
百万token上下文窗口也杀不死向量数据库?CPU笑了
百万token上下文窗口也杀不死向量数据库?CPU笑了“Claude 3、Gemini 1.5,是要把RAG(检索增强生成)给搞死了吗?”
来自主题: AI技术研报
4569 点击 2024-03-19 17:44
 搜索
搜索
“Claude 3、Gemini 1.5,是要把RAG(检索增强生成)给搞死了吗?”
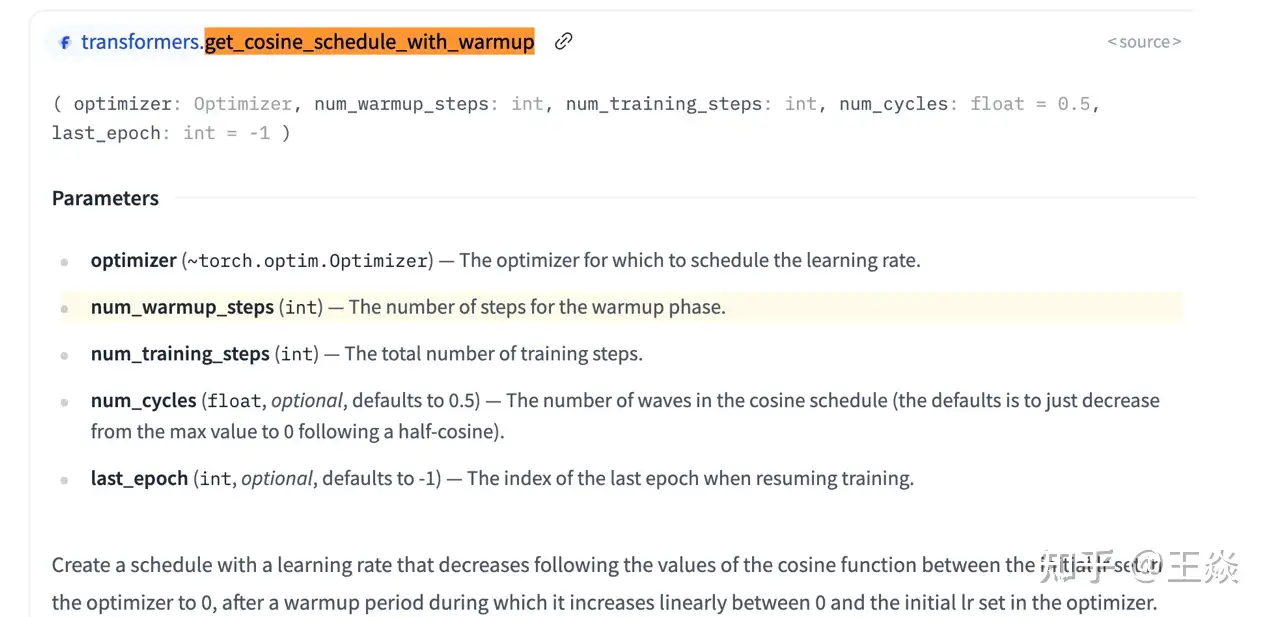
根据scaling law,模型越大,高质量数据越多,效果越好。 但还有一个很直观的情况,随着预训练样本的质量不断提升,训练手段的优化。新的模型,往往效果能轻松反超参数量两倍于它的模型。

深度学习模型因其能够从大量数据中学习潜在关系的能力而「彻底改变了科学研究领域」。然而,纯粹依赖数据驱动的模型逐渐暴露出其局限性,如过度依赖数据、泛化能力受限以及与物理现实的一致性问题。

不久前 OpenAI Sora 以其惊人的视频生成效果迅速走红,在一众文生视频模型中突出重围,成为全球瞩目的焦点。继 2 周前推出成本直降 46% 的 Sora 训练推理复现流程后,Colossal-AI 团队全面开源全球首个类 Sora 架构视频生成模型 「Open-Sora 1.0」,涵盖了整个训练流程,包括数据处理、所有训练细节和模型权重,携手全球 AI 热爱者共同推进视频创作的新纪元。

最近,OpenAI CTO Murati接受采访时,对Sora训练数据语焉不详、支支吾吾的表现,已经成了全网热议的话题。毕竟,要是一个处理不好,OpenAI就又要陷入巨额赔偿金的诉讼之中了。

Zephyr AI是一家总部位于美国德克萨斯州的医疗保健技术公司,致力于开发数据联合工具以及肿瘤和心血管代谢疾病领域的各种机器学习算法,尝试重塑药物发现和精准医疗。
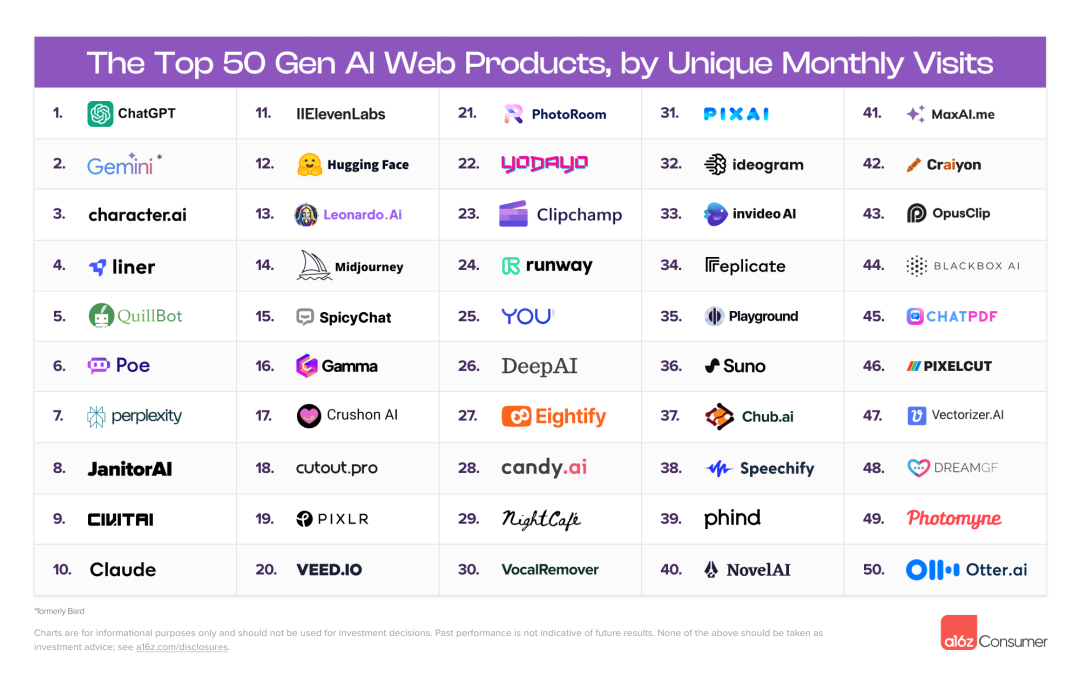
六个月前,a16z 对网络流量数据进行了一次深度挖掘,以便将真实数据与其他内容区分开来。根据每月访问量,a16z 对最受欢迎的生成式 AI 网络产品进行了排名,并发现了消费者实际使用这项技术的模式。
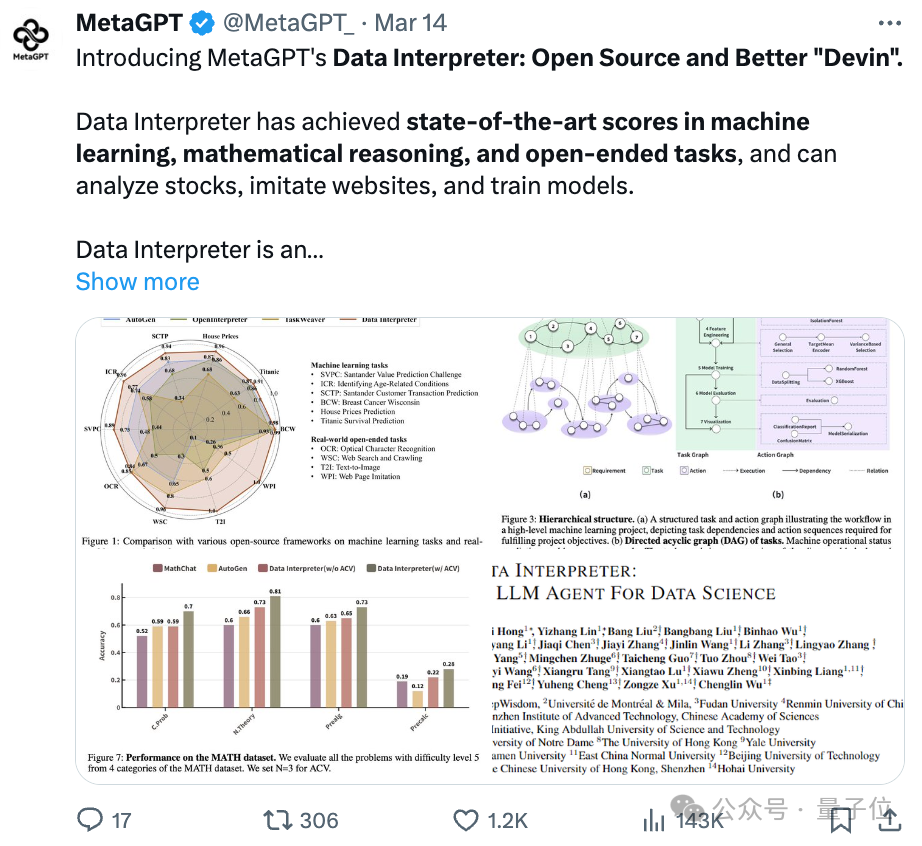
GitHub三万Star项目MetaGPT上新,号称是“开源Devin”——推出数据解释器(Data Interpreter),能够应对数据实时变化、任务之间复杂的依赖关系、流程优化需求以及执行结果反馈的逻辑一致性等挑战。

MIT新晋副教授何恺明,新作新鲜出炉:瞄准一个横亘在AI发展之路上十年之久的问题:数据集偏差。数据集偏差之战,在2011年由知名学者Antonio Torralba和Alyosha Efros提出——

TimesFM针对时序数据设计,输出序列长于输入序列,在1000亿时间点数据进行预训练后,仅用200M参数量就展现出超强零样本学习能力!