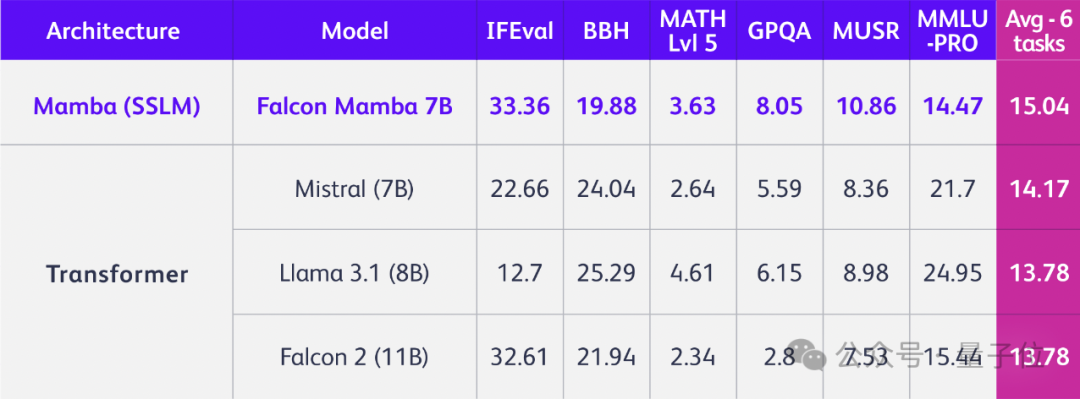
换掉Transformer,7B开源模型立刻登顶!任意长序列都能处理
换掉Transformer,7B开源模型立刻登顶!任意长序列都能处理只是换掉Transformer架构,立马性能全方位提升,问鼎同规模开源模型!
来自主题: AI资讯
8804 点击 2024-08-13 16:47
 搜索
搜索
只是换掉Transformer架构,立马性能全方位提升,问鼎同规模开源模型!

今年 3 月份,英伟达 CEO 黄仁勋举办了一个非常特别的活动。他邀请开创性论文《Attention Is All You Need》的作者们齐聚 GTC,畅谈生成式 AI 的未来发展方向。

2017 年,谷歌在论文《Attention is all you need》中提出了 Transformer,成为了深度学习领域的重大突破。该论文的引用数已经将近 13 万,后来的 GPT 家族所有模型也都是基于 Transformer 架构,可见其影响之广。 作为一种神经网络架构,Transformer 在从文本到视觉的多样任务中广受欢迎,尤其是在当前火热的 AI 聊天机器人领域。
爆款AI应用开发者来晒收入了:

在过去的几年中,大型语言模型(Large Language Models, LLMs)在自然语言处理(NLP)领域取得了突破性的进展。这些模型不仅能够理解复杂的语境,还能够生成连贯且逻辑严谨的文本。

如果我们今天要谈论科技或风险投资,那么接下来的话题只会让我们想到 AI.
多模态大语言模型 (Multimodal Large Language Moodel, MLLM) 以其强大的语言理解能力和生成能力,在各个领域取得了巨大成功。

RLHF到底是不是强化学习?最近,AI大佬圈因为这个讨论炸锅了。和LeCun同为质疑派的Karpathy表示:比起那种让AlphaGo在围棋中击败人类的强化学习,RLHF还差得远呢。

专注于计算机图形学的全球学术顶会 SIGGRAPH,正在出现新的趋势。

七年前,论文《Attention is all you need》提出了 transformer 架构,颠覆了整个深度学习领域。