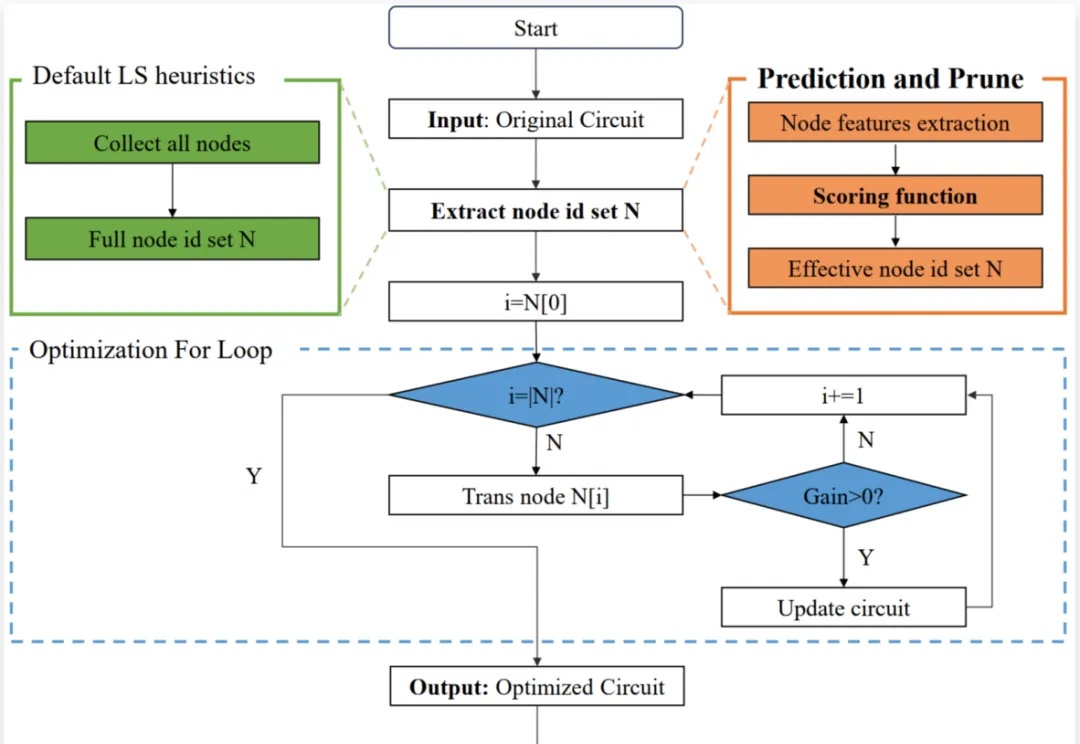
芯片设计效率提升2.5倍,中科大华为诺亚联合,用GNN+蒙特卡洛树搜索优化电路设计 | ICLR2025
芯片设计效率提升2.5倍,中科大华为诺亚联合,用GNN+蒙特卡洛树搜索优化电路设计 | ICLR2025芯片设计是现代科技的核心,逻辑优化(Logic Optimization, LO)作为芯片设计流程中的关键环节,其效率直接影响着芯片设计的整体性能。
来自主题: AI技术研报
5499 点击 2025-04-10 11:03
 搜索
搜索
芯片设计是现代科技的核心,逻辑优化(Logic Optimization, LO)作为芯片设计流程中的关键环节,其效率直接影响着芯片设计的整体性能。
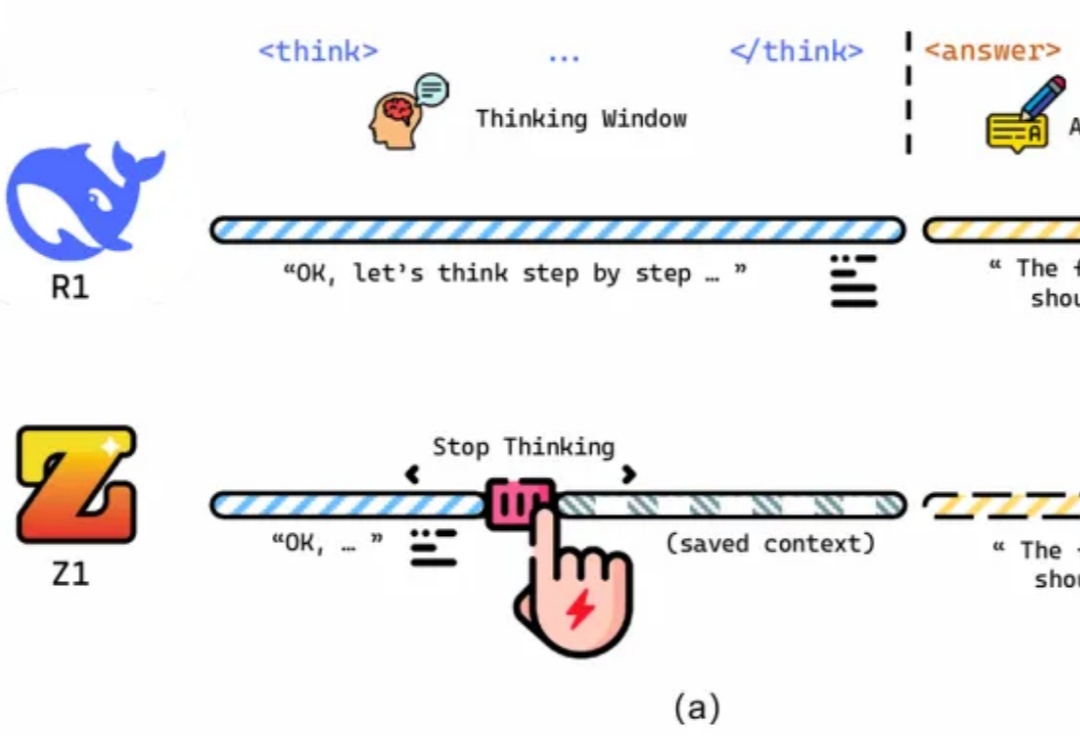
推理性能提升的同时,还大大减少Token消耗!
近年来,大语言模型(LLM)的性能提升逐渐从训练时规模扩展转向推理阶段的优化,这一趋势催生了「测试时扩展(test-time scaling)」的研究热潮。
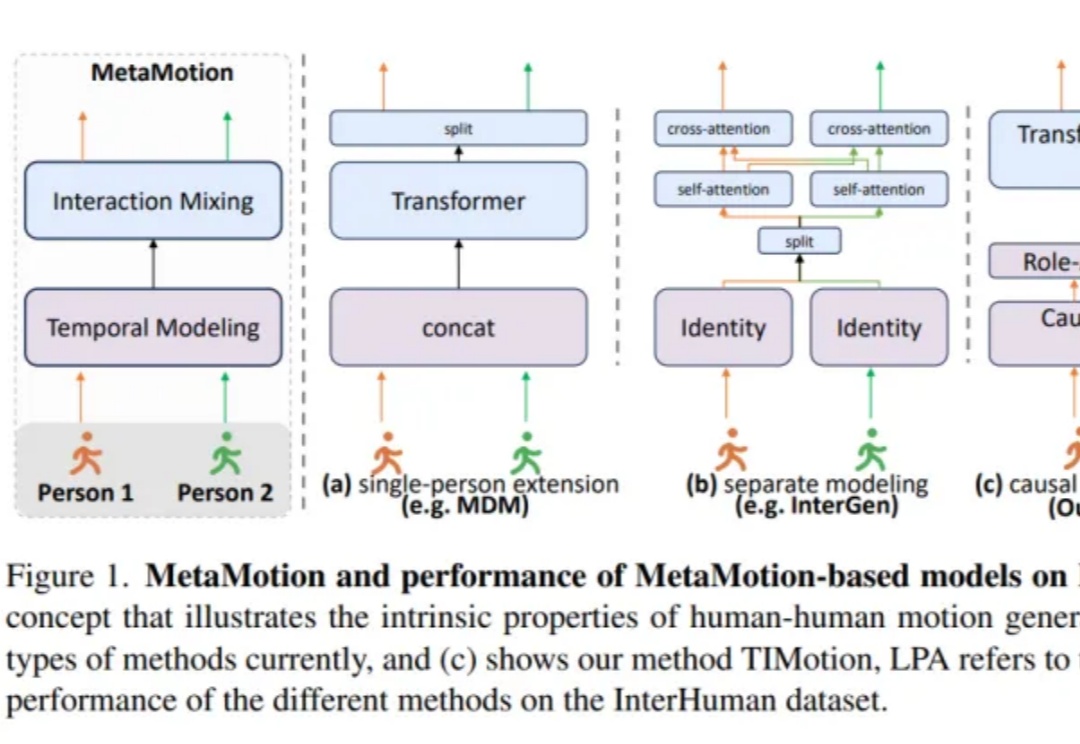
双人动作生成新SOTA!
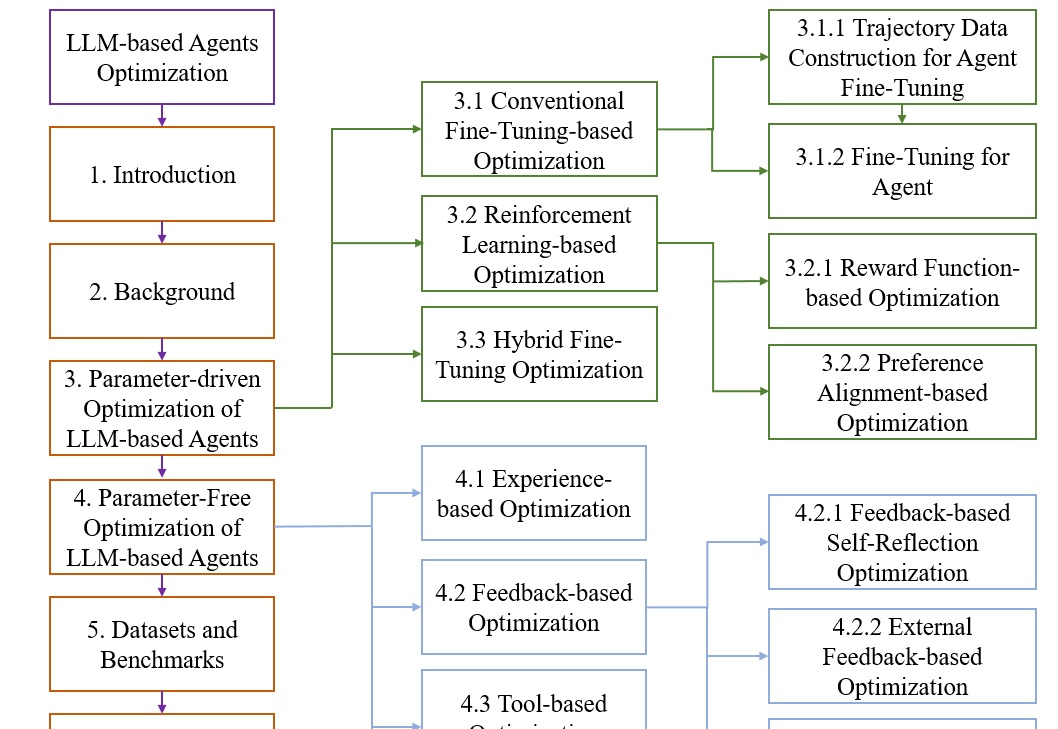
本文基于一项系统性研究《A Survey on the Optimization of Large Language Model-based Agents》,该研究由华东师大和东华大学多位人工智能领域的研究者共同完成。研究团队通过对大量相关文献的分析,构建了一个全面的LLM智能体优化框架,涵盖了从理论基础到实际应用的各个方面。您有兴趣可以找来读一下这篇综述。

如果你让当今的 LLM 给你生成一个创意时钟设计,使用提示词「a creative time display」,它可能会给出这样的结果:
肝癌是全球癌症相关死亡的第三大原因,手术切除后的复发率高达70%,如何准确预测肿瘤手术切除后复发风险是一个难题。
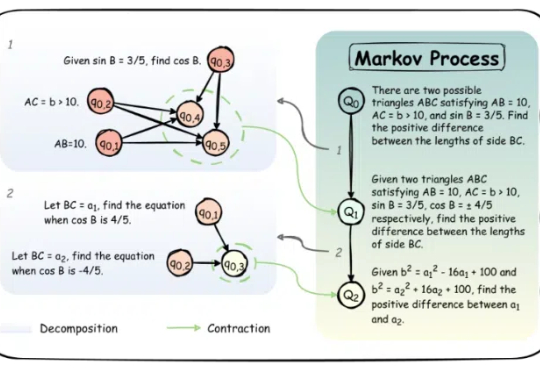
大语言模型(LLM)近年来凭借训练时扩展(train-time scaling)取得了显著性能提升。然而,随着模型规模和数据量的瓶颈显现,测试时扩展(test-time scaling)成为进一步释放潜力的新方向。

尽管 DeepSeek-R1 在单模态推理中取得了显著成功,但已有的多模态尝试(如 R1-V、R1-Multimodal-Journey、LMM-R1)尚未完全复现其核心特征。
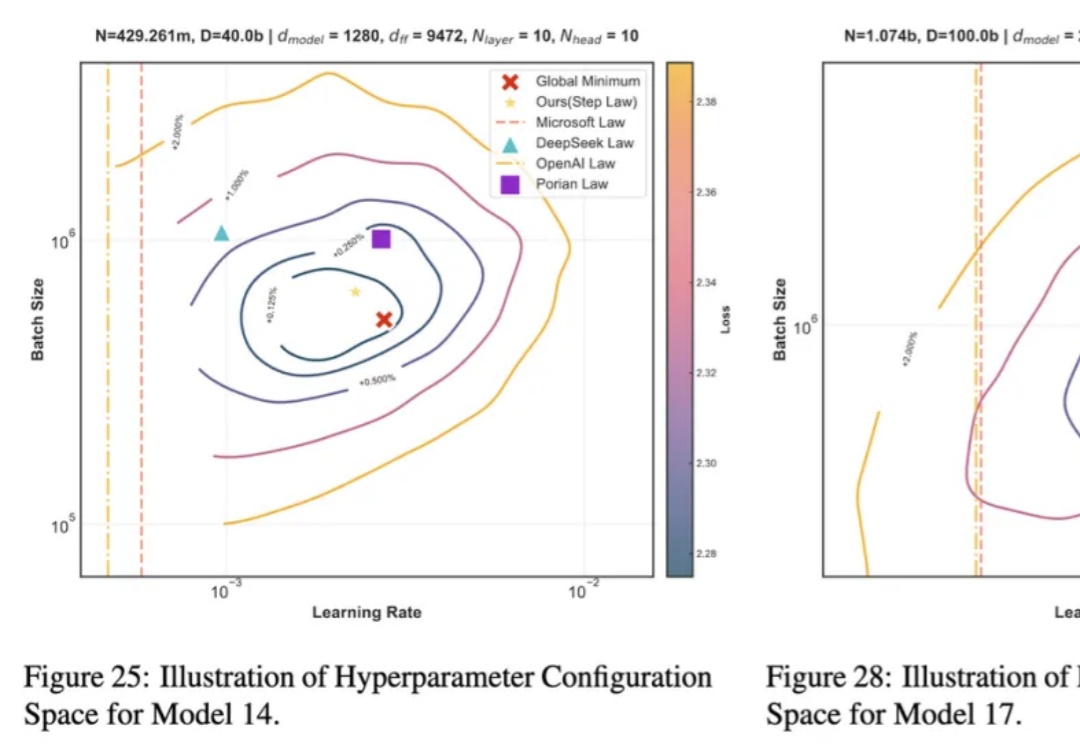
近年来,大语言模型 LLMs 在多种任务上的卓越表现已得到广泛认可。然而,要实现其高效部署,精细的超参数优化至关重要。为了探究最佳超参数的规律,我们开展了大规模的实证研究,通过在不同配置上进行网格搜索,我们揭示了一套通用的最优超参数缩放定律(Optimal Hyperparameter Scaling Law)。