多亏Transformer,Mamba更强了!仅用1%计算量达新SOTA
多亏Transformer,Mamba更强了!仅用1%计算量达新SOTAAttention is all you need.
来自主题: AI技术研报
11560 点击 2024-08-22 16:44
 搜索
搜索
Attention is all you need.

MidReal 创始人陈锴杰,持续创业者,大学毕业后一直在创业,从18 ~19 年休学创业做家庭智能机器人,到2020 年开始第二次创业做 AI agent for Gaming,曾基于 GPT-2 等技术,在 ChatGPT 推出前实现“斯坦福小镇”等创新游戏模式,目前在做的是 AI 互动的小说故事创作,也就是今天的 MidReal。

随着大模型研究的深入,如何将其推广到更多的模态上已经成为了学术界和产业界的热点。最近发布的闭源大模型如 GPT-4o、Claude 3.5 等都已经具备了超强的图像理解能力,LLaVA-NeXT、MiniCPM、InternVL 等开源领域模型也展现出了越来越接近闭源的性能。

当一家人工智能公司的首席执行官更像是计算机科学家而不是推销员时,我感觉更舒服
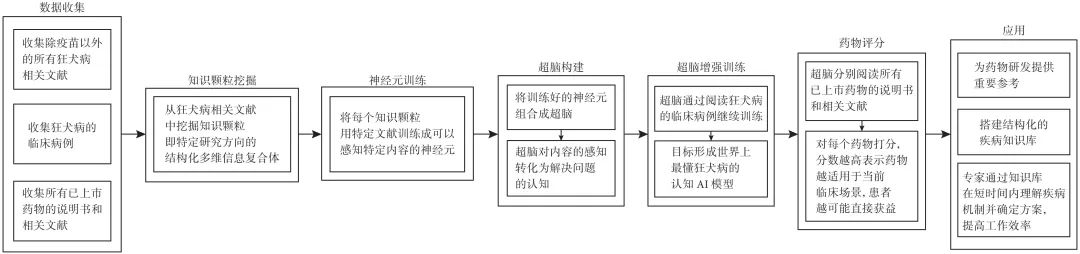
在当今数字化时代,人工智能(artificial intelligence,AI)技术迅猛发展,尤其是生成式技术,如ChatGPT(chat generative pre-trained transformer),对人类生活的影响日益深远。
麦当劳用AI制作的宣传片火了!

越来越多研究发现,后训练对模型性能同样重要。Allen AI的机器学习研究员Nathan Lambert最近发表了一篇技术博文,总结了科技巨头们所使用的模型后训练配方。

国产AI社交产品太会玩儿
近日,HCM领域的SaaS巨头Workday和全球排名第一的CRM企业Salesforce达成AI战略合作,意在结合Salesforce在客户关系管理领域方面的专业知识以及Workday在人力资源、财务管理方面的优势,试图通过当下先进的人工智能功能和统一的数据集成技术重新构想全新的企业软件。

无需硬件传感器或对现有网络环境进行重大改动即可轻松部署。