
无需人工标注!AI自生成训练数据,靠「演绎-归纳-溯因」解锁推理能力
无需人工标注!AI自生成训练数据,靠「演绎-归纳-溯因」解锁推理能力新加坡国立大学等机构的研究者们通过元能力对齐的训练框架,模仿人类推理的心理学原理,将演绎、归纳与溯因能力融入模型训练。实验结果显示,这一方法不仅提升了模型在数学与编程任务上的性能,还展现出跨领域的可扩展性。
来自主题: AI技术研报
11307 点击 2025-06-03 10:36
 搜索
搜索
新加坡国立大学等机构的研究者们通过元能力对齐的训练框架,模仿人类推理的心理学原理,将演绎、归纳与溯因能力融入模型训练。实验结果显示,这一方法不仅提升了模型在数学与编程任务上的性能,还展现出跨领域的可扩展性。
随着大语言模型 (LLM) 的出现,扩展 Transformer 架构已被视为彻底改变现有 AI 格局并在众多不同任务中取得最佳性能的有利途径。因此,无论是在工业界还是学术界,探索如何扩展 Transformer 模型日益成为一种趋势。

MiniMax即将发布代号M+的文本推理模型,其表现将影响公司未来竞争力。面对DeepSeek R1的冲击,MiniMax采取国内C端不接入、海外接入的策略,并推出类Manus产品MiniMax Agent。公司通过品牌拆分(海螺AI更名)、纯API商业模式拓展市场,语音模型商业化效果显著,但未进入“基模五强”名单。新推理模型或成其保持行业地位的关键。

近年来,大语言模型(LLMs)的能力突飞猛进,但随之而来的隐私风险也逐渐浮出水面。

不久前,GPT-4o 的最新图像风格化与编辑能力横空出世,用吉卜力等风格生成的效果令人惊艳,也让我们清晰看到了开源社区与商业 API 在图像风格化一致性上的巨大差距。

如何让CLIP模型更关注细粒度特征学习,避免“近视”?360人工智能研究团队提出了FG-CLIP,可以明显缓解CLIP的“视觉近视”问题。让模型能更关注于正确的细节描述,而不是更全局但是错误的描述。
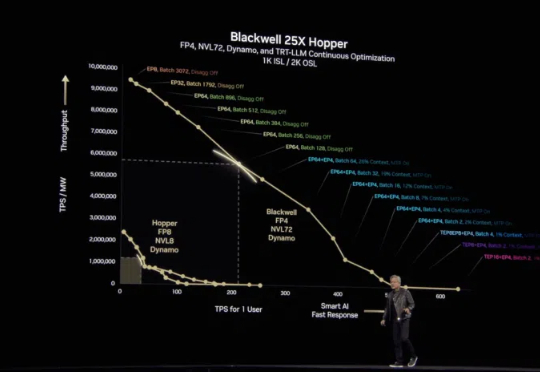
深度|对话英伟达CEO黄仁勋:不进入中国就等于错过了90%的市场机会;英伟达即将进入高达50万亿美元的产业领域
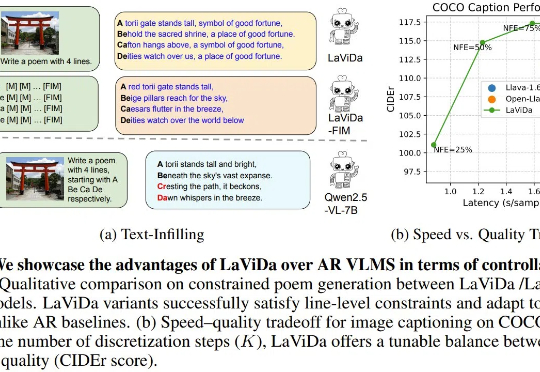
近段时间,已经出现了不少基于扩散模型的语言模型,而现在,基于扩散模型的视觉-语言模型(VLM)也来了,即能够联合处理视觉和文本信息的模型。今天我们介绍的这个名叫 LaViDa,继承了扩散语言模型高速且可控的优点,并在实验中取得了相当不错的表现。

昨天发现Mary Meeker又重新开始发布她每年一次的《互联网趋势报告》,只不过这次开始叫《人工智能趋势报告》了,整份报告有 340 页,非常详细的分析了AI领域的现状。

其实“野朋友”的AI能力还不完善,参与生态保护的人力资源也远远不够,而这个案例有趣之外,恰恰在于把生态保护跟大模型能力的训练结合在一起。其实“野朋友”的AI能力还不完善,参与生态保护的人力资源也远远不够,而这个案例有趣之外,恰恰在于把生态保护跟大模型能力的训练结合在一起。