
谷歌豪掷6000万美元买「美版贴吧」数据,只为训AI模型!Altman竟是第三大股东
谷歌豪掷6000万美元买「美版贴吧」数据,只为训AI模型!Altman竟是第三大股东Reddit和OpenAI及谷歌,竟有着如此错综复杂的关系?最近,Reddit和谷歌双双官宣了一项6000万美元的合作协议,Reddit的数据将帮助谷歌训练AI模型。巧的是,Altman正是Reddit股东之一。
来自主题: AI资讯
9886 点击 2024-02-28 16:08
 搜索
搜索
Reddit和OpenAI及谷歌,竟有着如此错综复杂的关系?最近,Reddit和谷歌双双官宣了一项6000万美元的合作协议,Reddit的数据将帮助谷歌训练AI模型。巧的是,Altman正是Reddit股东之一。

近期,DiT(Diffusion Transformer)论文的作者谢赛宁在朋友圈分享了他对 Sora 的看法,其中核心资源的排序是——人才第一、数据第二、算力第三,其他都没有什么是不可替代的。

大模型的成功很大程度上要归因于 Scaling Law 的存在,这一定律量化了模型性能与训练数据规模、模型架构等设计要素之间的关系,为模型开发、资源分配和选择合适的训练数据提供了宝贵的指导。
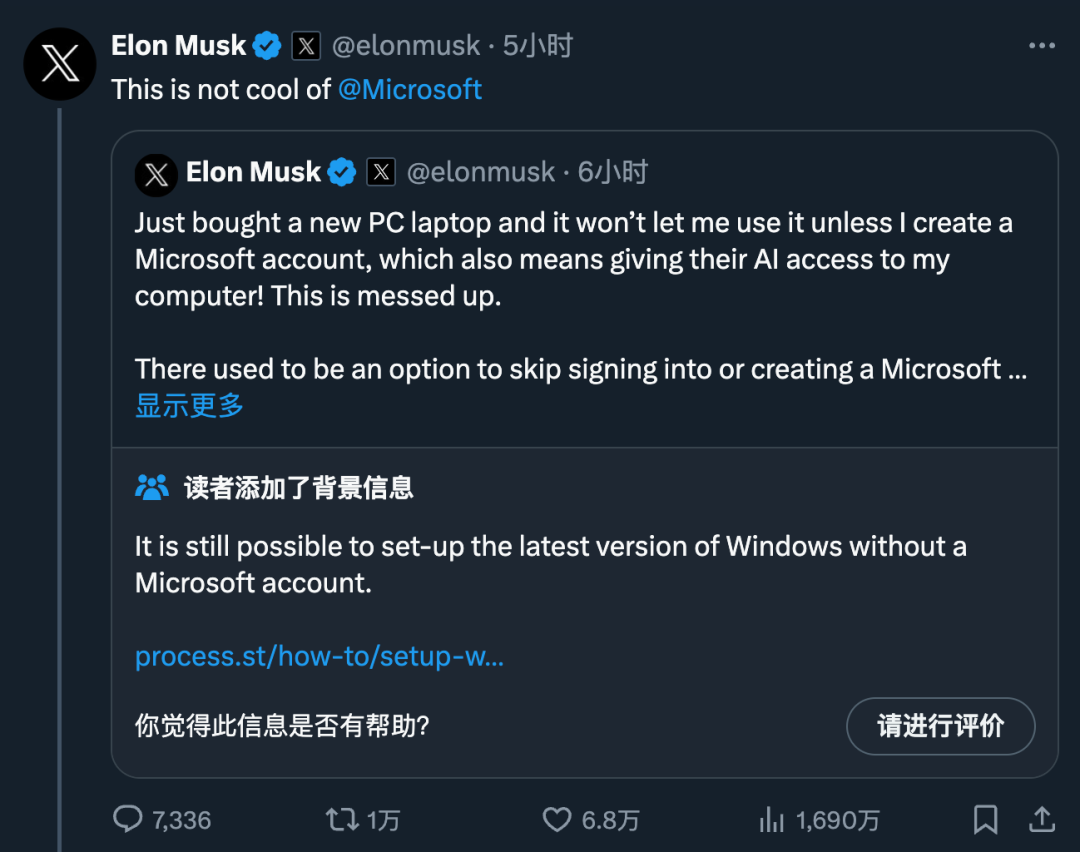
没有微软账户就用不了 Windows?马斯克怒斥大厂收集用户数据训练 AI。

好消息,好消息,真·Sora视频上新了!走过路过不要错过!

谷歌团队推出「通用视觉编码器」VideoPrism,在3600万高质量视频字幕对和5.82亿个视频剪辑的数据集上完成了训练,性能刷新30项SOTA。

终有一天,LLM可以成为人类数据专家,针对不同领域进行数据分析,大大解放AI研究员。

最近几年,基于 Transformer 的架构在多种任务上都表现卓越,吸引了世界的瞩目。使用这类架构搭配大量数据,得到的大型语言模型(LLM)等模型可以很好地泛化用于真实世界用例。
为何OpenAI只在TikTok上发布Sora新视频?AI专家猜测这是计划的一部分:创建病毒式视频、加水印、收集数据、添加RLHF、推出TikTok竞品……整套流程一气呵成。

Sora面对的挑战就像是需要处理和理解来自世界各地、不同设备拍摄的数以百万计的图片和视频。这些视觉数据在分辨率、宽高比、色彩深度等方面都存在差异。为了让Sora能够像人类大脑那样理解和生成这么丰富的视觉内容,OpenAI开发了一套将这些不同类型视觉数据转换为统一表示形式的方法。