵清脆、略带急切的“呜呜”声,还伴随着爪尖轻轻扒拉木门的声响。
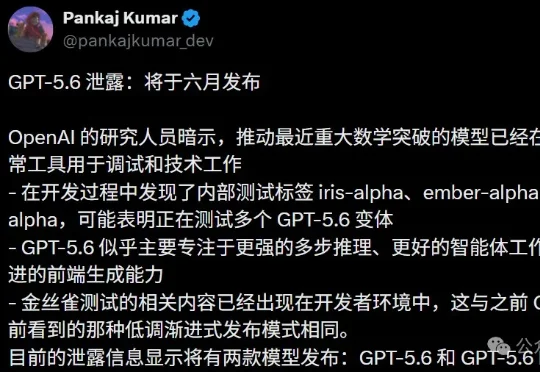
GPT-5.6本月上桌,agentic编码据称已反超Anthropic Mythos!三家旗舰模型撞进同一个6月,两大AI巨头同时冲刺IPO,奥特曼却在内部抛出了一个更大的变量:如果AI先学会自我改进,上市反而不急。

刚刚,Google 甩出了 Gemini 3.5 Live Translate。这是它最新的语音对语音翻译模型,一句话概括:把「等你说完再翻」的老规矩,直接掀了。Google DeepMind 首席科学家 Jeff Dean 亲自发帖官宣,字里行间透着一股「二十年磨一剑」的底气: