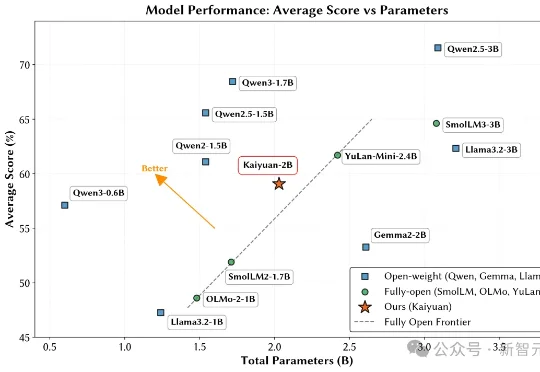
只靠国产算力预训练,稳!全流程开源,「开元」盛世真来了
只靠国产算力预训练,稳!全流程开源,「开元」盛世真来了鹏城实验室与清华大学PACMAN实验室联合发布了鹏城脑海‑2.1‑开元‑2B(PCMind‑2.1‑Kaiyuan‑2B,简称开元‑2B)模型,并以全流程开源的方式回应了这一挑战——从训练数据、数据处理框架、训练框架、完整技术报告到最终模型权重,全部开源。
来自主题: AI技术研报
9232 点击 2025-12-21 12:38
 搜索
搜索
鹏城实验室与清华大学PACMAN实验室联合发布了鹏城脑海‑2.1‑开元‑2B(PCMind‑2.1‑Kaiyuan‑2B,简称开元‑2B)模型,并以全流程开源的方式回应了这一挑战——从训练数据、数据处理框架、训练框架、完整技术报告到最终模型权重,全部开源。
依托腾讯自研大模型的底层能力,QQ浏览器不仅推出了“一句话接管任务”的QBot智能体,还全面实现了AI搜索、AI浏览、AI学习、AI办公等全场景覆盖。就在刚刚,它更是冲上了数据机构XSignal的多项权威榜单,在「AI Agent」赛道上,其相关数据表现已率先跑进行业前排:

具身智能通往通用性的征途,正被 “数据荒漠” 所阻隔。当模型在模拟器中刷出高分,却在现实复杂场景中频频 “炸机” 时,行业开始反思:我们喂给机器人的数据,是否真的包含人类操作的精髓?近日,深度机智在以人类第一视角为代表的真实情境数据,筑牢物理智能基座,解决具身智能通用性难题的道路上又有重要举措。

科技赛道从不缺“造梦者”,但能精准击中行业痛点的“破局者”往往寥寥。

OpenAI 聘请了英国前财政大臣乔治·奥斯本,领导一项与各国政府合作建设人工智能基础设施的新计划。随着各国竞相获取运行先进人工智能系统所需的数据中心和计算能力,OpenAI 选择了一位备受瞩目的政治人物来推动此事。
今天聊一聊我们如何做高质量rerank。
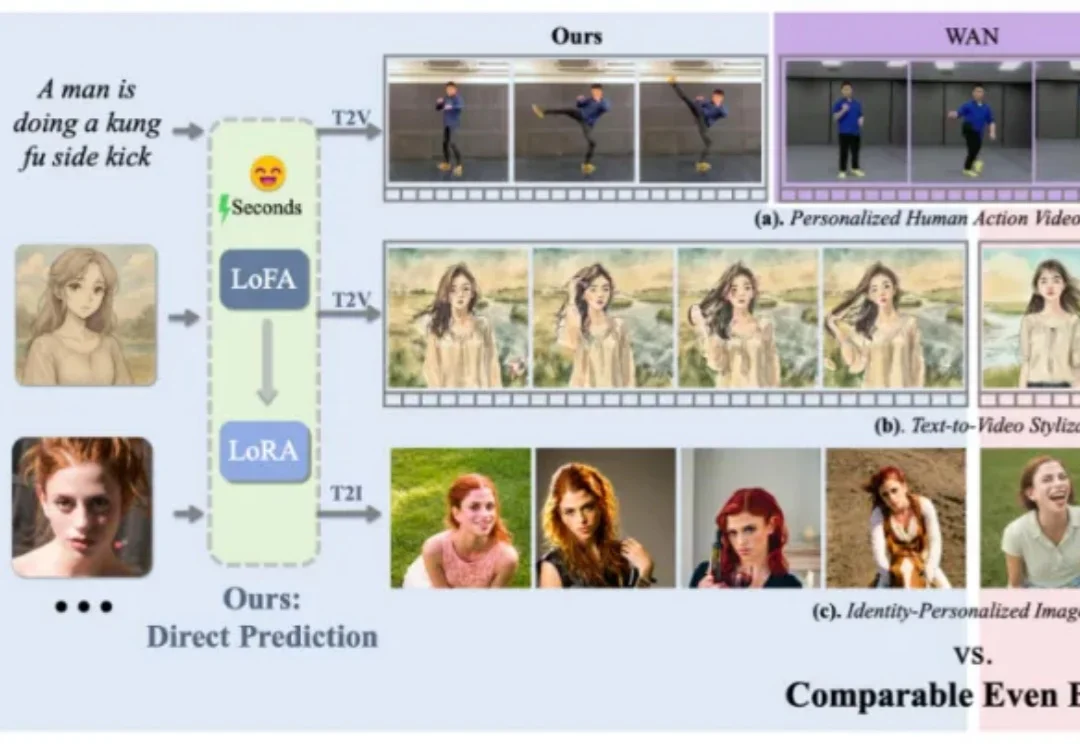
在个性化视觉生成的实际应用中,通用视觉基础模型的表现往往难以满足精准需求。为实现高度定制化的生成效果,通常需对大模型进行针对性的自适应微调,但当前以 LoRA 为代表的主流方法,仍受限于定制化数据收集与冗长的优化流程,耗时耗力,难以在真实场景中广泛应用。
独家获悉,腾讯近期完成了一次组织调整,正式新成立AI Infra部、AI Data部、数据计算平台部。 12月17日下午发布的内部公告中,腾讯表示,Vinces Yao将出任“CEO/总裁办公室”首席AI科学家,向腾讯总裁刘炽平汇报;他同时兼任AI Infra部、大语言模型部负责人,向技术工程事业群总裁卢山汇报。

做PPT、跑数据、写报告,一路从思考到交付!这只「办公小浣熊」正在告诉你,AI真正的灵魂,原来是把人从工作里解放出来。

生成式模型正在成为机器人和具身智能领域的重要范式,它能够从高维视觉观测中直接生成复杂、灵活的动作策略,在操作、抓取等任务中表现亮眼。但在真实系统中,这类方法仍面临两大「硬伤」:一是训练极度依赖大规模演示数据,二是推理阶段需要大量迭代,动作生成太慢,难以实时控制。