
OpenAI估值将冲破千亿美金!微软再次输血,新一轮融10亿
OpenAI估值将冲破千亿美金!微软再次输血,新一轮融10亿OpenAI再迎新一轮巨额融资,估值破千亿美元大关,稳坐AI初创公司身价头把交椅。
来自主题: AI资讯
9096 点击 2024-08-29 15:45
 搜索
搜索
OpenAI再迎新一轮巨额融资,估值破千亿美元大关,稳坐AI初创公司身价头把交椅。

OpenAI又憋大招了!据悉,下一代旗舰模型GPT-5或名为「猎户座」,由「草莓」合成的数据训练。而草莓具有极强的复杂推理(数学、编程)和语言能力,或将超越当前的任何模型的推理和生成的能力。

ChatGPT 要进化了?

根据Google Cloud最新调查结果,使用GenAI的86%的企业实现了6%的收入增长,但这份报告也同时提出,需要注意平衡员工的人工智能工作模式。

OpenAI 传说中的「Strawberry(草莓)」模型终于要来了。
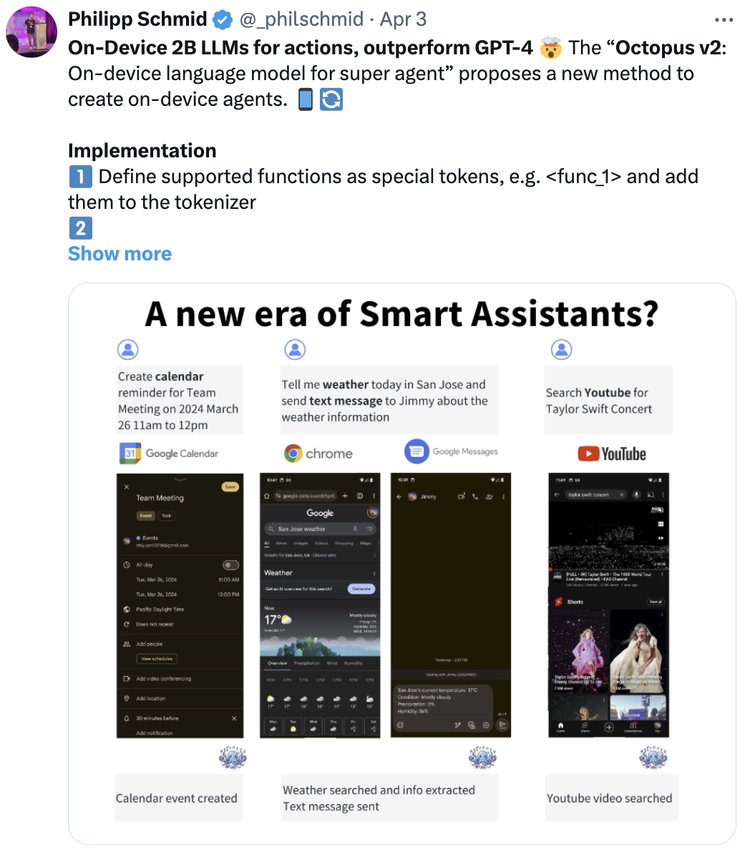
比OpenAI最强的GPT-4o更快,函数调用能力与GPT-4相当,同时比它小N倍,且只需要一张卡来做推理。

生成式AI应用排名中,创意工具最受欢迎,消费助手竞争激烈,字节跳动显著发力。 • 创意工具不断吸引消费者,新上榜公司中58%来自创意领域 • 成为“最佳消费者助手”产品的竞争加剧,ChatGPT仍居首位 • 字节跳动在AI应用领域扩展,多个新应用首次上榜

2022年ChatGPT横空出世后,2023-2024年间,科技大厂们开始在人工智能领域投入巨额资金
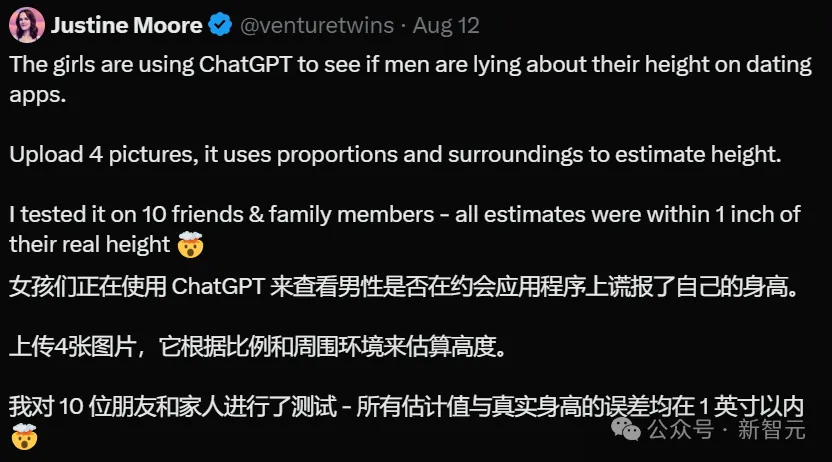
担心相亲对象谎报身高怎么办?交给ChatGPT!

以 GPT 为代表的大型语言模型预示着数字认知空间中通用人工智能的曙光。这些模型通过处理和生成自然语言,展示了强大的理解和推理能力,已经在多个领域展现出广泛的应用前景。无论是在内容生成、自动化客服、生产力工具、AI 搜索、还是在教育和医疗等领域,大型语言模型都在不断推动技术的进步和应用的普及。