
Agent爆火前夜,华为存储连发两道“硬菜”:让智能体有粮可吃、有忆可循
Agent爆火前夜,华为存储连发两道“硬菜”:让智能体有粮可吃、有忆可循AI下半场拼的是数据。
来自主题: AI资讯
7820 点击 2026-03-20 10:22
 搜索
搜索
AI下半场拼的是数据。

Agnes AI近日披露了一组新的业务数据:全球用户规模已突破700万,年度经常性收入(ARR)接近2000万美元,并于去年底完成千万美元级融资。据公司方面透露,Agnes目前正在推进新一轮融资,目标估值约2亿美元,以持续投入核心技术研发并推动全球市场扩展。
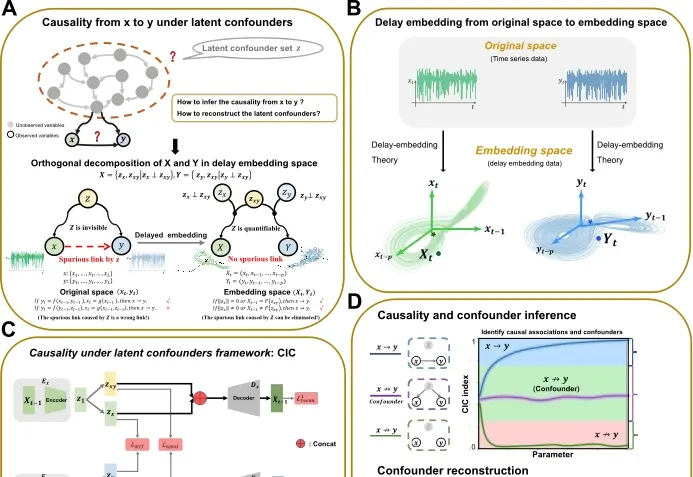
从观测时间序列数据中准确识别因果关系,是生命科学、地球科学、经济学以及人工智能等诸多领域的核心科学问题。尤其在复杂生物系统中,基因、蛋白质和代谢物之间高度耦合,并常常受到大量不可观测因素的干扰——这些「隐形混杂」无法被直接测量,却会严重误导因果推断结果,产生虚假的因果关联。

2025 年 1 月,特朗普在白宫亲自站台,宣布了一个号称“史上最大 AI 基础设施项目”的宏伟计划。OpenAI 联合软银、甲骨文和阿布扎比主权基金 MGX,组建了一家名为 Stargate LLC 的合资公司,承诺在四年内向美国 AI 基础设施投入 5,000 亿美元。

当LeCun和李飞飞各自拿下10亿美元押注世界模型时,一个更底层的问题浮出水面:谁来为Physical AI提供真正能用的数据?Ropedia给出的答案,不是更多视频,而是一部结构化的、来自真实世界的「经验百科全书」。
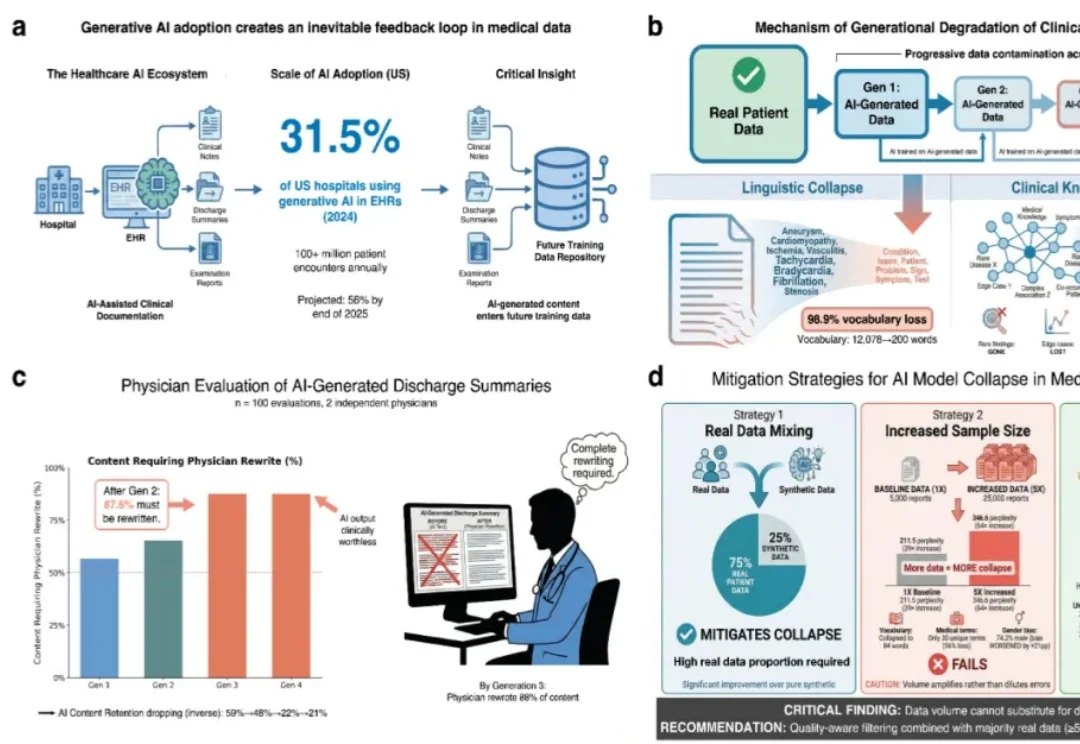
随着生成式人工智能在医疗领域的加速渗透,越来越多的病历、影像报告及各类临床文本正逐步纳入 AI 参与生成的范畴。这一旨在提升医疗效率的技术革新背后,潜藏着威胁诊断安全性的深层隐患。

达人营销的新「解答」。 👦🏻 作者: 镜山 🥷 编辑: Koji 🧑🎨 排版: NCon 达人营销一直以来都不是一件「轻易完成」的事情,如果只是找几个博主,谈好价格,内容发出去,数据也还行。但一旦想
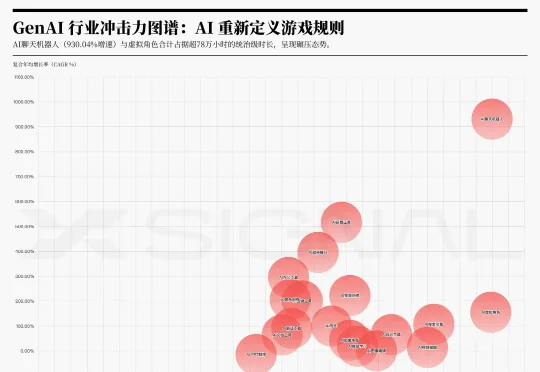
根据Xsignal AI Holo(AI全息)数据库数据显示,2026年初的AI细分行业数据,如果说“活跃用户量”代表了用户的使用意愿,那么“使用时长”则揭示了真实的市场依存度。基于这两项指标的交叉分析,市场已出现严重的结构性分化:
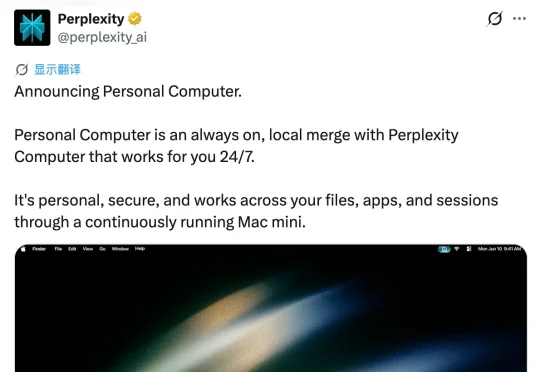
3 月 12 日凌晨,Perplexity 在旧金山 North Beach 一座改建自教堂的场地里,开了首届 Ask 2026 开发者大会,发布了 Personal Computer(个人电脑)。Personal Computer 是在此基础上往前迈了一大步。它运行在你自备的 Mac mini 上,24 小时不间断地访问本地文件、应用和会话记录,把云端的推理能力和本地数据的访问权限真正打通。
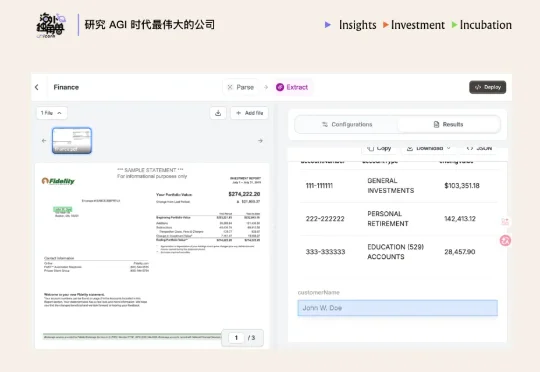
Reducto 在去年 6 个月内接连完成分别由 Benchmark 与 a16z 领投的两轮融资,估值翻了 3 倍,达到 6 亿美元。我们认为,Reducto 切中了 AI 应用走向生产环境过程中的“精确数据摄取”瓶颈。