创智「小红书」震撼上线,让AI从效率工具进化为认知伙伴
创智「小红书」震撼上线,让AI从效率工具进化为认知伙伴我们似乎正处在一个“收藏即掌握”的时代。 不管是知乎、论文库,还是小红书,只要看到一句金句、一篇好文、一个值得学习的案例,我们的第一反应往往是点个收藏,留着以后看。然而,我们真的会“回头再看”吗?
来自主题: AI资讯
9675 点击 2025-07-23 10:34
 搜索
搜索
我们似乎正处在一个“收藏即掌握”的时代。 不管是知乎、论文库,还是小红书,只要看到一句金句、一篇好文、一个值得学习的案例,我们的第一反应往往是点个收藏,留着以后看。然而,我们真的会“回头再看”吗?

你有没有想过,我们正在见证软件史上最深刻的一次变革?不是什么渐进式的改进,而是一场颠覆性的革命。

兄弟们,是不是也感觉最近被Cursor“背刺”了?这位曾经的AI编程王者,开启 AI 编程大航海时代的白月光,现在是又卡又慢,关键的Claude模型还不给中国区用、改变计费方式,用户的体验简直一言难尽。

在过去很长一段时间里,科技圈似乎人均都成了“提示词工程师”,大家都在琢磨怎么用最精妙的语言驯服AI。但包括Andrej Karpathy在内的很多行业大佬已经开始反思了,他们认为,决定AI效果的关键,可能早就不是怎么问,而是你给AI喂了什么料。这个思路,就是最近越来越火的上下文工程(Context Engineering)。

编程Agent王座,国产开源模型拿下了!就在刚刚,阿里通义大模型团队开源Qwen3-Coder,直接刷新AI编程SOTA——不仅在开源界超过DeepSeek V3和Kimi K2,连业界标杆、闭源的Claude Sonnet 4都比下去了。
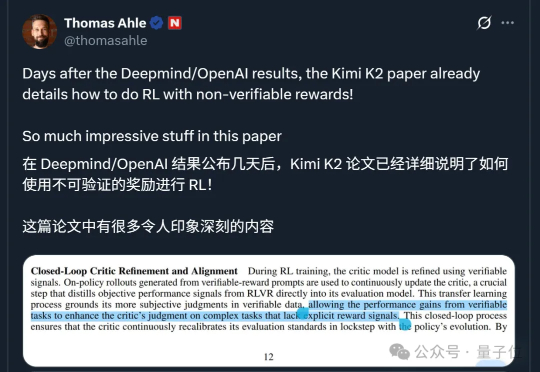
Kimi K2称霸全球开源模型的秘籍公开了!

火到不能再火的Agent,零一万物也下场了。
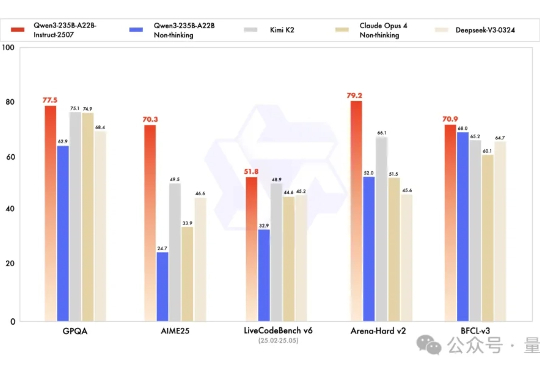
开源大模型正在进入中国时间。 Kimi K2风头正盛,然而不到一周,Qwen3就迎来最新升级,235B总参数量仅占Kimi K2 1T规模的四分之一。 基准测试性能上却超越了Kimi K2。
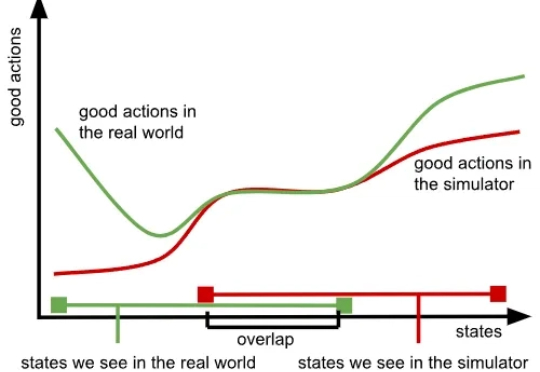
我们知道,训练大模型本就极具挑战,而随着模型规模的扩大与应用领域的拓展,难度也在不断增加,所需的数据更是海量。大型语言模型(LLM)主要依赖大量文本数据,视觉语言模型(VLM)则需要同时包含文本与图像的数据,而在机器人领域,视觉 - 语言 - 行动模型(VLA)则要求大量真实世界中机器人执行任务的数据。
健身不戴表,等于没健身。 经常用 Apple Watch 的人都知道这里面的门道有多深,作为一个对打卡有执念的 Apple Watch 用户,我每天的头等大事,就是把三个圆环「活动、锻炼、站立」尽可能闭合。