
告别「盲目自信」,CCD:扩散语言模型推理新SOTA
告别「盲目自信」,CCD:扩散语言模型推理新SOTA扩散语言模型(Diffusion Language Models)以其独特的 “全局规划” 与并行解码能力广为人知,成为 LLM 领域的全新范式之一。然而在 Any-order 解码模式下,其通常面临
来自主题: AI技术研报
8097 点击 2025-12-13 10:59
 搜索
搜索
扩散语言模型(Diffusion Language Models)以其独特的 “全局规划” 与并行解码能力广为人知,成为 LLM 领域的全新范式之一。然而在 Any-order 解码模式下,其通常面临

来自中国的初创团队词元无限给出了自己的答案。由清华姚班校友带队设计开发的编码智能体 InfCode,在 SWE-Bench Verified 和 Multi-SWE-bench-CPP 两项非常权威的 AI Coding 基准中双双登顶,力压一众编程智能体。

昨天晚上打开蚂蚁那个灵光,发现他们更新了一个很有趣的东西。

在大语言模型(LLM)的研究浪潮中,绝大多数工作都聚焦于优化模型的输出分布 —— 扩大模型规模、强化分布学习、优化奖励信号…… 然而,如何将这些输出分布真正转化为高质量的生成结果 —— 即解码(decoding)阶段,却没有得到足够的重视。

「Vibe Coding 肯定是有 PMF 的,但 Vibe Coding 产品其实还没找到自己的 PMF。」AI Coding 明星产品 Lovable 的增长负责人 Elena Vera,在一次采访中明确说道。来自 The Information 数据,以 Cursor、Claude Code 为代表的 AI Coding 工具的累计营收,已经突破了 31 亿美元。

2025 年以来,各种 AI Coding 的宣发,已经从科技进步,快进到了科幻文学赛道。C 端市场,一句话生成 Demo 的宣发内容仍在收割流量,将技术演进包装成科幻叙事;但没人关心小白为什么要做 coding,一句话生成的的 demo,在生产环境能跑起来吗?
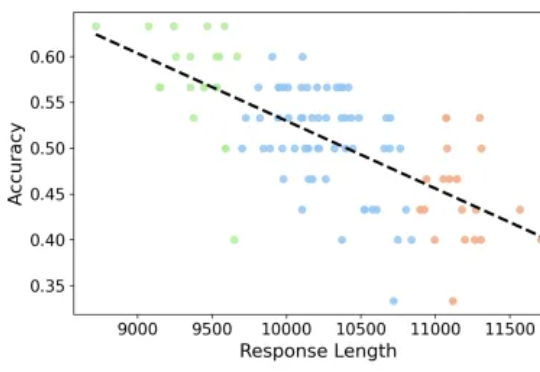
专注推理任务的 Large Reasoning Models 在数学基准上不断取得突破,但也带来了一个重要问题:越想越长、越长越错。本文解读由 JHU、UNC Charlotte 等机构团队的最新工作
想搭一个 AI 应用,就一定要走 Coding 这条路吗? 最近我干了件事:只用了一个飞书多维表格,把一堆 AI 效率产品的事给办了。起因是飞书多维表格全面上线了新功能,「应用模式」和「AI 工作流」。
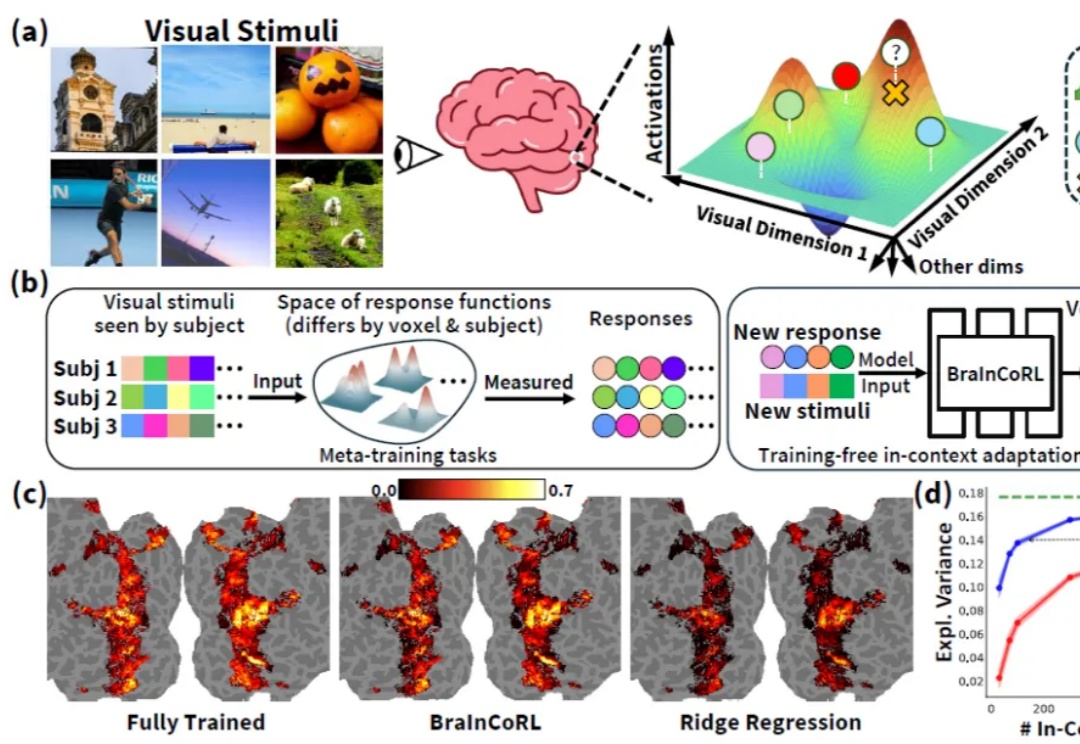
人类高级视觉皮层在个体间存在显著的功能差异,而构建大脑编码模型(brain encoding models)—— 即能够从视觉刺激(如图像)预测人脑神经响应的计算模型 —— 是理解人类视觉系统如何表征世界的关键。传统视觉编码模型通常需要为每个新被试采集大量数据(数千张图像对应的脑活动),成本高昂且难以推广。
一年半之前,影眸科技年轻的创始团队去到旧金山,带着还没正式发布的 3D 生成模型 Rodin,在 GDC(游戏开发者大会)上向全球最顶级的游戏开发者们演示 demo。