OpenAI突然收购Ona!500万人Codex,永不下线
OpenAI突然收购Ona!500万人Codex,永不下线今天,OpenAI正式收购了Ona,一家专注于安全云执行与编排技术的公司。这步棋的战略意义很明显,给Codex补上一块能让AI「下班还在干活」的地基。奥特曼激动表示,「非常期待接下来的合作」。
来自主题: AI资讯
10207 点击 2026-06-12 18:02
 搜索
搜索
今天,OpenAI正式收购了Ona,一家专注于安全云执行与编排技术的公司。这步棋的战略意义很明显,给Codex补上一块能让AI「下班还在干活」的地基。奥特曼激动表示,「非常期待接下来的合作」。

决策机已推演23万起事件,准确率超90%。

刚刚,Anthropic CEO发布重磅檄文《指数级AI政策》:AI的「指数级爆炸」已无法阻挡,必须强制第三方测试+政府叫停!为此,Anthropic砸出3.5亿真金白银。

今年开年以来,不管是硅谷、还是国内的 AI 投资圈子,都不太敢投 AI 应用了。
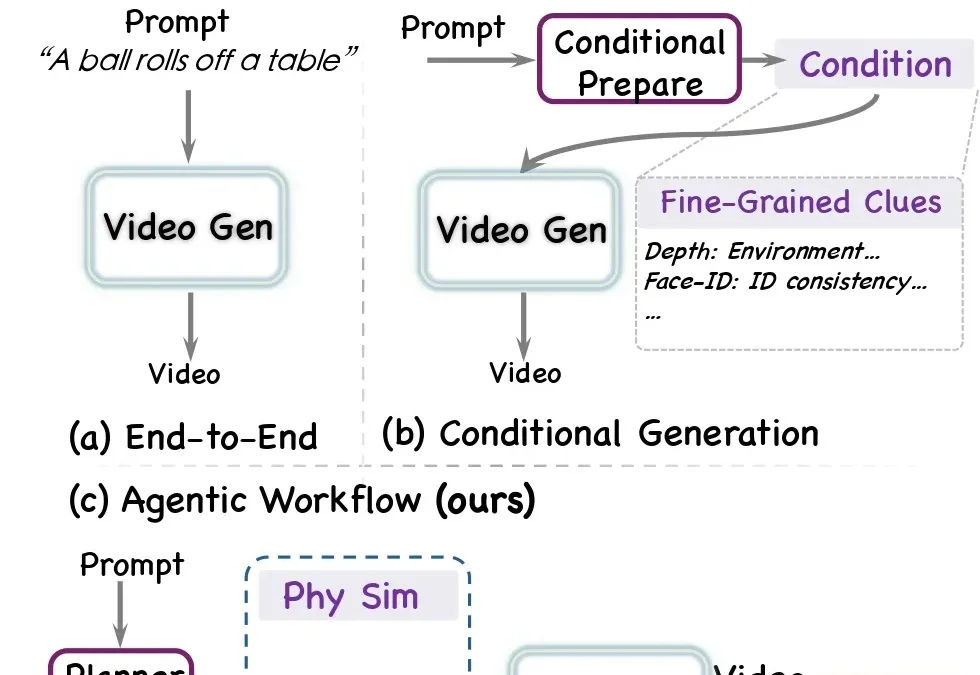
近年来,视频生成模型发展迅猛。从 Sora、Veo、Kling 到一系列开源视频生成模型,文生视频已经逼近真实影像的观感 —— 画面清晰、镜头流畅、风格可控,一句话就能生成一段观感不错的视频。
如果把一个商业化产品、一个科技公司的底层系统比作一棵树,那任意挑出一个项目,层层抽丝剥茧之后,你一定会发现,最早的年轮,一定与开源有关。

多模态长记忆在“看得准、找得到、想得清”三大环节的底层逻辑与工程避坑指南。
GPT-5.6本月上桌,agentic编码据称已反超Anthropic Mythos!三家旗舰模型撞进同一个6月,两大AI巨头同时冲刺IPO,奥特曼却在内部抛出了一个更大的变量:如果AI先学会自我改进,上市反而不急。

根据我长期使用的观察,0.3 倍率说是用 Kiro 逆向出来的 Claude,2.0 倍率说是正经 Claude Max 号池接出来的。听起来后者肯定更靠谱。我一开始也这么想的。毕竟倍率差了快七倍,价格摆在那,总不至于拿假货糊弄人吧。

在3D创作这个圈子,一直有个心照不宣的扎心真相: 那就是最难的一步从来不是生成,而是让模型变为可用资产。