
谷歌真急了!深夜更新Deep Research智能体,支持MCP、原生图表
谷歌真急了!深夜更新Deep Research智能体,支持MCP、原生图表谷歌真是急了。 前脚刚传来消息,称谷歌联合创始人谢尔盖·布林重启“创始人模式”,亲自督战并组建精英“突击队”,全力提升Gemini在AI编程和自主智能体等关键能力上追赶Anthropic等对手。 后脚
来自主题: AI资讯
7844 点击 2026-04-22 10:43
 搜索
搜索
谷歌真是急了。 前脚刚传来消息,称谷歌联合创始人谢尔盖·布林重启“创始人模式”,亲自督战并组建精英“突击队”,全力提升Gemini在AI编程和自主智能体等关键能力上追赶Anthropic等对手。 后脚
刚刚,图灵联合创始人刘江在海外社交媒体X上透露,DeepSeek核心研究院——郭达雅已加入字节跳动。 郭达雅2023年博士毕业后加入DeepSeek,title是AI Researcher。公开论文显示,从 DeepSeek-Coder、DeepSeek-Math、DeepSeek-Prover、DeepSeek-V3到 DeepSeek-R1,他都出现在核心作者名单中。

1997年深蓝下棋,2016年AlphaGo围棋,2026年9个Claude副本做真实科研……每次我们都说「只是特定领域」。这一次,我们真的还能说什么?欢迎来到AI成为科研同事、竞争者、甚至继任者的时代。

近日,哈尔滨工业大学(深圳)联合深圳河套学院、Independent Researcher提出了隐式思考模型 LRT(Latent Reasoning Tuning),通过一个轻量级的推理网络,将大模型冗长的「思维链」压缩为紧凑的隐式向量表征,一次前向计算即可完成推理,无需逐 token 生成数千字的中间推理过程。

这个爆火的开源项目,叫做 Hermes Agent,地址:https://github.com/NousResearch/hermes-agent是由 Nous Research 团队倾力打造的开源Agent。

过去两年,图像生成模型在质感和审美上一路狂飙,但大多仍是 “直接出图” 的范式。
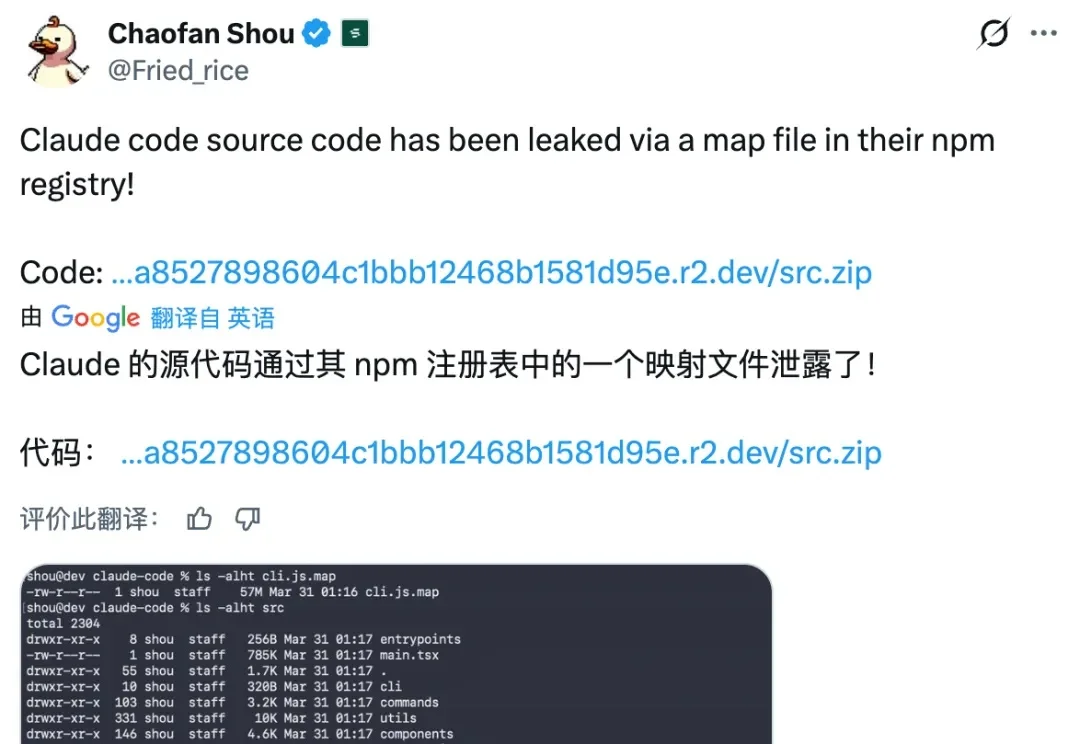
Claude Code 源码被泄露了。率先发现并公开披露这一「漏洞」的,是开发者 Chaofan Shou(寿超璠)。开发者 @realsigridjin 动作极快,第一时间将泄露的源码备份至 GitHub,仓库名为 instructkr/claude-code,标注为「Claude Code Snapshot for Research」。

3 月 16 日,在刚刚结束的 NVIDIA GTC 2026 大会上,黄仁勋在长达三小时的 Keynote 演讲中发布了 NVIDIA Agent Toolkit 和 AI-Q 开放智能体蓝图,将 AI Agent 定位为下一个重大前沿。

具身数据层的全球竞赛正在迅速升温。NVIDIA Research在2026年发布EgoScale数据与训练框架,在Ego-centric人类操作视频上训练VLA模型,用 20,854小时带动作标注的第一人称人类视频,观察到数据规模和验证损失之间接近对数线性的scaling law。1X收集人类第一视角及家庭行为数据,通过 Sunday项目采集百万小时级家庭场景视频。
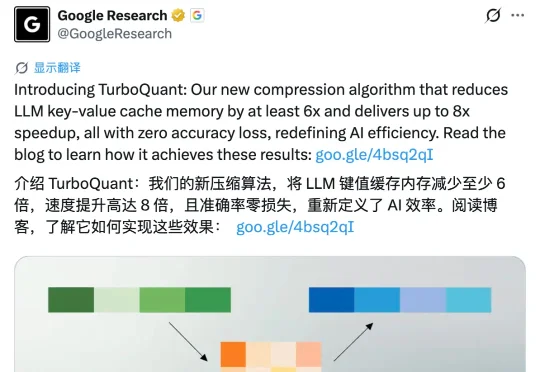
前几天,Google Research 在 X 平台正式发布了名为 TurboQuant 的 AI 压缩算法,24 小时内浏览量破千万。但就在刚刚,苏黎世联邦理工学院博士后高健扬在知乎发出一封公开澄清信。他是论文里被比较算法 RaBitQ 的第一作者,指出 TurboQuant 存在三处严重问题: