
Transformer已死?DeepMind正在押注另一条AGI路线
Transformer已死?DeepMind正在押注另一条AGI路线借鉴人类联想记忆,嵌套学习让AI在运行中构建抽象结构,超越Transformer的局限。谷歌团队强调:优化器与架构互为上下文,协同进化才能实现真正持续学习。这篇论文或成经典,开启AI从被动训练到主动进化的大门。
来自主题: AI技术研报
10499 点击 2026-01-09 11:24
 搜索
搜索
借鉴人类联想记忆,嵌套学习让AI在运行中构建抽象结构,超越Transformer的局限。谷歌团队强调:优化器与架构互为上下文,协同进化才能实现真正持续学习。这篇论文或成经典,开启AI从被动训练到主动进化的大门。

近日,在与数学家Hannah Fry的对话中,DeepMind CEO Demis Hassabis回顾了AI在过去一年的飞跃式进展,他谈到了「参差智能」、持续学习、模型幻觉等迈向AGI过程中的关键挑战,并提到AGI带来的社会冲击可能是工业革命的10倍。

2025年底,最令人印象深刻的AI圈大事莫过于Gemini 3 Flash的发布。

近日,谷歌推出了一种全新的用于持续学习的机器学习范式 —— 嵌套学习,模型不再采用静态的训练周期,而是以不同的更新速度在嵌套层中进行学习,即将模型视为一系列嵌套问题的堆叠,使其能够不断学习新技能,同时又不会遗忘旧技能。
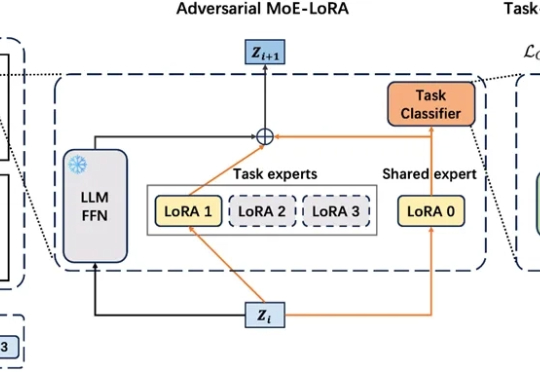
在工业级大语言模型(LLM)应用中,动态适配任务与保留既有能力的 “自进化” 需求日益迫切。真实场景中,不同领域语言模式差异显著,LLM 需在学习新场景合规规则的同时,不丢失旧场景的判断能力。这正是大模型自进化核心诉求,即 “自主优化跨任务知识整合,适应动态环境而无需大量外部干预”。

过去几年,大语言模型(LLM)的训练大多依赖于基于人类或数据偏好的强化学习(Preference-based Reinforcement Fine-tuning, PBRFT):输入提示、输出文本、获得一个偏好分数。这一范式催生了 GPT-4、Llama-3 等成功的早期大模型,但局限也日益明显:缺乏长期规划、环境交互与持续学习能力。
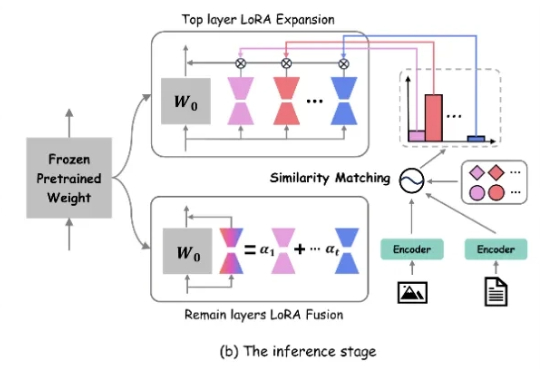
近年来,生成式 AI 和多模态大模型在各领域取得了令人瞩目的进展。然而,在现实世界应用中,动态环境下的数据分布和任务需求不断变化,大模型如何在此背景下实现持续学习成为了重要挑战

根据麻省理工学院NANDA 计划最新发布的报告显示,企业开展的生成式 AI 试点项目失败率高达 95%。但最先进的企业并未完全放弃这项技术,而是开始尝试能够持续学习并接受监督的自主 AI 系统。

持续适应性学习,即指适应环境并提升表现的能力,是自然智能与人工智能共有的关键特征。大脑达成这一目标的核心机制在于神经递质调控(例如多巴胺DA、乙酰胆碱ACh、肾上腺素)通过设置大脑全局变量来有效防止灾难性遗忘,这一机制有望增强人工神经网络在持续学习场景中的鲁棒性。本文将概述该领域的进展,进而详述两项6月Nature发表的背靠背相关研究。
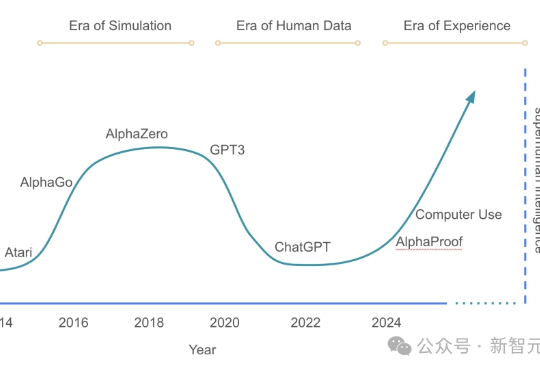
只靠强化学习,AGI就能实现?Claude-4核心成员放话「5年内AI干掉白领」,却被Karpathy等联手泼冷水!持续学习真的可能吗?RL的真正边界、下一代智能的关键转折点到底在哪儿?