
腾讯在AI上做对了什么?有哪些困境?
腾讯在AI上做对了什么?有哪些困境?腾讯自发布一季报以来股价表现平平,虽有小涨,但未能创出新高。今年2月我在《Deepseek带来的价值重估 腾讯还能涨多久?》中说过,腾讯股价接下来能不能继续上涨,要看AI能带来多少实实在在的收入贡献。在一季报中,腾讯管理层虽然强调了AI对广告业务的提升,但未量化到具体的收入,也没有披露任何与AI相关的运营数据。
来自主题: AI资讯
9764 点击 2025-05-27 12:59
 搜索
搜索
腾讯自发布一季报以来股价表现平平,虽有小涨,但未能创出新高。今年2月我在《Deepseek带来的价值重估 腾讯还能涨多久?》中说过,腾讯股价接下来能不能继续上涨,要看AI能带来多少实实在在的收入贡献。在一季报中,腾讯管理层虽然强调了AI对广告业务的提升,但未量化到具体的收入,也没有披露任何与AI相关的运营数据。
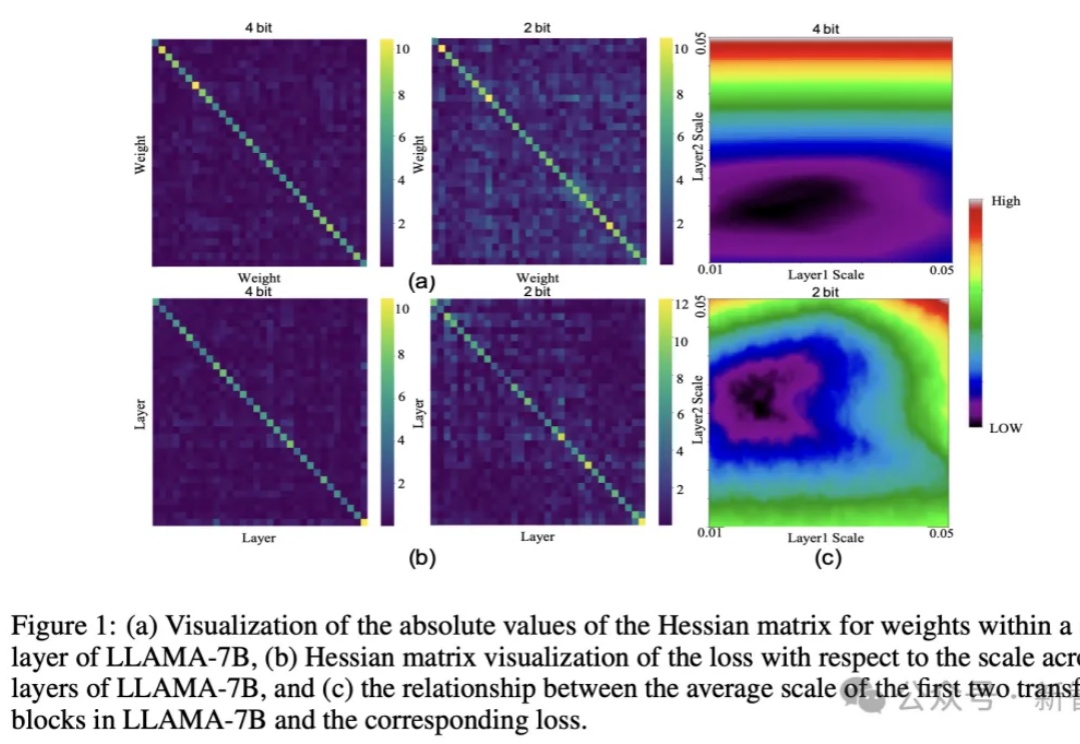
大模型巨无霸体量,让端侧部署望而却步?华为联手中科大提出CBQ新方案,仅用0.1%的训练数据实现7倍压缩率,保留99%精度。

2023年,业界还在卷Scaling Law,不断突破参数规模和数据规模时,微软亚洲研究院张丽团队就选择了另一条路径。
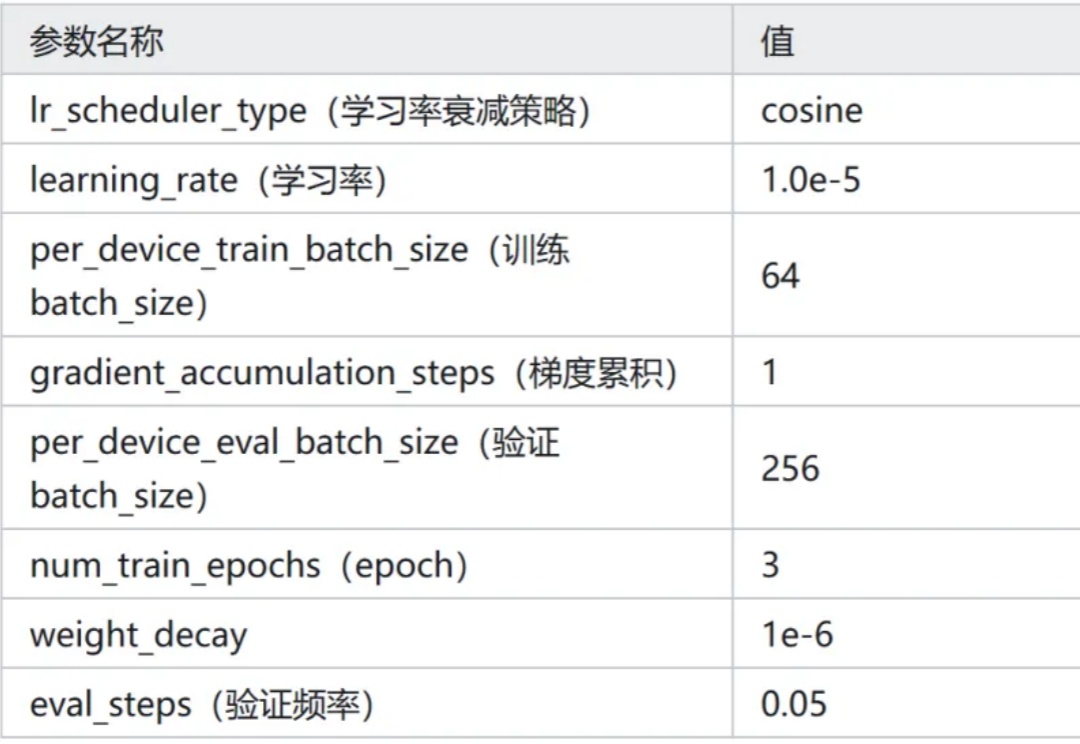
新增 Qwen3-0.6B 在 Ag_news 数据集 Zero-Shot 的效果。新增 Qwen3-0.6B 线性层分类方法的效果。

想象一下,你是一位金融分析师,面前堆满了数百页的季报、SEC文件和市场数据,你需要在明天早上交出一份全面的行业分析报告。
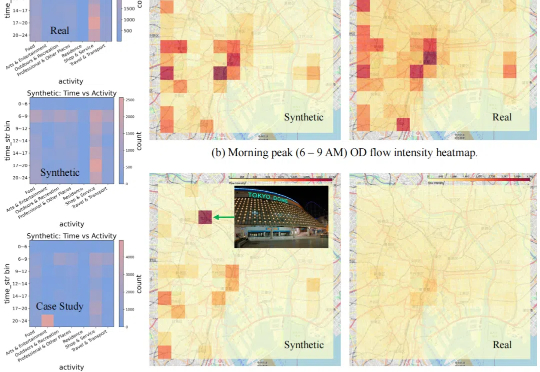
现有的数据合成方法在合理性和分布一致性方面存在不足,且缺乏自动适配不同数据的能力,扩展性较差。

而马毅是那类觉得不够的人,他于无声处开始提问:智能的本质是什么?自 2000 年从伯克利大学博士毕业以来,马毅先后任职于伊利诺伊大学香槟分校(UIUC)、微软亚研院、上海科技大学、伯克利大学和香港大学,现担任香港大学计算与数据科学学院院长。他和团队提出的压缩感知技术,到现在还在影响计算机视觉中模式识别领域的发展。
无需数据配对,文本嵌入也能互通?康奈尔重磅研究:所有模型都殊途同归。曾因llya离职OpenAI,在互联网上掀起讨论飓风的柏拉图表示假说提出:所有足够大规模的图像模型都具有相同的潜在表示。
该项目在今年1 月进一步扩大,Crusoe 与甲骨文签署了更大规模的租赁协议 ,新增 6 个数据中心,覆盖整个 1.2 吉瓦的场地,The Information 率先报道。该协议使甲骨文能为 OpenAI 提供的算力规模翻了两番,额外增加 30 万块 GPU。最初与 Blue Owl 成立的合资企业并不包含此次扩建计划。
不久前,麦炽科技与广大大在北京举办了一场“AI潮涌·文化共生”的行业论坛。Meta 大中华区行业副总经理 David Chen 陈晶在台上做了一场主题为《AI APP出海:产品、流量、合规三大决胜之道》的演讲。陈晶提到了很多Meta的数据,以及各种投放优势。比如,Meta平均每日活跃用户数为34.3亿,是目前全世界日活最高的平台。