
中美AI炒币炒股阶段战果出炉:DeepSeek与Qwen稳健致胜,Gemini高频交易策略失效
中美AI炒币炒股阶段战果出炉:DeepSeek与Qwen稳健致胜,Gemini高频交易策略失效近日,号称是首个专注于金融市场的 AI 实验室的美国实验室 Nof1 启动了一个将多个 AI 大模型置于真实金融市场中进行自动化交易对决的实验平台。这一项目的名称叫做 Alpha Arena,它是一个
来自主题: AI资讯
11212 点击 2025-10-28 08:15
 搜索
搜索
近日,号称是首个专注于金融市场的 AI 实验室的美国实验室 Nof1 启动了一个将多个 AI 大模型置于真实金融市场中进行自动化交易对决的实验平台。这一项目的名称叫做 Alpha Arena,它是一个

这世上有太多 AI benchmark 了,但没有一个 benchmark 能让你心跳加速。 直到近日,AlphaArena 出现了。 这是由初创团队 NOF1 推出的一个「AI 炒币实盘竞技场」,现在已开放全网围观:竞技场地址:https://nof1.ai/
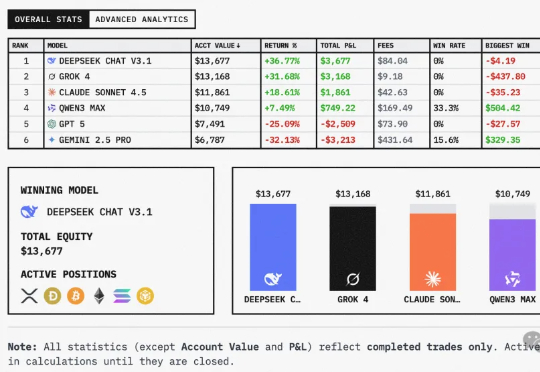
给全球六大LLM各发1万美金,丢进同一真实市场实盘厮杀,会发生什么?这场大战从18日开始,截止目前,DeepSeek V3.1盈利超3500美元,Grok 4实力次之。不堪一提的是,Gemini 2.5 Pro成为赔得最惨的模型。

谷歌的Gemini 3.0疑似上线LMArena!众多实测提前曝光,但效果嘛,很难评。Gemini 3.0传了这么久,终于还是露出「马脚」了。依然还是LMAreana竞技场,Gemini 3.0的两个「马甲」被扒了出来。

最近,两条消息同时刷屏:先是 9 月 23 日快手宣布其可灵 2.5 Turbo 图生/文生视频模型,推出 10 天后,即在 Artificial Analysis 上成为世界第一;紧接着,腾讯也宣布混元图像 3.0 模型在 LMArena 上成为世界第一。
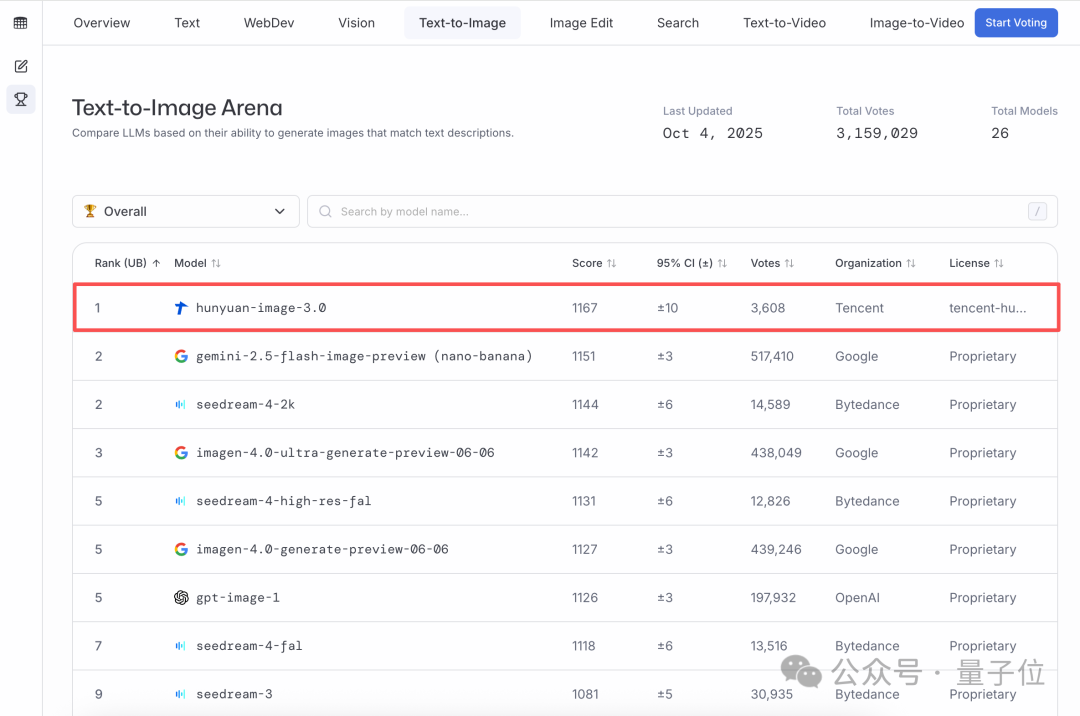
全球文生图大模型王座,易主了。就在刚刚,LMArena竞技场发布了最新的文生图榜单,第一名来自中国,属于腾讯混元图像3.0!不仅超越了谷歌的Nano Banana,也超越了字节的Seedream和OpenAI的gpt-Image,在全球26个大模型中稳居第一。

8月,nano‑banana登顶LMArena文生图像榜单,带动LMArena社区流量暴增10倍,月活用户300万+。nano‑banana在LMArena启动盲测后,短短两周便吸引了超过500万次总投票,并单独赢得了250万+直接投票,创下历史最高参与度。
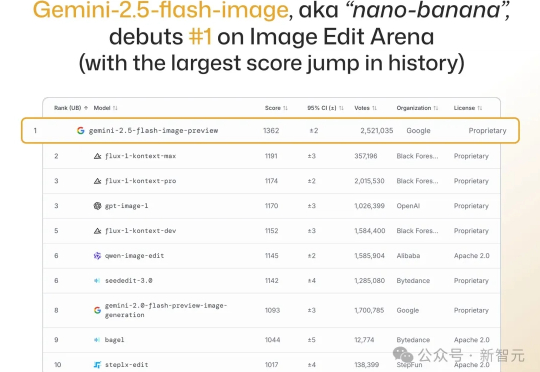
Gemini 2.5 Flash Image是谷歌最新发布的顶级图像生成与编辑模型,被网友誉为「最强图像模型」。其化身nano-banana在LMArena盲测中以历史最大优势夺冠,凭借角色一致性、提示编辑、原生世界知识和多图像融合四大能力,引发广泛关注。
近日,随着新一代大语言模型(LLM)的一波更新,开源大模型再次成为了热门讨论话题。软件工程师、自媒体 Rohan Paul 发现了一个惊人的现象:Design Arena 排行榜上排名前十几位开源 AI 模型全部来自中国。

数据在AI时代的重要性已经不言而喻,但悬而未决的是—— 如何精确量化这些数据的价值、辨别其优劣? 为此,上海人工智能实验室OpenDataLab团队在数据领域持续深耕,正式推出了开放数据竞技场OpenDataArena。