
判断力的无产阶级:AI时代的认知分层已经开始了
判断力的无产阶级:AI时代的认知分层已经开始了硅谷创投哲学家纳瓦尔·拉维坎特(Naval Ravikant)有一个著名的论断,令人印象深刻:“在一个拥有无限杠杆的世界里,判断力是最重要的技能。”我们一直以来对AI的忧虑——失业、偏见、安全……,或许都只是冰山浮出水面的部分。海面之下,一个更巨大、更隐蔽的变革正在发生。
来自主题: AI资讯
8034 点击 2026-07-05 09:58
 搜索
搜索
硅谷创投哲学家纳瓦尔·拉维坎特(Naval Ravikant)有一个著名的论断,令人印象深刻:“在一个拥有无限杠杆的世界里,判断力是最重要的技能。”我们一直以来对AI的忧虑——失业、偏见、安全……,或许都只是冰山浮出水面的部分。海面之下,一个更巨大、更隐蔽的变革正在发生。
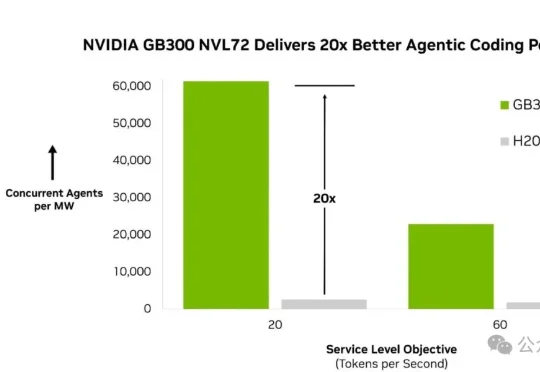
同样一兆瓦电,英伟达最新的GB300 NVL72能同时扛住61400个智能体,上一代H200只扛得住大约2600个。这中间,差了整整20倍。它就是独立评测机构Artificial Analysis发布的新基准:AA-AgentPerf。

“Opus是好模型,但Fable 5比它好十倍。”Alex说。他建议开发者把过去两周Fable下架期间写的所有代码,全部丢给Fable 5进行重新审查,目的是看看有没有安全漏洞、性能不够的地方、或者写得太粗糙但可以修改好的逻辑。

LinStereo 对应地做了三件事:PALA 换掉 ConvGRU 解决传播问题,HSCV 保留多尺度特征,DPI 用单目深度给一个靠谱的起点。PALA 做的事情说起来很直观,就是把 ConvGRU 的局部更新换成全局注意力,让每个像素每次迭代都能看到整张图。难点在于 softmax attention 是 O (N²) 的,直接用在高分辨率视差图上跑不动。

来自上海交大、马来亚大学、CMU、MBZUAI、KIT和KAUST的团队提出VisNec(Visual Necessity Score,视觉必要性分数),用一个分数衡量每条训练样本里“图像到底起了多大作用”,被ECCV 2026收录。
史上最严厉的一次清洗来了。就在昨天,外媒Financial Times突然曝出消息:Anthropic正在全面下狠手,疯狂清剿允许绕过限制访问Claude的所有地下通道!

华大智造子公司涌生智能×上海人工智能实验室,联合发布两项新成果:ProtoPilot:一款由真实实验室场景驱动的自进化多智能体系统;BioLab Bench:生命科学领域首个从用户需求到设备可执行的全流程Agent评测体系。

还在聊Sim2Real?现在机器人圈更火的是Real2Sim!最近,英伟达GEAR联合李飞飞团队、佐治亚理工大学等机构联合发布全新Real2Sim系统——SimFoundry。SimFoundry只需一段真实世界视频,就能自动生成一个可以交互、训练、评测的机器人仿真环境。
前段时间我做了一个 guizang-social-card-skill(https://github.com/op7418/guizang-social-card-skill)。

昨天,消息说孙天祥加入百度,担任基础模型研发部(BMU)负责人。「elsewhere」最开始知道孙天祥,还是投资人韩锐跟我们说的。大概一年半之前,他说他投资了一个“young talent”,就是1997年的孙天祥。当时他刚离开阳陆育的公司。