
DeepSeek掀低成本革命,中科院系黑马闯入全球TOP 10!破解高精度-低能耗困局
DeepSeek掀低成本革命,中科院系黑马闯入全球TOP 10!破解高精度-低能耗困局2025年,中国大模型迎来最高光时刻。DeepSeek凭借深度推理、低成本强势崛起,中科院系AI企业祭出的YAYI-Ultra大模型在代码能力上超越GPT-4o,成功跻身OpenCompas榜单全球前十,高精度和低能耗兼而有之。
来自主题: AI资讯
8244 点击 2025-02-17 15:07
 搜索
搜索
2025年,中国大模型迎来最高光时刻。DeepSeek凭借深度推理、低成本强势崛起,中科院系AI企业祭出的YAYI-Ultra大模型在代码能力上超越GPT-4o,成功跻身OpenCompas榜单全球前十,高精度和低能耗兼而有之。
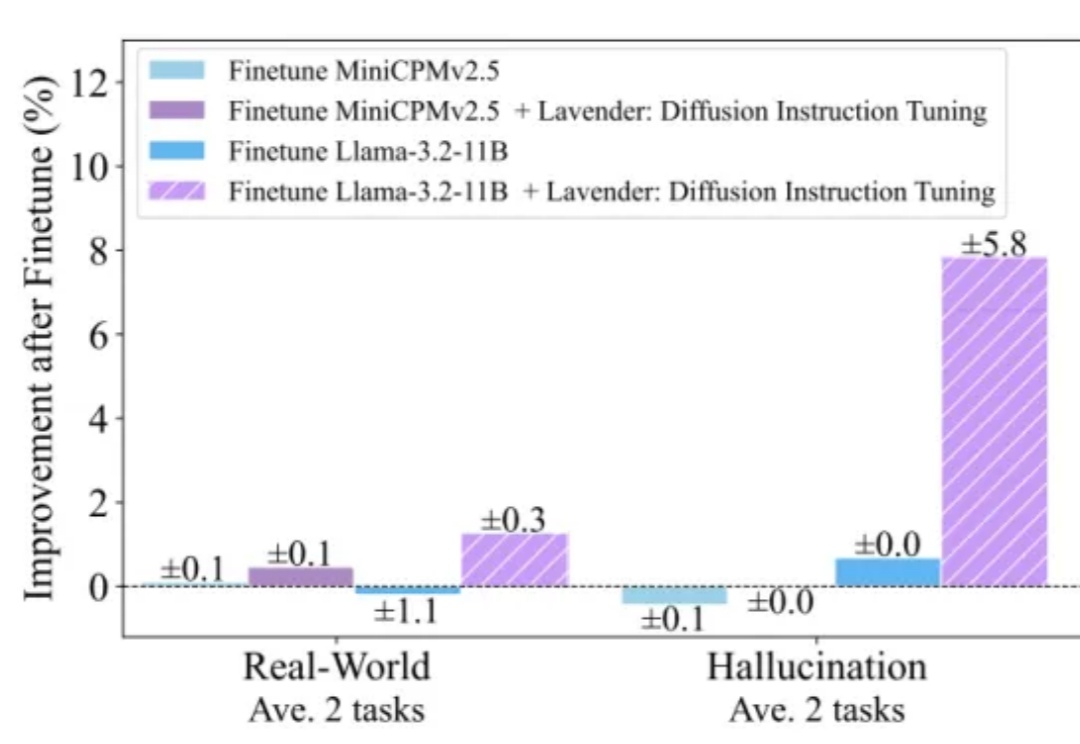
这次不是卷参数、卷算力,而是卷“跨界学习”——
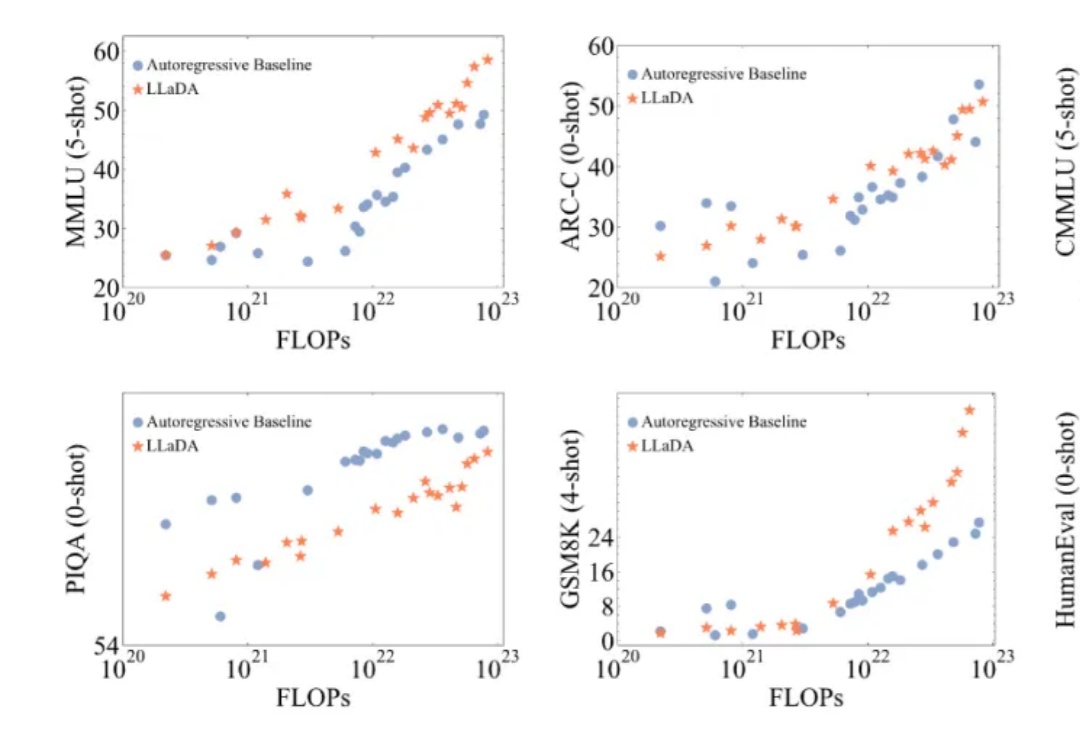
近年来,大语言模型(LLMs)取得了突破性进展,展现了诸如上下文学习、指令遵循、推理和多轮对话等能力。目前,普遍的观点认为其成功依赖于自回归模型的「next token prediction」范式。
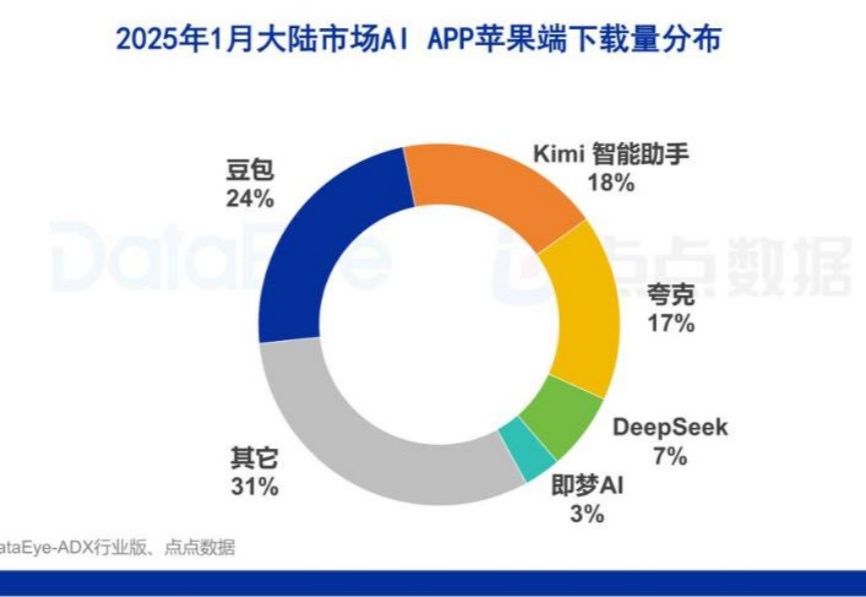
AI给阿里涨了约9000亿港元市值

人工智能科学家吴恩达指出,AI的浪潮将席卷各行各业,催生「10倍专业人士」!这不仅仅是效率的提升,更是工作方式的变革。本文将深入解读AI如何赋能职场,揭示成为「10倍人才」的秘诀!

广东打响了第一枪。深圳龙岗区的政务系统悄悄上线了DeepSeek-R1全尺寸模型,群众办事时面对的不再是机械的问答机器人,而是一个能理解“我想办落户,但社保断了3个月怎么办”这类复杂问题的AI公务员。东莞紧随其后,把DeepSeek塞进了人工智能大模型中心,号称要让“企业办证速度跑赢奶茶外卖”。更狠的是广州,直接祭出DeepSeek-R1和V3 671B双模型组合

全球空间智能第一股来了!来自中国,来自杭州。2月14日,空间智能独角兽群核科技正式向港交所递交招股说明书,启动IPO进程,冲击“全球空间智能第一股”,摩根大通、建银国际为联席保荐人。

据 BloomBerg 报道,OpenAI 的董事会正式拒绝了由埃隆·马斯克领导的一组投资者提出的以 974 亿美元收购控制这家人工智能公司的非营利组织的提议。

知乎直答默默掏出了自己的“底牌”。为啥这么说呢?因为知乎不仅有自己的AI模型,还攒了十多年的中文高质量知识库,再加上真实的问答场景作为AI的“实战训练场”,简直就是AI界的“学霸”。有了DeepSeek-R1的加持,知乎直答的推理能力直接拉满,传统搜索看了直呼“内行”,妥妥成了AI时代的“搜索界天花板”。
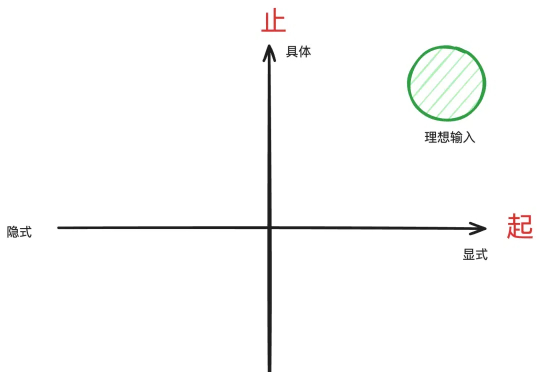
本文的作用是帮你把问题具体化,这是用好DeepSeek-R1等推理型模型的前置步骤。