
首发| 成立10个月,GIM拿下Monolith、赛富投资
首发| 成立10个月,GIM拿下Monolith、赛富投资致力于成为金融界“DeepSeek”。金融垂域大模型公司Grace Investment Machine(简称GIM)宣布一连完成过亿元天使轮和天使+轮融资。成立于2025年7月,GIM正在做一件事:为金融行业打造一个垂直领域的DeepSeek——专为投资决策而生的推理大模型。
来自主题: AI资讯
9282 点击 2026-06-08 10:47
 搜索
搜索
致力于成为金融界“DeepSeek”。金融垂域大模型公司Grace Investment Machine(简称GIM)宣布一连完成过亿元天使轮和天使+轮融资。成立于2025年7月,GIM正在做一件事:为金融行业打造一个垂直领域的DeepSeek——专为投资决策而生的推理大模型。

随着大模型智能体深入渗透真实操作系统,一种全新的安全威胁悄然成型:行为越狱(Behavior Jailbreak)。现有安全基准只盯着模型「说了什么」,却对「做了什么」视而不见。新基准LITMUS是首个同时覆盖真实OS环境行为越狱、语义-物理双层验证与多攻击范式的完整评测体系,并首次系统量化了「执行幻觉」这一被整个评测社区忽视的致命盲区。

AI抗衰药物研发公司「无尽方舟」已完成数千万元种子轮融资,Monolith领投,九合创投跟投。此次融资将主要用于加速核心药物的工程化生产与猫狗临床验证,并同时推进H2P跨物种平台及干湿结合药物研发平台两大AI系统的建设。

《读佳》获知,蚂蚁集团低调推出一款叫做 “Willit”的AI眼镜产品,且已在淘宝上线,眼镜适配的 “Willit AI”APP亦同步在应用市场上线。此外,适配的“Willit AI”APP已上架部分应用商店,应用宝显示其开发商、运营商、主办者均为萨思数字科技(北京)有限公司
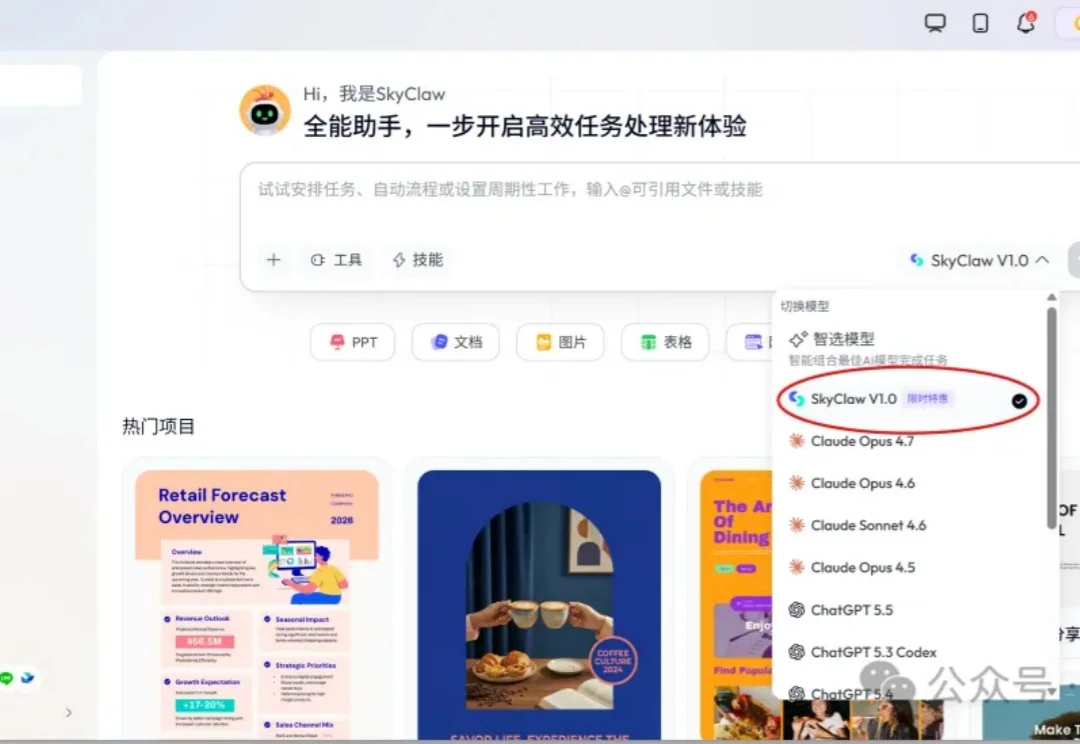
谁懂啊家人们??

光有强大的模型本身还不够,从脏数据到分析报告到汇报PPT,中间那条自动化链路谁来跑?GitHub上刚开源的SenseNova-Skills给出了一个答案,我们实测了四个真实场景,效果有点超出预期。

近日,能量桥科技(上海)有限公司(以下简称“能量桥”)宣布完成新一轮融资,由 Monolith 砺思资本领投,中科创星跟投。

近日,字节跳动智能创作部门(Intelligent Creation Lab)提出新作 DreamLite,一个主干网络仅有 0.39B 参数的轻量级统一扩散模型,在单一网络内同时支持文生图(Text-to-Image) 和图像编辑(Text-guided Image Editing)两个任务,是目前已知首个实现这一能力的端侧模型。
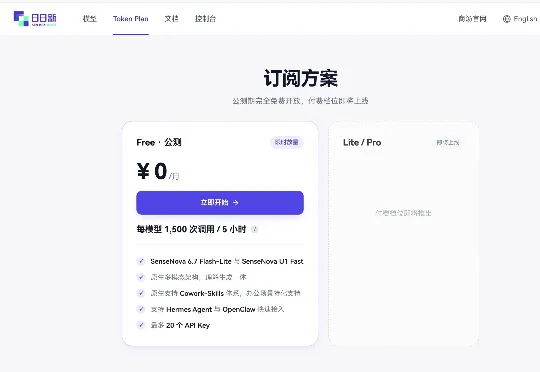
商汤最近做了一件大多数大模型公司都不舍得做的事。每 5 小时 1500 次免费调用,Token 消耗比同行低 60%,三款新产品同步上线,还把核心模型 U1 以 Apache 2.0 协议全面开源——在大模型公司普遍在想怎么收费的当下,商汤在反向操作。

SenseNova U1 是商汤最新发布的一个开源的多模态模型,它的 Lite 系列 8B 和 A3B 参数版本,目前已经在 Hugging Face 和 GitHub 上开源。APPSO 也提前拿到了测试资格,我们发现商汤这款新一代原生理解生成统一模型,就开源模型来说,已经做到了最好水平。