当LLM学会左右互搏,基础模型或将迎来集体进化
当LLM学会左右互搏,基础模型或将迎来集体进化进入现今的大模型 (LLM) 时代,又有研究者发现了左右互搏的精妙用法!近日,加利福尼亚大学洛杉矶分校的顾全全团队提出了一种新方法 SPIN(Self-Play Fine-Tuning),可不使用额外微调数据,仅靠自我博弈就能大幅提升 LLM 的能力。
来自主题: AI资讯
11154 点击 2024-01-06 12:17
 搜索
搜索
进入现今的大模型 (LLM) 时代,又有研究者发现了左右互搏的精妙用法!近日,加利福尼亚大学洛杉矶分校的顾全全团队提出了一种新方法 SPIN(Self-Play Fine-Tuning),可不使用额外微调数据,仅靠自我博弈就能大幅提升 LLM 的能力。

这篇论文介绍了一项新的任务 —— 指向性遥感图像分割(RRSIS),以及一种新的方法 —— 旋转多尺度交互网络(RMSIN)。

几乎是和斯坦福“炒虾洗碗”机器人同一时间,谷歌DeepMind也发布了最新具身智能成果。

多模态大模型集成了检测分割模块后,抠图变得更简单了!
本文探讨了大模型套壳的问题,解释了大模型的内核和预训练过程。同时,介绍了“原创派”和“模仿派”两种预训练框架的差异,并讨论了通过“偷”聊天模型数据进行微调的现象。最后,提出了把“壳”做厚才是竞争力的观点。

10年前,「地震预测」在圈内还是如尼斯湖水怪一般的奇谈怪论,但机器学习的发展,已经让「准确预测地震」的可能性,又往前迈进了一步。

大模型固有的幻觉问题严重影响了LLM的表现。斯坦福最新研究利用维基百科数据训练大模型,得到的WikiChat成为首个几乎不产生幻觉的聊天机器人。

最近由UCSC的研究人员发表论文,证明大模型的零样本或者少样本能力,几乎都是来源于对于训练数据的记忆。
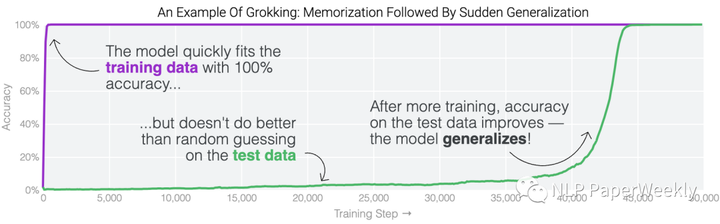
今天分享一篇符尧大佬的一篇数据工程(Data Engineering)的文章,解释了speed of grokking指标是什么,分析了数据工程
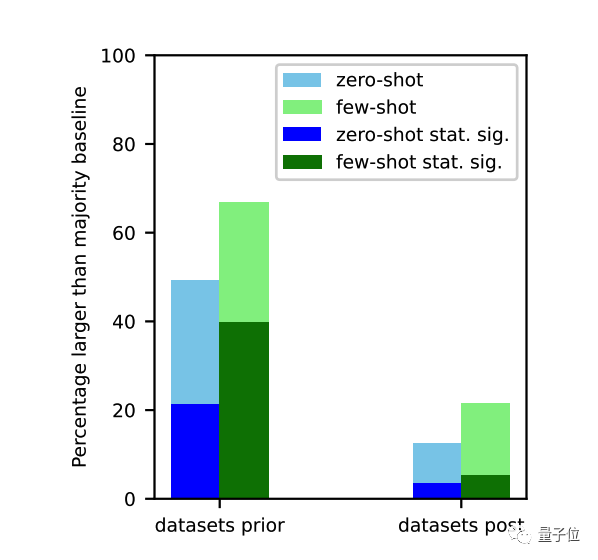
对于ChatGPT变笨原因,学术界又有了一种新解释。加州大学圣克鲁兹分校一项研究指出:在训练数据截止之前的任务上,大模型表现明显更好。