GLM-5真够顶的:超24小时自己跑代码,700次工具调用、800次切上下文!
GLM-5真够顶的:超24小时自己跑代码,700次工具调用、800次切上下文!当看到GLM-5正式发布后的能力,才惊觉前几天神秘模型Pony Alpha的热度还是有点保守了。
来自主题: AI技术研报
7040 点击 2026-02-13 12:08
 搜索
搜索
当看到GLM-5正式发布后的能力,才惊觉前几天神秘模型Pony Alpha的热度还是有点保守了。

就是说,这几天还有哪档晚会节目是没有机器人现身的吗?
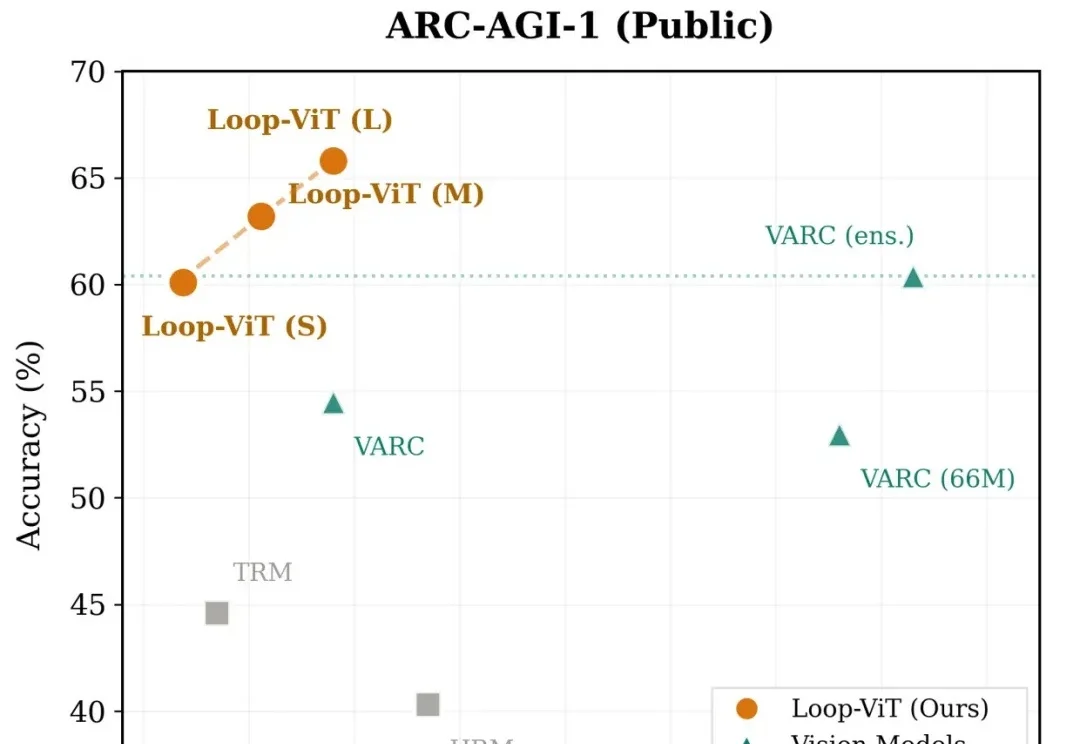
当我们解一道复杂的数学题或观察一幅抽象图案时,大脑往往需要反复思考、逐步推演。然而,当前主流的深度学习模型却走的是「一次通过」的路线——输入数据,经过固定层数的网络,直接输出答案。
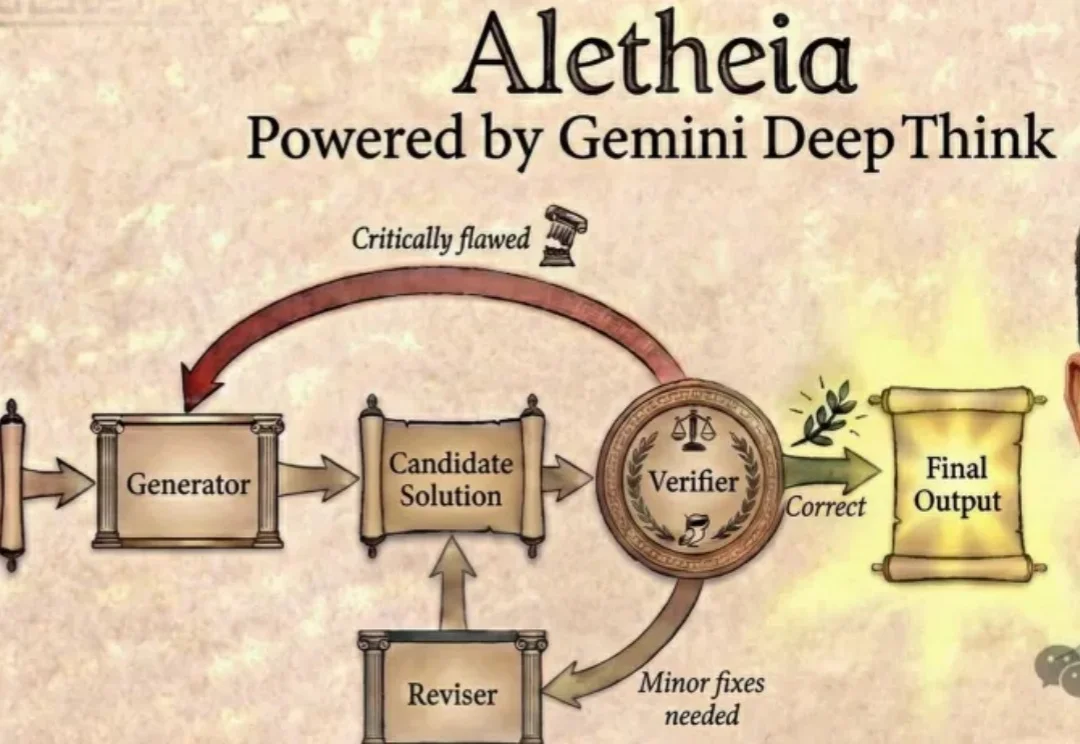
今天,谷歌DeepMind「AI数学家」Aletheia彻底杀疯了,攻克数学猜想,独立写论文。更令人震惊的是,拿下金牌的Gemini一举横扫18大核心科研难题。
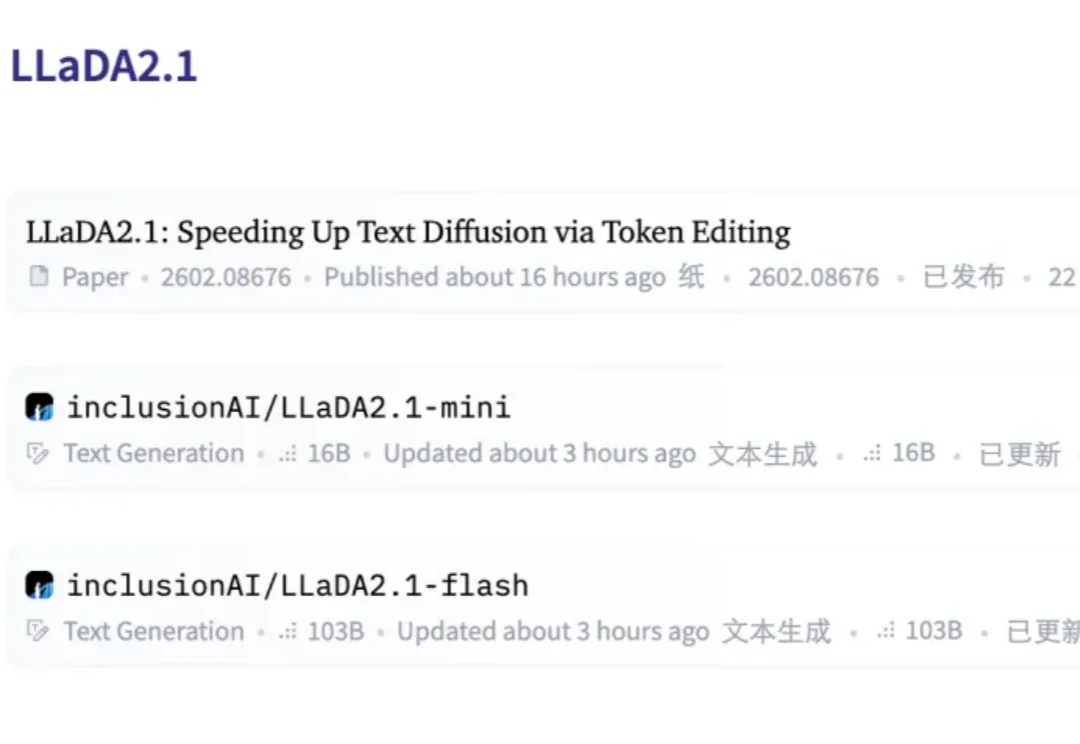
扩散语言模型(dLLM),这个曾被认为是「小众赛道」的研究方向,如今终于迎来了质变。

Anthropic刚刚扔出一份18页重磅炸弹:《2026年智能体编码趋势报告》。结论直接炸裂:程序员不再写代码了,他们变成了「指挥官」。

BUBBLE 2026 — ISSUE #18 家人们, 马上没几天快过年了,明显各个厂商已经开始疯狂卷了。 上周到现在,让我们来算算有多少东西了, 5.3 Codex,4.6 Opus, 可灵3.0

谁能想到啊,在自回归模型(Autoregressive,AR)当道的现在,一个非主流架构的模型突然杀了回马枪——被长期视为学术玩具的扩散语言模型,直接在复杂编程任务中飙出了892 tokens/秒的速度!
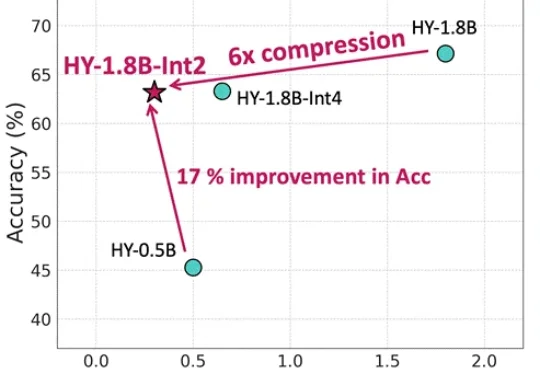
等效参数量仅0.3B,内存占用仅600MB,更适合端侧部署还带思维链的模型来了。腾讯混元最新推出面向消费级硬件场景的“极小”模型HY-1.8B-2Bit,体量甚至比常用的一些手机应用还小。

以DeepSeek R1为代表的一系列基于强化学习(RLVR)微调的工作,显著提升了大语言模型的推理能力。但在这股浪潮背后,强化微调的代价却高得惊人。