
OpenAI官方基准测试:承认Claude遥遥领先(狗头)
OpenAI官方基准测试:承认Claude遥遥领先(狗头)刚刚开源的新基准测试PaperBench,6款前沿大模型驱动智能体PK复现AI顶会论文,新版Claude-3.5-Sonnet显著超越o1/r1排名第一。与去年10月OpenAI考验Agent机器学习代码工程能力MLE-Bnch相比,PaperBench更考验综合能力,不再是只执行单一任务。
来自主题: AI资讯
10660 点击 2025-04-03 10:37
 搜索
搜索
刚刚开源的新基准测试PaperBench,6款前沿大模型驱动智能体PK复现AI顶会论文,新版Claude-3.5-Sonnet显著超越o1/r1排名第一。与去年10月OpenAI考验Agent机器学习代码工程能力MLE-Bnch相比,PaperBench更考验综合能力,不再是只执行单一任务。
一个7B奖励模型搞定全学科,大模型强化学习不止数学和代码。

“艺术家与人工智能”的张力正在持续紧张。OpenAI虽然声称避免复制“个别在世艺术家的风格”,但它一直在践行并推动政策允许AI对版权内容的训练;而小部分能够承担高昂诉讼成本的艺术家,却也因为版权法灰色地带而面临不确定的局面,更不要说那些不知名的艺术家们了。

时隔4个月,再来讲下AI智能陪伴硬件。
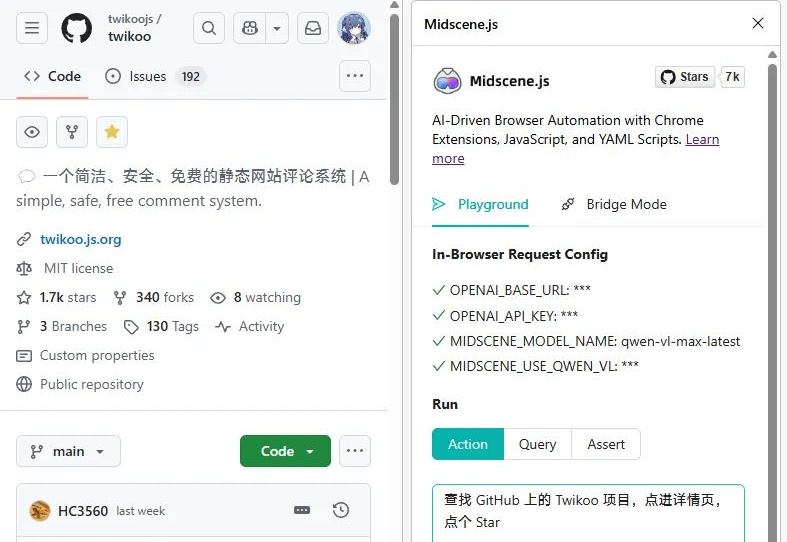
字节有一个很实用但不怎么火的项目,叫 Midscene.js,Chrome 商店上的安装数仅有 1 万,它是一个由多模态模型驱动的前端自动化测试插件。自动化测试我平常很少用到,但我发现它特别适合用来写爬虫……

DeepMind内部研究要「封箱」了!为保谷歌在AI竞赛领先优势,生成式AI相关论文设定6个月禁发期。不仅如此,创新成果不发,Gemini短板不提。

在算力投资激增的当下,GPU卡回收与维修行业逐渐成为一条隐秘的暴利赛道。特别是一些众所周知的原因,串串资源的货源和魔改卡的维保是重灾区! 现状:运营一年以上的算力中心运营商手里一定有坏掉的A100和H100服务得不到及时维修,放在那吃灰,无法对外出租算力产生收入。

这个世界永远不缺商业奇迹,隔几年就会涌现出一些新的标志性人物,Cursor 联合创始人兼 CEO Michael Truell 应该就是当下的一位新星。
在数学推理中,大语言模型存在根本性局限:在美国数学奥赛,顶级AI模型得分不足5%!来自ETH Zurich等机构的MathArena团队,一下子推翻了AI会做数学题这个神话。

最近GPT-4o确实超级好玩,玩法不要太多,我有很多想法但无奈最近服务器一天到晚崩溃个没完,(建议只为了生图功能准备买会员还没买的再考虑考虑),暂时没法做多玩法汇总的详细教程,今天单讲生成表情包的流程。