
斯坦福×英伟达发布AI推理新范式,刷新了多领域SOTA
斯坦福×英伟达发布AI推理新范式,刷新了多领域SOTA斯坦福与英伟达联合发布重磅论文 TTT-Discover,打破「模型训练完即定型」的铁律。它让 AI 在推理阶段针对特定难题「现场长脑子」,不惜花费数百美元算力,只为求得一次打破纪录的极值。从重写数学猜想到碾压人类代码速度,这种「激进进化」正在重新定义机器发现的边界。
来自主题: AI技术研报
8167 点击 2026-01-26 14:23
 搜索
搜索
斯坦福与英伟达联合发布重磅论文 TTT-Discover,打破「模型训练完即定型」的铁律。它让 AI 在推理阶段针对特定难题「现场长脑子」,不惜花费数百美元算力,只为求得一次打破纪录的极值。从重写数学猜想到碾压人类代码速度,这种「激进进化」正在重新定义机器发现的边界。
近年来多模态大模型在视觉感知,长视频问答等方面涌现出了强劲的性能,但是这种跨模态融合也带来了巨大的计算成本。高分辨率图像和长视频会产生成千上万个视觉 token ,带来极高的显存占用和延迟,限制了模型的可扩展性和本地部署。

2026 年才开始,全球 AI 行业就迎来了第一个开年王炸。不是来自某个更大的模型参数,不是某家实验室刷新了榜单分数,而是一个看似不起眼、却迅速破圈的概念——Agent Skill。
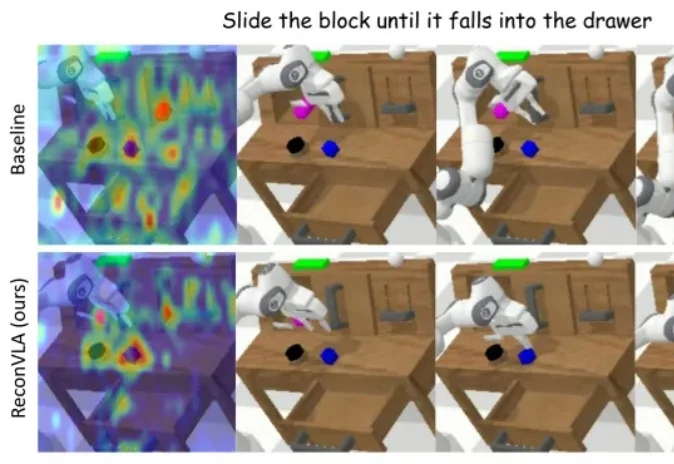
在长期以来的 AI 研究版图中,具身智能虽然在机器人操作、自动化系统与现实应用中至关重要,却常被视为「系统工程驱动」的研究方向,鲜少被认为能够在 AI 核心建模范式上产生决定性影响。
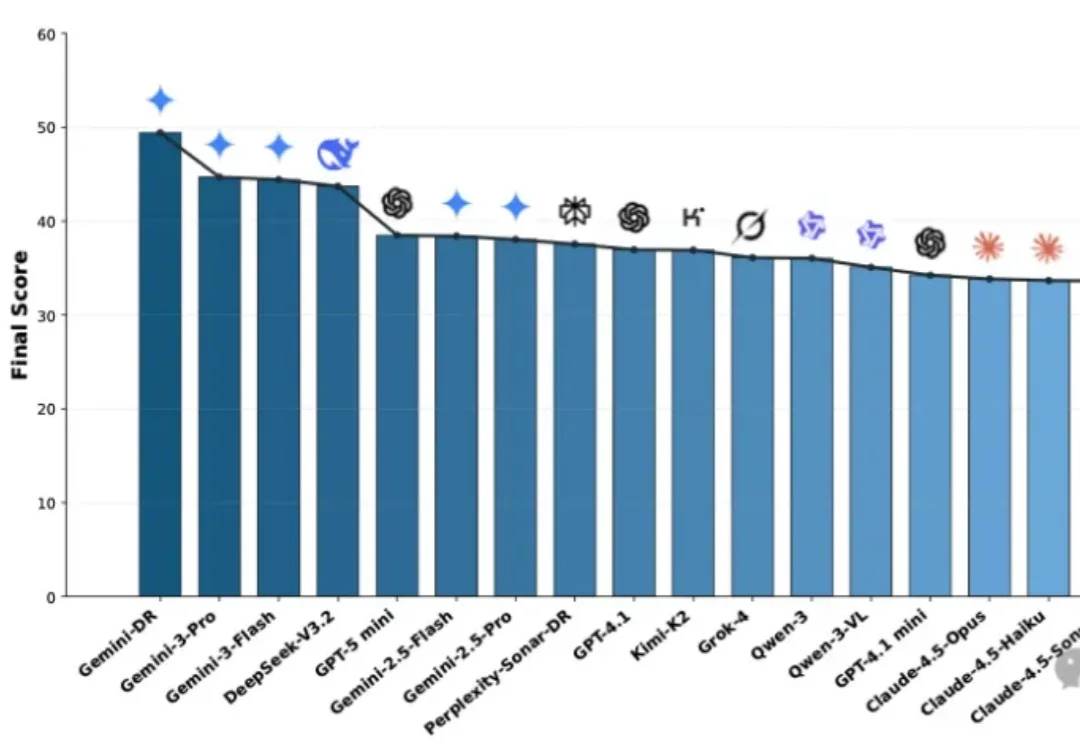
面对琳琅满目的Deep Research Agent(深度研究智能体),究竟该如何选型?本文基于OSU与Amazon最新发布的MMDR-Bench论文,为您提供一份经过严谨科学验证的“避坑指南”。结论先行:综合任务首选谷歌Gemini Deep Research,而涉及计算机科学与数据结构的硬核任务,GPT-5.2依然是专家首选。
提供软件支撑OpenAI 等公司语音、视频及实体 AI 模型的初创企业 LiveKit,在一轮融资中筹集了 1 亿美元,公司估值达 10 亿美元。LiveKit 的软件和网络运行着利用语音、视频以及所谓物理 AI(应用于机器人技术等任务)的人工智能模型。
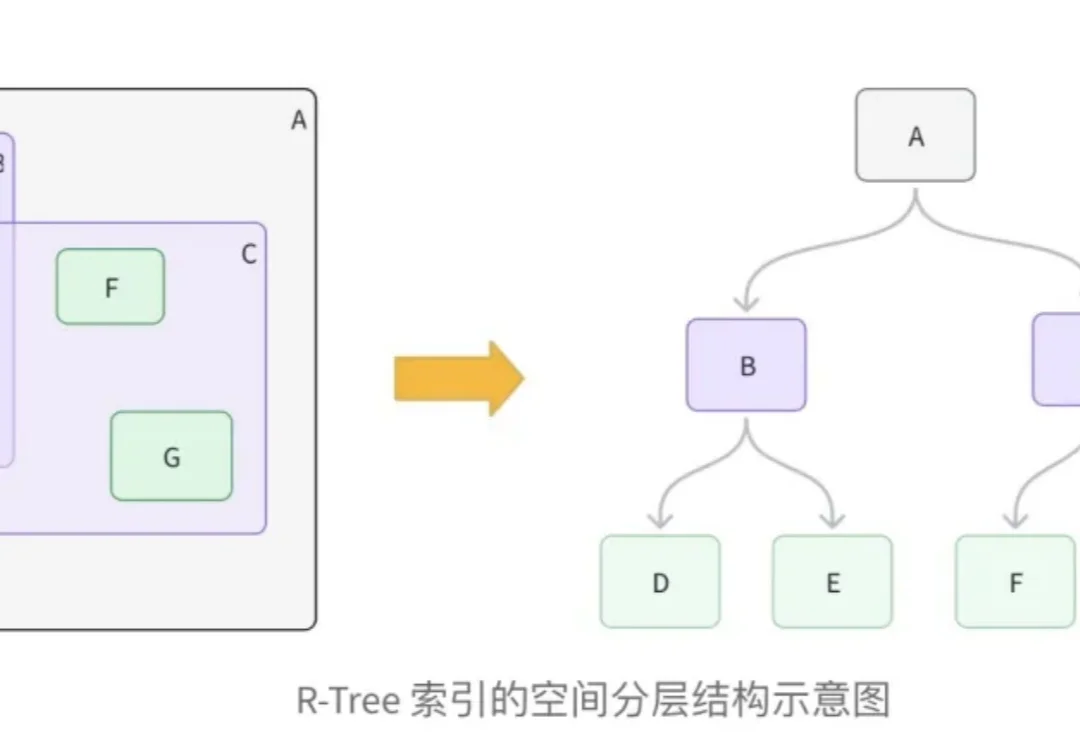
在向量数据库的工程实践中,处理多模态数据,特别是结合地理位置(LBS)与非结构化语义数据,一直是一个复杂的架构挑战。
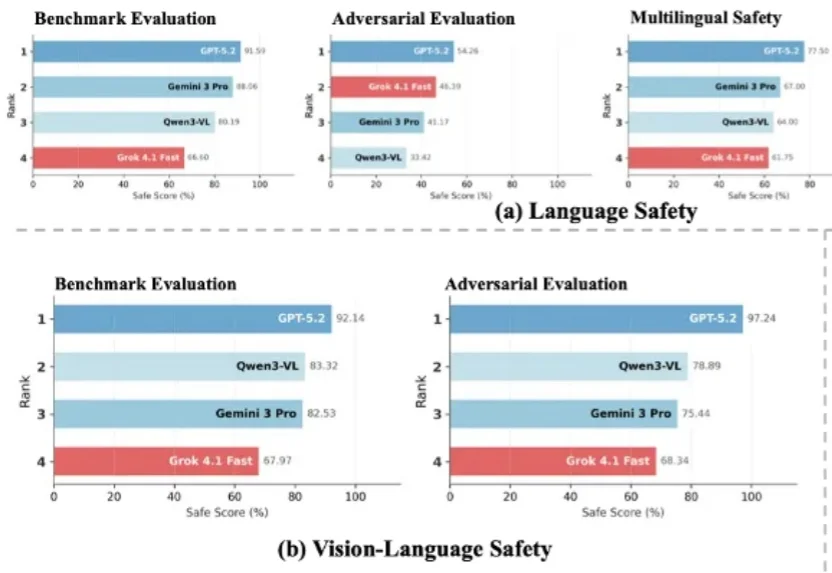
随着大语言模型加速迈向多模态与智能体形态,传统以单一维度为主的安全评估体系已难以覆盖真实世界中的复杂风险图景。在模型能力持续跃升的 2026 年,开发者与用户也愈发关注一个核心问题:前沿大模型的安全性,到底如何?
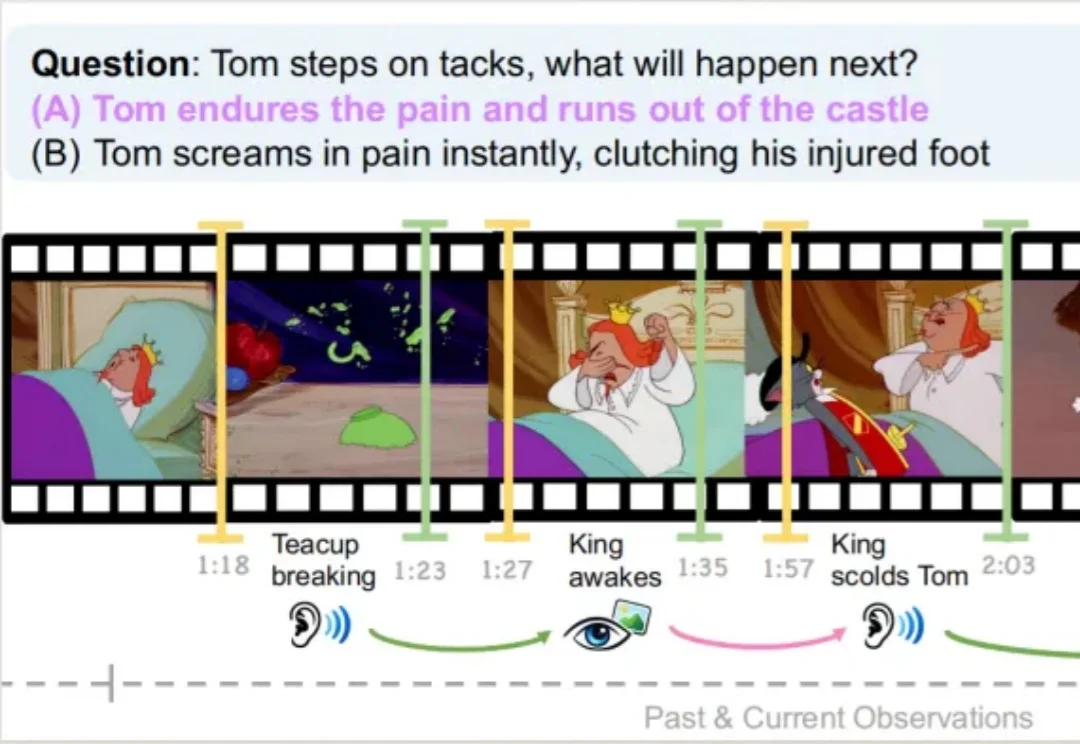
复旦大学、上海创智学院与新加坡国立大学联合推出首个全模态未来预测评测基准 FutureOmni,要求模型从音频 - 视觉线索中预测未来事件,实现跨模态因果和时间推理。

投资界获悉,阶跃星辰正式完成超50亿人民币B+轮融资,一举刷新过去12个月中国大模型赛道单笔最高融资纪录。参与机构包括上国投先导基金、国寿股权、浦东创投、徐汇资本、无锡梁溪基金、厦门国贸、华勤技术等产业投资人,腾讯、启明、五源等老股东进一步跟投。