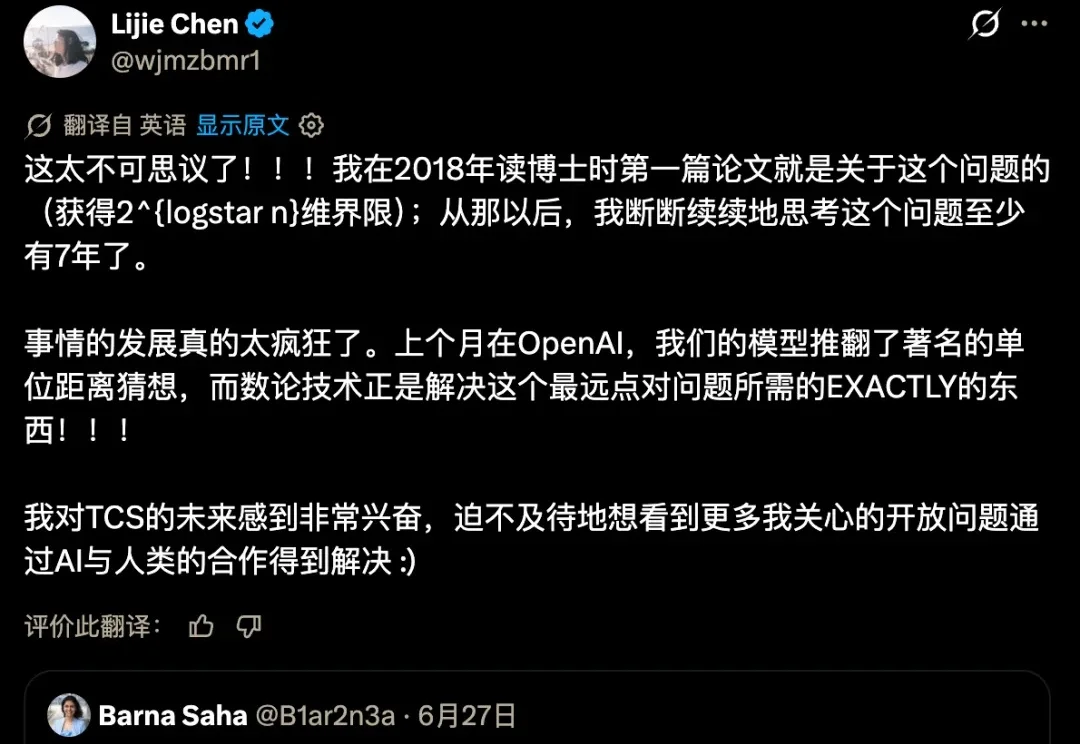
刚刚,姚班传奇陈立杰苦思7年的计算几何核心难题,被ChatGPT推翻了
刚刚,姚班传奇陈立杰苦思7年的计算几何核心难题,被ChatGPT推翻了GPT-5.5 Pro 生成了一个数学证明,解决了计算几何中一个 陈立杰苦思 7 年未解的核心难题。关键技术来自 OpenAI 上月的另一项突破,而最初推进这个问题的陈立杰发现,钥匙竟是自己参与的工作。
来自主题: AI资讯
5623 点击 2026-06-29 15:57
 搜索
搜索
GPT-5.5 Pro 生成了一个数学证明,解决了计算几何中一个 陈立杰苦思 7 年未解的核心难题。关键技术来自 OpenAI 上月的另一项突破,而最初推进这个问题的陈立杰发现,钥匙竟是自己参与的工作。

中国空调,在欧洲被抢疯了。

在世界模型这条路上,行业一直卡在一个几乎无解的矛盾里:想要更真实的长程模拟,就必须给模型更深的计算;可一旦把模型做得更深,部署成本、参数规模和误差累积又会迅速抬头。结果就是,大家都知道世界模型要 “想得更久”,却很难让它在现实系统里 “算得起、跑得稳”。
这个周末,智谱没闲着。
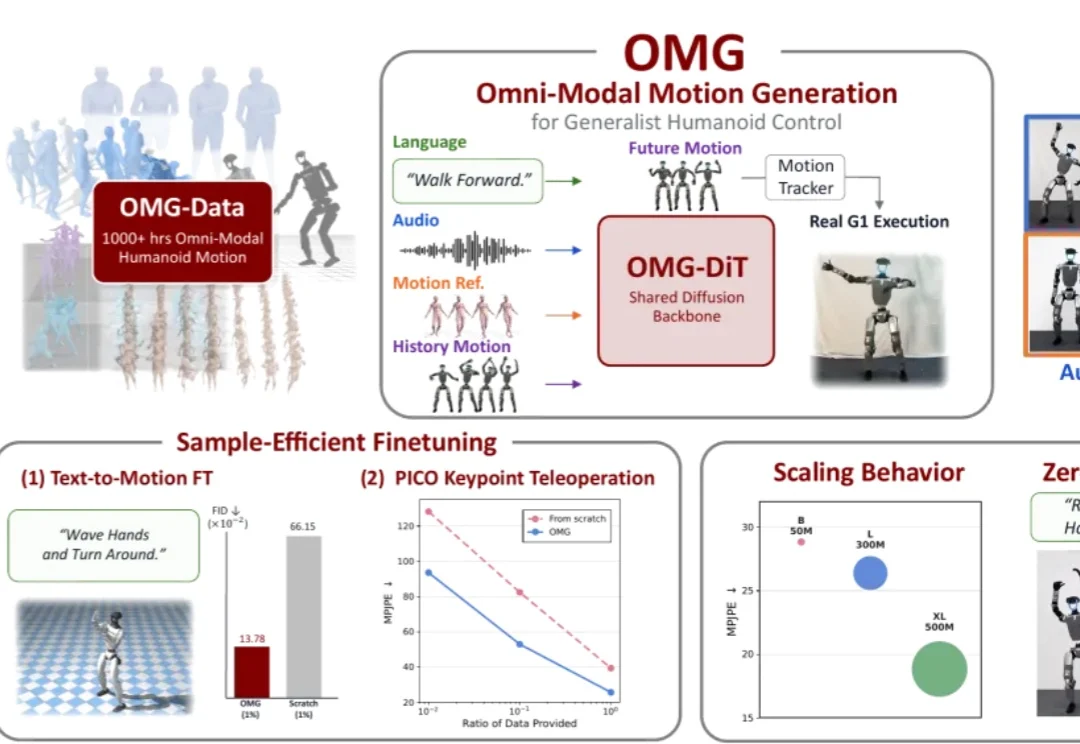
现阶段大多数人形机器人的运动控制还局限于 “有参考才能动” 的被动跟踪模式。
自从 6 月 1 日宣布全部旗下旗舰模型 API 免费之后,文本、图片、视频这三个模型我都一直在用,确实帮我省了很多钱,同时模型能力也不错。而最近,Agnes AI 又双叒叕搞了个新平台:Pavo。
最近另一个叫「马尾辫」的项目在 GitHub 上开始被疯狂下载,直接拿下了 GitHub 热门榜单连续三周的周榜第一。这个项目的介绍图也特别有意思,在项目描述里写着,你一定认识他,长长的马尾辫,椭圆形眼镜,在公司待的时间比版本控制系统的历史还长。你给他看五十行代码;他看了看,什么也没说,然后只用一行替换掉。

最近,这个AI穿越Vlog刷爆全网!第一视角空降古罗马、泰坦尼克号,逼真到窒息。历史次元壁被打破的那一瞬间,很多「亲历现场」的观众,开始落泪了。

什么是AI原生支付?随着全世界个体token的消耗量猛增,越来越多的大玩家和初创公司开始瞄准AI支付机制和基础设施的问题。

2026年6月,全球AI算力产业最焦虑的事情,不是英伟达Rubin能不能按时出货,也不是台积电CoWoS产能够不够——而是一台大多数人根本没听说过的机器:日本丰田工业的喷气织布机。