
长得好看又会「看脸色」,深穹星核不卷「干活」卷「懂你」,天使轮再获数千万战略加注
长得好看又会「看脸色」,深穹星核不卷「干活」卷「懂你」,天使轮再获数千万战略加注近日,深穹星核正式发布首款高仿真人脸机器人 Nova S1,搭载 VLIA 一体化端侧交互大脑,面向家庭、日常交互与协作场景。继上周天使 4 轮融资后,公司再次完成新一轮数千万元天使 5 轮战略融资,持续加码意图理解与情感交互技术的研发落地。
来自主题: AI资讯
9759 点击 2026-07-07 11:36
 搜索
搜索
近日,深穹星核正式发布首款高仿真人脸机器人 Nova S1,搭载 VLIA 一体化端侧交互大脑,面向家庭、日常交互与协作场景。继上周天使 4 轮融资后,公司再次完成新一轮数千万元天使 5 轮战略融资,持续加码意图理解与情感交互技术的研发落地。
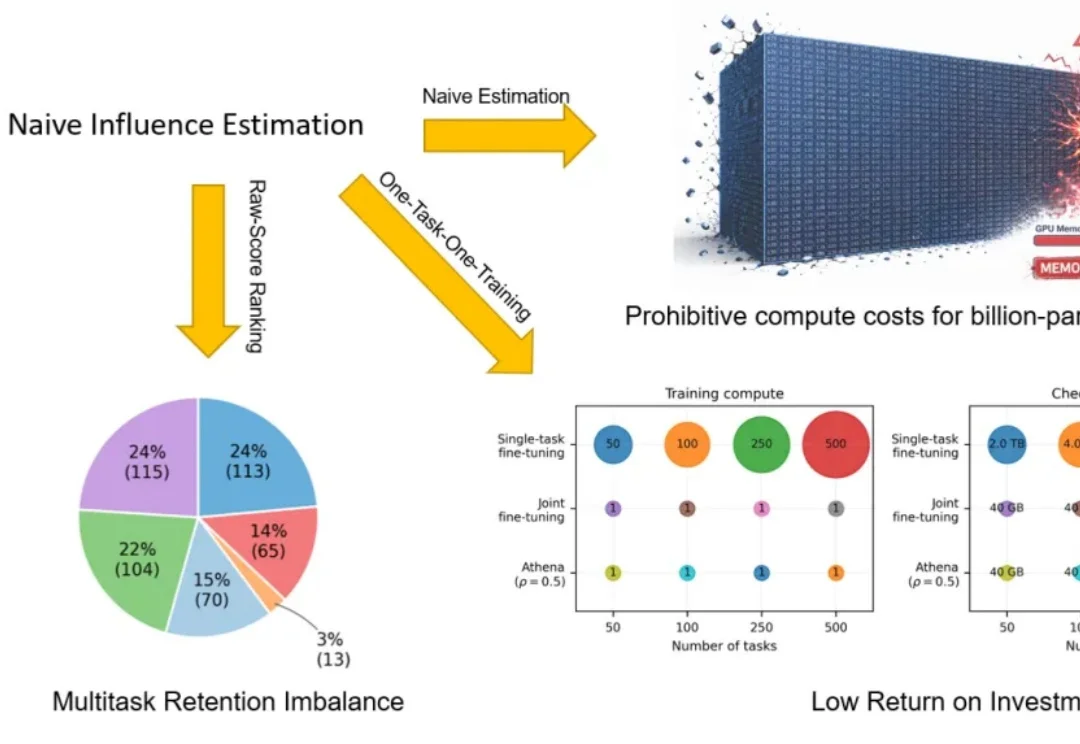
具身智能正在进入数据 scaling 时代。Vision-Language-Action(VLA)模型让机器人可以从大规模示教数据(demonstrations)中学习更通用的操作策略。但对机器人 VLA 训练来说,数据并不总是越多越好:低质量数据可能会拖累模型性能,而每一条 demonstration 都意味着昂贵的人力采集、机器人运行,以及云端存储和训练成本。
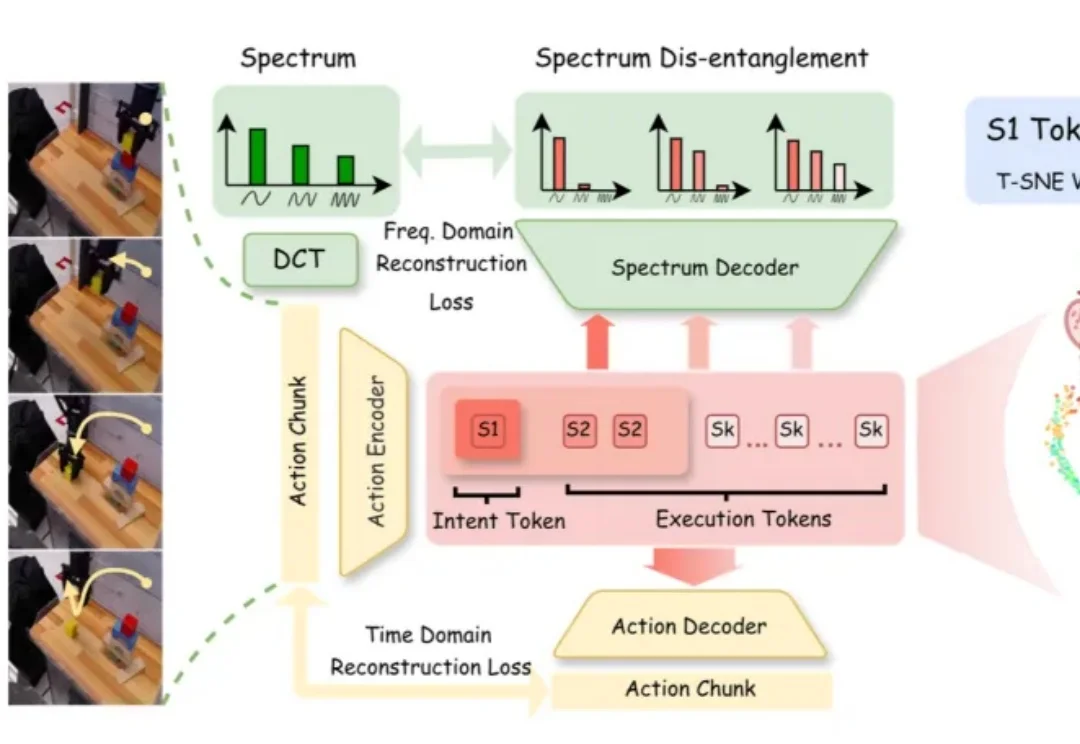
机器人视觉语言动作(Vision-Language-Action, VLA)模型越来越多地开始展示叠衣服、倒茶、做咖啡等复杂操作。但是,今天的大多数 VLA 更像 “展台机器人”。

Jim Fan 押注的这条 “先预测世界,再生成动作” 的新路,正是当下具身智能领域最炙手可热的下一代范式 —— 世界动作模型(World Action Models,简称 WAM)。虽然 WAM 正在迅速成为各大顶尖实验室的核心发力点,但业界至今仍然缺乏对它的统一标准和系统梳理。近期,复旦大学可信具身智能研究院,上海创智学院,新加坡国立大学发表了首篇 WAM 的详细综述。
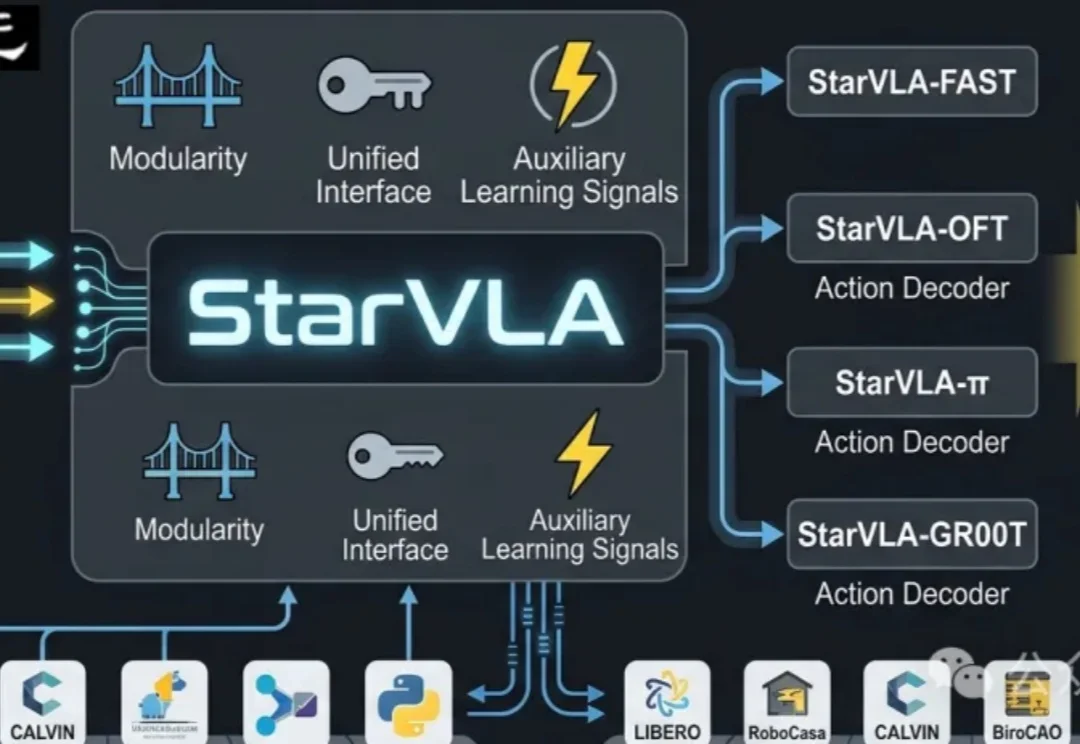
当前具身智能的VLA(Vision-Language-Action)赛道正陷入典型的「碎片化」泥潭:不同团队采用异构的动作解码范式、强耦合的数据管线、互不兼容的评测协议,导致方法难以横向对比,复现成本极高。
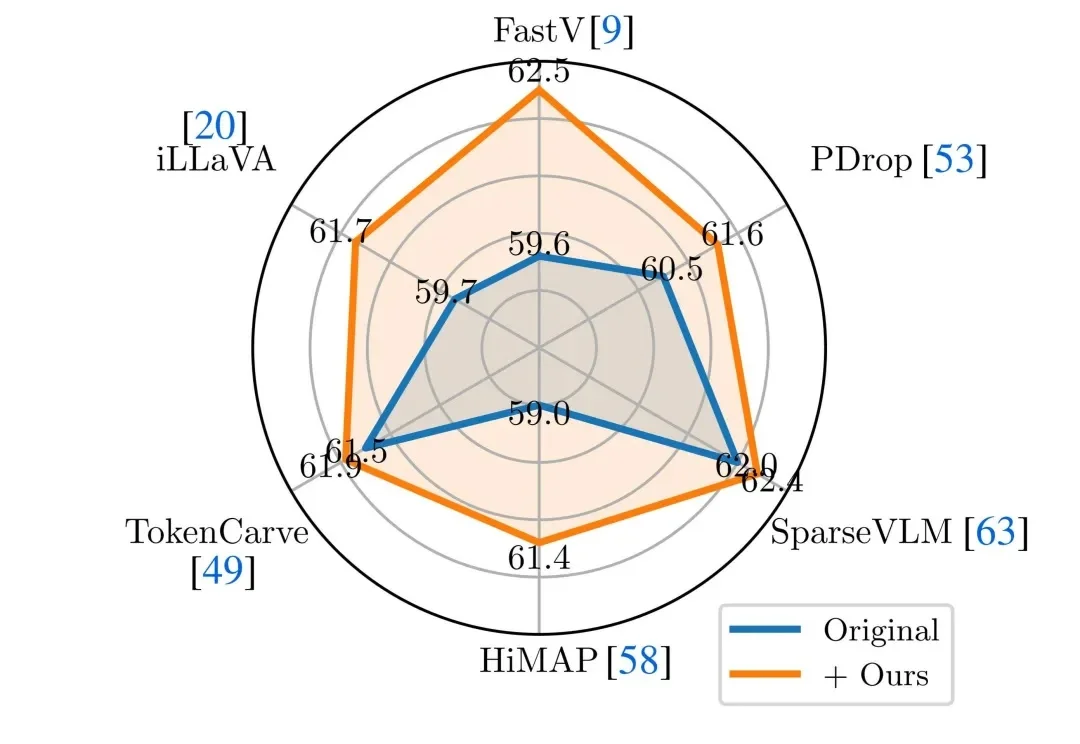
近年来,Vision-Language Models(视觉 — 语言模型)在多模态理解任务中取得了显著进展,并逐渐成为通用人工智能的重要技术路线。然而,这类模型在实际应用中往往面临推理开销大、效率受限的问题,研究者通常依赖 visual token pruning 等策略降低计算成本,其中 attention 机制被广泛视为衡量视觉信息重要性的关键依据。
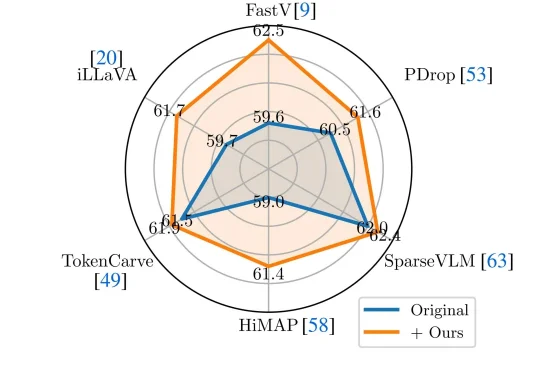
近年来,Vision-Language Models(视觉—语言模型)在多模态理解任务中取得了显著进展,并逐渐成为通用人工智能的重要技术路线。

实现通用机器人的类人灵巧操作能力,是机器人学领域长期以来的核心挑战之一。近年来,视觉 - 语言 - 动作 (Vision-Language-Action,VLA) 模型在机器人技能学习方面展现出显著潜力,但其发展受制于一个根本性瓶颈:高质量操作数据的获取。

在 Vision-Language Model 领域,提升其复杂推理能力通常依赖于耗费巨大的人工标注数据或启发式奖励。这不仅成本高昂,且难以规模化。
在多模态智能浪潮中,视觉语言模型(Vision-Language Models, VLM)已成为连接视觉理解与语言生成的核心引擎。从图像描述、视觉问答到 AI 教育和交互系统,它们让机器能够「看懂世界、说人话」。