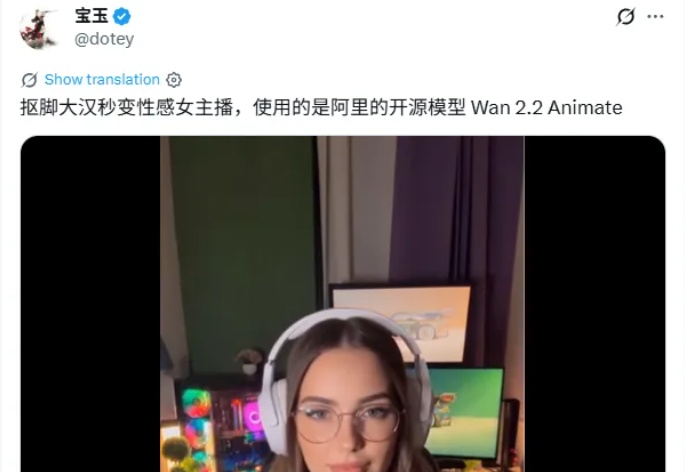
Wan2.2-Animate又火了,5分钟让抠脚大汉秒变高冷女神。
Wan2.2-Animate又火了,5分钟让抠脚大汉秒变高冷女神。最近,一个视频在推上传疯了。
来自主题: AI资讯
9761 点击 2025-10-30 11:47
 搜索
搜索
最近,一个视频在推上传疯了。
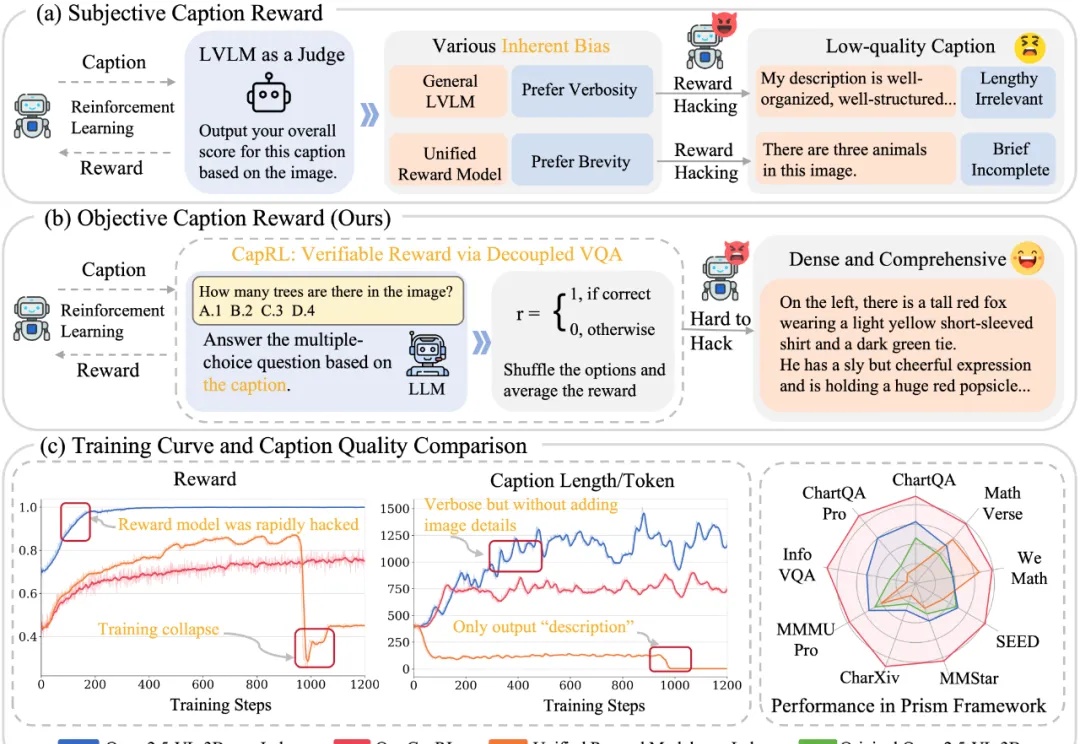
今天推荐一个 Dense Image Captioning 的最新技术 —— CapRL (Captioning Reinforcement Learning)。CapRL 首次成功将 DeepSeek-R1 的强化学习方法应用到 image captioning 这种开放视觉任务,创新的以实用性重新定义 image captioning 的 reward。
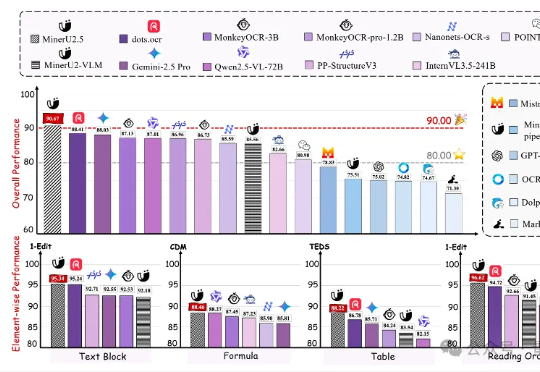
上海人工智能实验室发布新一代文档解析大模型——MinerU2.5。作为MinerU系列最新成果,该模型仅以1.2B参数规模,就在OmniDocBench、olmOCR-bench、Ocean-OCR等权威评测上,全面超越Gemini2.5-Pro、GPT-4o、Qwen2.5-VL-72B等主流通用大模型,以及dots.ocr、MonkeyOCR、PP-StructureV3等专业文档解析工具。
Veo 3真正对手,竟不是Sora 2!通义万相2.5全网首发,直接甩出王炸:一句话,直出10秒1080P电影级视频,首次实现音画精准同步。一键生成BGM、人声,全网实测玩疯。
夸克“造点”AI发布了!直接上大招,Wan2.5+Midjourney V7双强模型联合!夸克“造点”还在今天第一时间,率先接入了阿里自家刚刚发布的视频生成模型通义万相Wan2.5,甚至直接开放了7天免费体验。

挑战自回归的扩散语言模型刚刚迎来了一个新里程碑:蚂蚁集团和人大联合团队用 20T 数据,从零训练出了业界首个原生 MoE 架构扩散语言模型 LLaDA-MoE。该模型虽然激活参数仅 1.4B,但性能可以比肩参数更多的自回归稠密模型 Qwen2.5-3B,而且推理速度更快。这为扩散语言模型的技术可行性提供了关键验证。
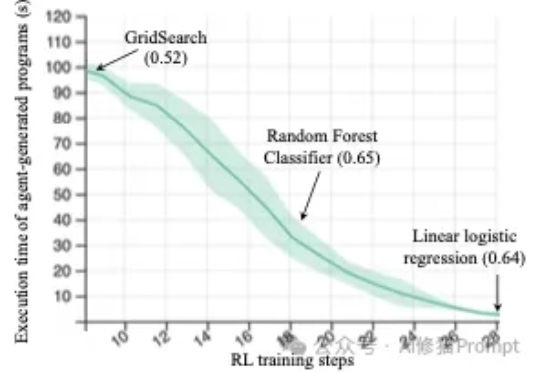
来自斯坦福的研究者们最近发布的一篇论文(https://arxiv.org/abs/2509.01684)直指RL强化学习在机器学习工程(Machine Learning Engineering)领域的两个关键问题,并克服了它们,最终仅通过Qwen2.5-3B便在MLE任务上超越了仅依赖提示(prompting)的、规模更大的静态语言模型Claude3.5。
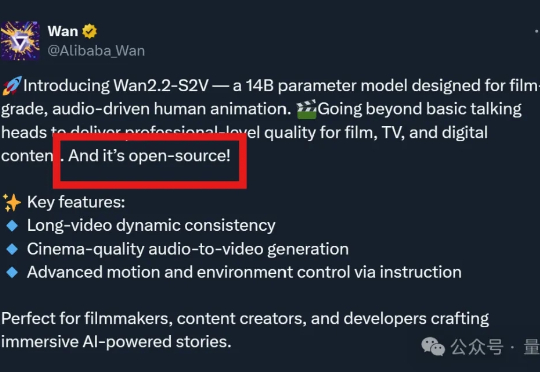
AI视频生成正在迎来“通义时刻”! 就在昨夜,阿里突然发布了一款由音频驱动的14B视频模型Wan2.2-S2V—— 仅需一张图片和一段音频,即可生成面部表情自然、口型一致、肢体动作丝滑的电影级数字人视频。
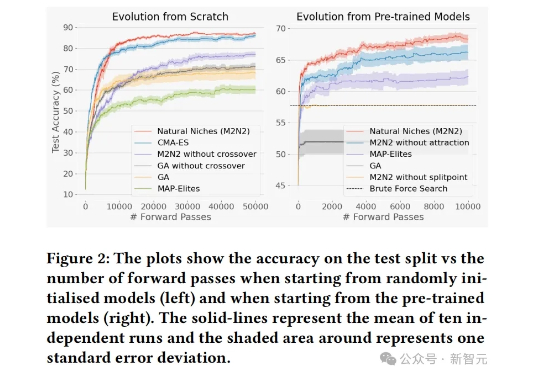
Sakana AI以自然演化为灵感,提出了一种全新的模型融合进化方法M2N2。通过引入自然界的「择偶机制」,AI可以像生物一样「竞争、择偶、繁衍」。在当前全球算力短缺、模型训练实际规模受制的情况下,Sakana AI借助自然界的启示,为模型融合探索出了一条新路。

今天,我们正式开源 8B 参数的面壁小钢炮 MiniCPM-V 4.5 多模态旗舰模型,成为行业首个具备“高刷”视频理解能力的多模态模型,看得准、看得快,看得长!高刷视频理解、长视频理解、OCR、文档解析能力同级 SOTA,且性能超过 Qwen2.5-VL 72B,堪称最强端侧多模态模型。