
北航领衔发布300页代码智能综述:从基础模型到智能体,一次读懂Code LLM全景图
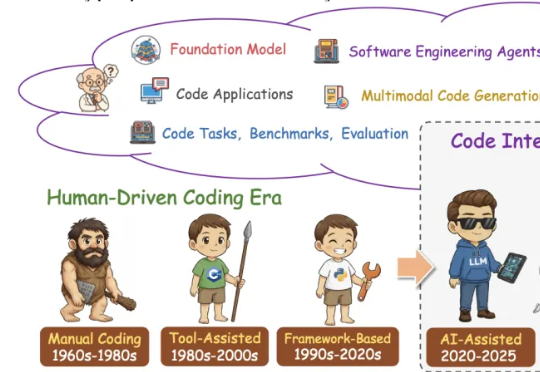
北航领衔发布300页代码智能综述:从基础模型到智能体,一次读懂Code LLM全景图这篇学术论长文由北京航空航天大学复杂关键软件环境全国重点实验室领衔。《From Code Foundation Models to Agents and Applications》一文是对过去几年代码智能领域的一次系统梳理:模型、任务、训练、智能体、安全与应用都被串联成了一条完整、连贯的技术链路。
来自主题: AI技术研报
9477 点击 2025-12-06 10:54








