
他为500强造出冠军「AI裁员机器」!然后,把自己裁掉了
他为500强造出冠军「AI裁员机器」!然后,把自己裁掉了Donald King曾在全球顶级会计师事务所普华永道(PwC)为众多500强客户打造AI智能体。作为公司AI黑客松大赛的冠军,King获得的不是奖励和提拔,而是公司裁员的电话。
来自主题: AI资讯
11949 点击 2025-11-24 11:28
 搜索
搜索
Donald King曾在全球顶级会计师事务所普华永道(PwC)为众多500强客户打造AI智能体。作为公司AI黑客松大赛的冠军,King获得的不是奖励和提拔,而是公司裁员的电话。
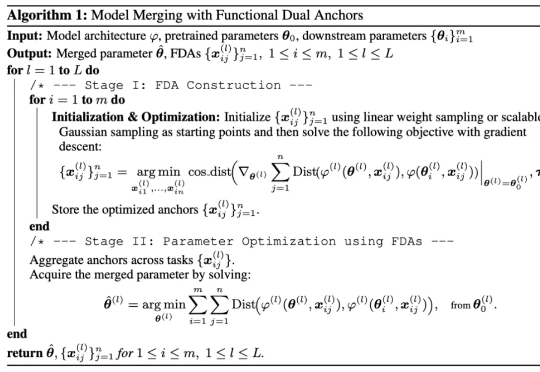
研究者们提出了 FDA(Model Merging with Functional Dual Anchors)——一个全新的模型融合框架。与传统的参数空间操作不同,FDA 将专家模型的参数知识投射到输入-表征空间中的合成锚点,通过功能对偶的方式实现更高效的知识整合。
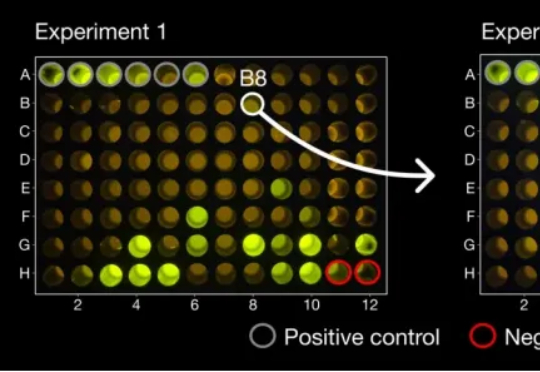
现实爽文,小扎打脸! 2023年上半年,扎克伯格在Meta大裁员,几个月之内裁掉一万人,其中就包括由十几名科学家组成的Meta-FAIR蛋白质小组。 然而,被裁掉的几名科学家不甘心,创办了AI蛋白质公

十月,《纽约时报》发表了题为《The A.I. Prompt That Could End the World》(《那个可能终结世界的 AI 提示词》)的文章。作者 Stephen Witt 采访了多位业内人士:有 AI 先驱,图灵奖获奖者 Yoshua Bengio;以越狱测试著称的 Leonard Tang;以及专门研究模型欺骗的 Marius Hobbhahn。
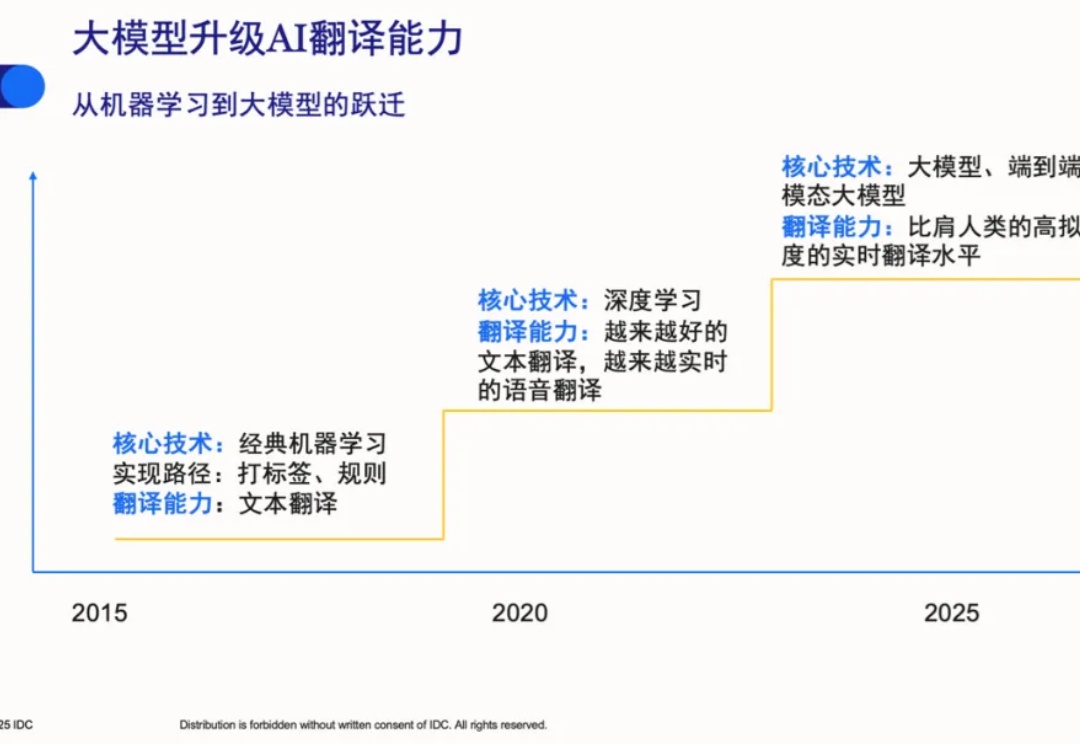
2025 年 10 月,国际数据公司(International Data Corporation,IDC)发布了《中国 AI 翻译技术评估》报告。这份以“大模型驱动 AI 翻译能力全面换新”为主题的报告指出,大模型技术的全面渗透正在深刻重塑 AI 翻译市场。
在讨论 AGI 或者通用机器人定义时,人们往往会自然联想到一些直观的衡量标准,比如 AI 能否解出高考题、在国际数学奥林匹克(IMO,International Mathematical Olympiad)上获得金牌,或者机器人能否胜任家务。
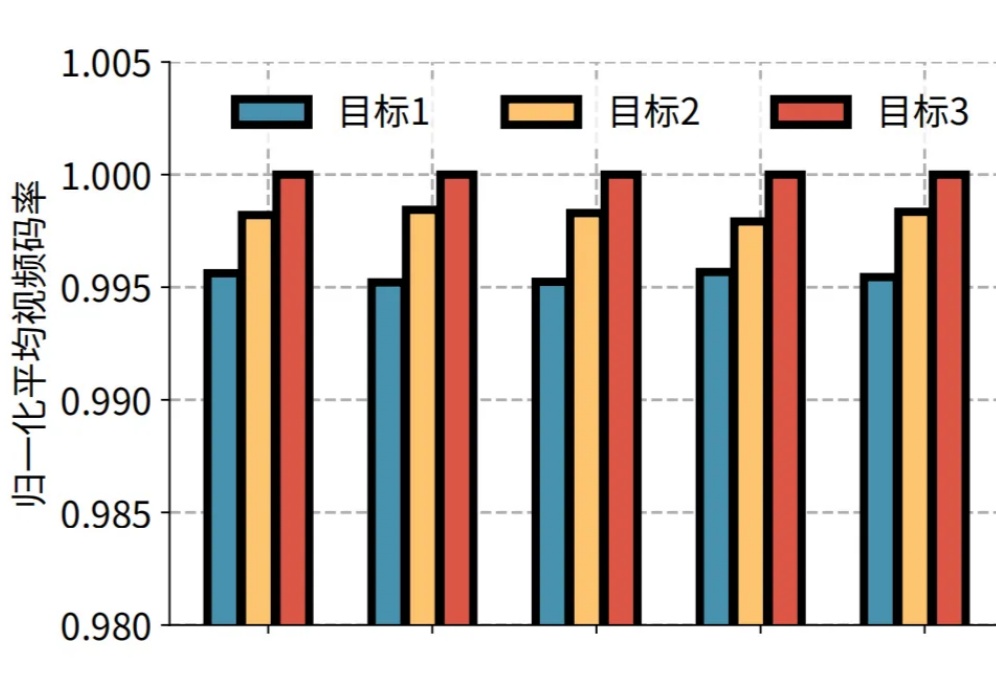
近日,快手与清华大学孙立峰团队联合发表论文《Towards User-level QoE: Large-scale Practice in Personalized Optimization of Adaptive Video Streaming》,被计算机网络领域的国际顶尖学术会议 ACM SIGCOMM 2025 录用。
他曾是Ilya的亲信,因揭露OpenAI安全隐患被解雇,却在短短6个月内以47%回报打造出管理规模15亿美元的基金。作为AI安全激进派,他在165页论文《Situational Awareness》中预测2027年将迎来AGI,并呼吁建立「AI版曼哈顿计划」。

就在刚刚,也许是目前最强的开源蛋白质结合剂AI设计工具,登上Nature。瑞士洛桑联邦理工学院、美国麻省理工学院等研究人员在Nature上发表了题为One-shot design of functional protein binders with BindCraft的论文。

Macaron(马卡龙)AI 最近挺火的。 8 月 15 日,他们以「世界上第一个 Personal Agent」的称号公开上线了,给扎克伯格想做的 Personal SuperIntelligence 打了个样。