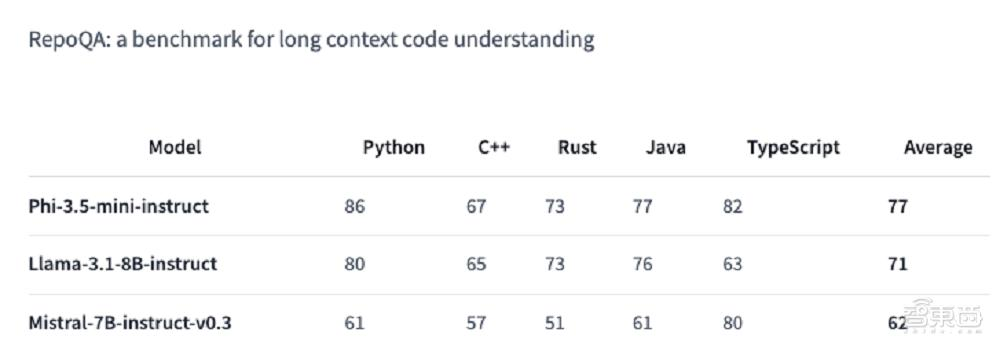
微软连发3款Phi-3.5模型:128K上下文,首用MoE架构,部分性能超GPT-4o mini
微软连发3款Phi-3.5模型:128K上下文,首用MoE架构,部分性能超GPT-4o mini轻量级模型的春天要来了吗?
来自主题: AI资讯
9122 点击 2024-08-22 09:29
 搜索
搜索
轻量级模型的春天要来了吗?

现在,长上下文视觉语言模型(VLM)有了新的全栈解决方案 ——LongVILA,它集系统、模型训练与数据集开发于一体。

长文本处理能力对LLM的重要性是显而易见的。在2023年初,即便是当时最先进的GPT-3.5,其上下文长度也仅限于2k,然而今日,128k的上下文长度已经成为衡量模型技术先进性的重要标志之一。那你知道LLMs的长文本阅读能力如何评估吗?

国产多模态大模型,也开始卷上下文长度。

当今的LLM已经号称能够支持百万级别的上下文长度,这对于模型的能力来说,意义重大。但近日的两项独立研究表明,它们可能只是在吹牛,LLM实际上并不能理解这么长的内容。
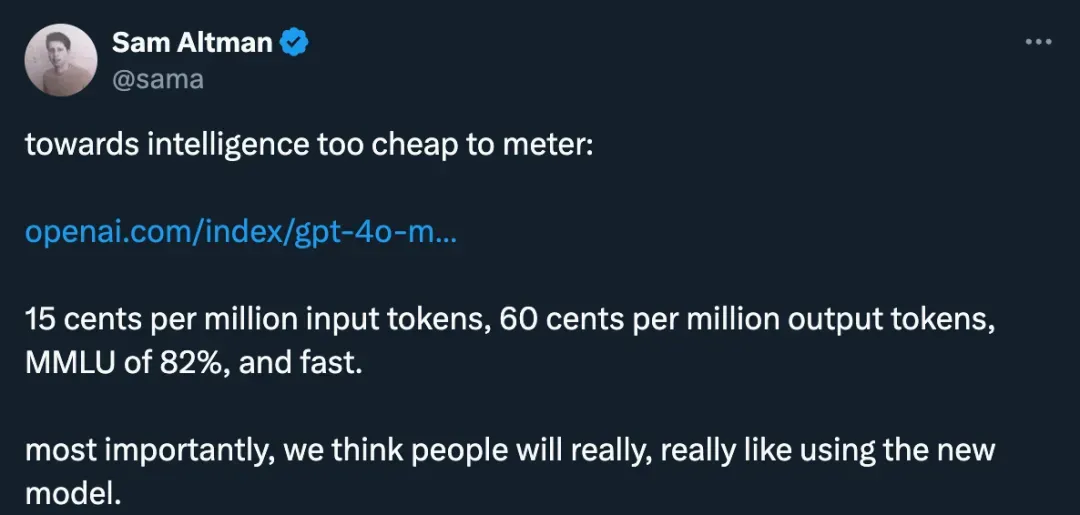
小模型,正在成为 AI 巨头的新战场。
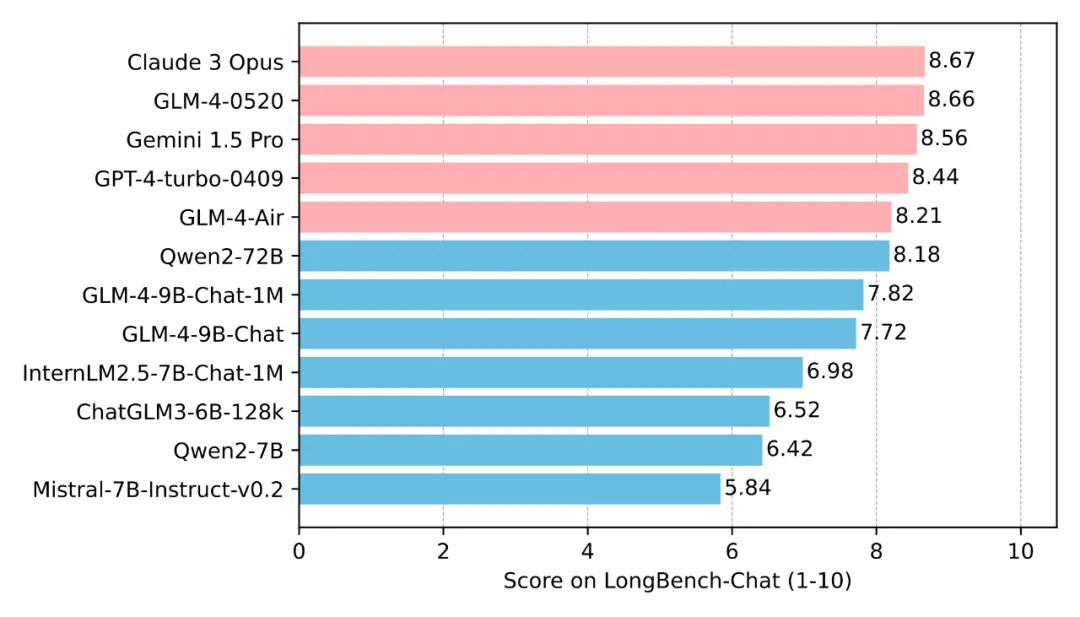
在2023年初,即便是当时最先进的GPT-3.5,其上下文长度也仅限于2k。然而,时至今日,1M的上下文长度已经成为衡量模型技术先进性的重要标志之一。

视频生成也能参考“上下文”?!

长上下文大模型帮助机器人理解世界。
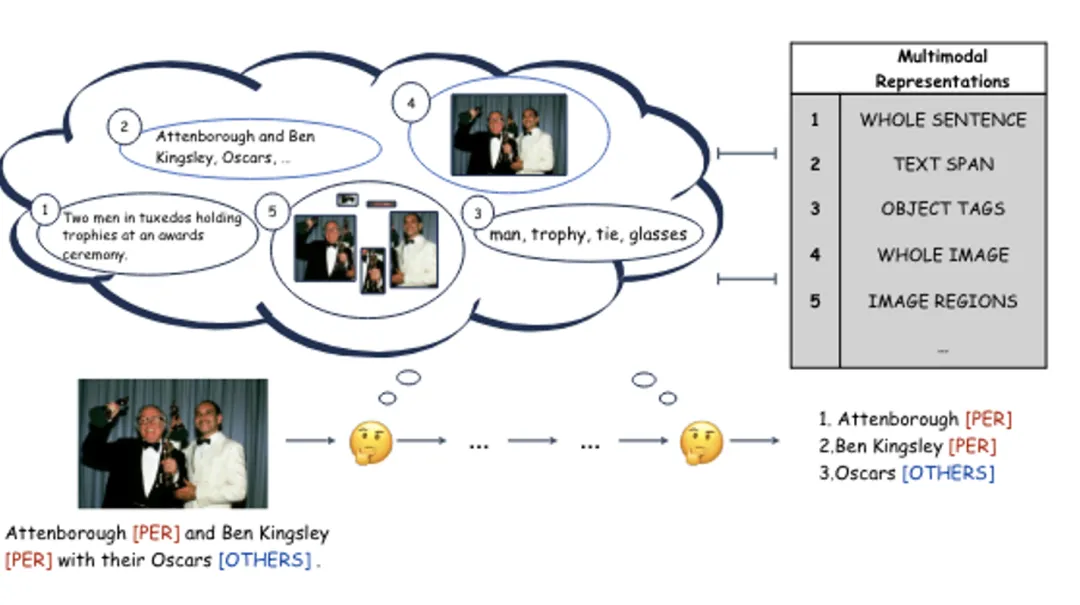
多模态命名实体识别,作为构建多模态知识图谱的一项基础而关键任务,要求研究者整合多种模态信息以精准地从文本中提取命名实体。尽管以往的研究已经在不同层次上探索了多模态表示的整合方法,但在将这些多模态表示融合以提供丰富上下文信息、进而提升多模态命名实体识别的性能方面,它们仍显不足。