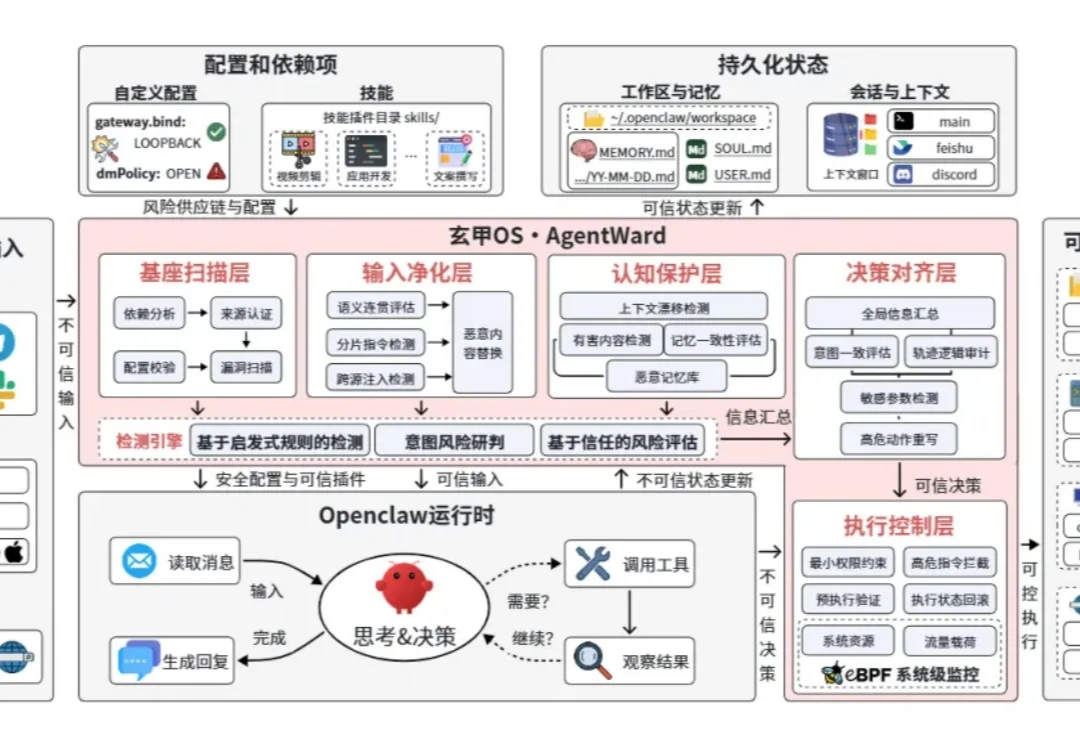
跨越智能体落地的可信鸿沟:玄甲(AgentWard)全链路防御操作系统正式发布
跨越智能体落地的可信鸿沟:玄甲(AgentWard)全链路防御操作系统正式发布大模型技术正在经历一场从 “对话助手” 向 “自主智能体(Agent)” 的深刻演进。智能体不再局限于被动地理解与生成,而是具备了多步规划、工具调用、长期记忆与管理物理 / 数字世界的能力,正逐步深度嵌入企业侧的核心业务流程。这意味着,AI 的边界已从虚拟屏幕的对话框,正式延伸到了真实的生产系统中。
来自主题: AI技术研报
8766 点击 2026-04-07 10:00