
Gemini帮记者卖房,5天成交、多赚60万,还差点踩雷
Gemini帮记者卖房,5天成交、多赚60万,还差点踩雷最近,北京一套27平米的胡同老房子靠AI成功翻了盘。
来自主题: AI资讯
7203 点击 2026-06-15 13:49
 搜索
搜索
最近,北京一套27平米的胡同老房子靠AI成功翻了盘。

朋友们,Kimi 又更新了。
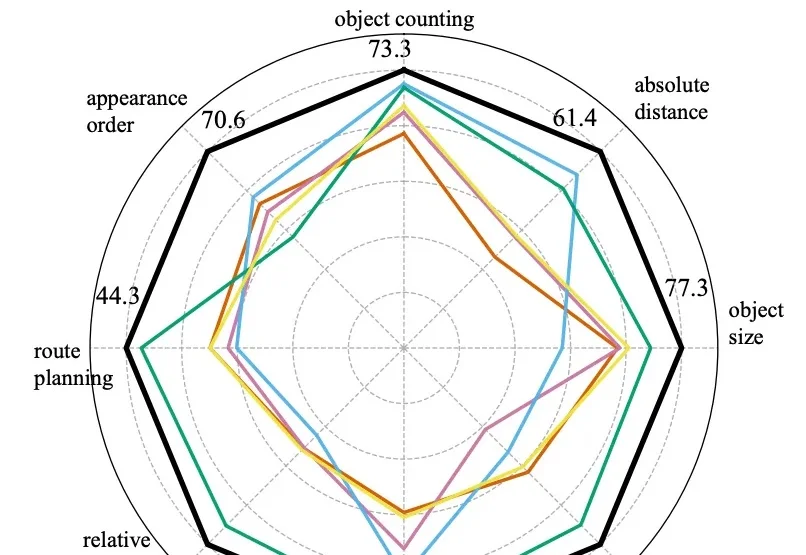
大模型已经能流畅对话、看图识物,但一个更底层的问题始终没被真正解决——它们是否「理解」了我们所处的三维世界?
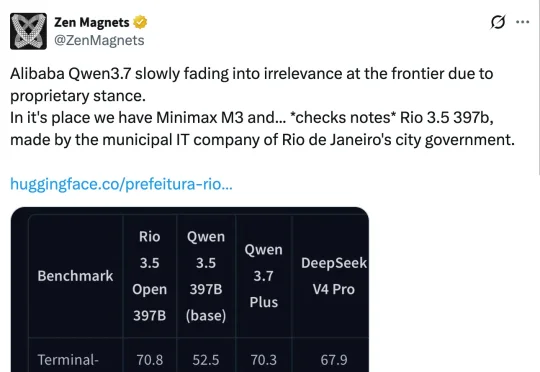
今天,除了全球(非美)被禁的 Claude Fable 5,AI 社区还被一个开源模型刷屏了。有推特博主发现,一个由巴西里约热内卢市政府旗下 IT 公司开源的模型 Rio 3.5 397B,在多项基准测试中超越了 Qwen 3.7 Plus 等开源模型,而这个模型的基础模型还是 Qwen3.5-397B-A17B。

观点跃迁研发了全球首个Text to Device AI电子设备生成平台STACK ANYWAY,旨在打通从“任意想法”到“现实硬件”的端到端链路。据观点跃迁估算,在海量的硬件SKU中,至少70%-80%属于硬件原型阶段,而这些原型实际上撬动了规模更大的量产硬件市场。整个硬件原型开发相关市场规模粗略估算已达上百亿美元。

谷歌DeepMind宣布:AGI,已经过时了!就在最近,谷歌DeepMind出了一份干货满满的57页报告,标题只有四个词:《从AGI到ASI》。论文地址:https://arxiv.org/abs/2606.12683

主打高端直播 / 会议高清摄像头的Opal Camera在卖了超 5 万台设备后2025 年正式更名 Opal Electronics(以下简称Opal ),转型全品类 AI 消费硬件。随后OpenAI 领投4000 万美元,投资方含三星、Peter Thiel 基金、MKBHD(知名数码博主),投后估值2.75 亿美元。

香港城市大学曾晓成教授与中国石油大学(华东)钟杰教授团队给出了终结级的分子水平证据,成果发表于《Nature Physics》。他们首创了一套无监督深度学习框架,不给AI任何预设条件,直接把海量水系统中7400多万个水分子结构扔给模型,让AI自己去悟。结果不仅直接证明常压水里确实存在两种「暗」组份,还把A/B水分子相互变身的「立交桥」路线图给完整画了出来。
今天,月之暗面发布并开源Kimi K2.7 Code编程模型,参数量达1.1万亿,提供256K上下文窗口。这一模型重点提升了长上下文编程场景的指令遵循能力、长程编程任务的性能表现,并且大幅改善了在长程任务中的过度思考倾向,平均token消耗减少30%。

陶哲轩又发成绩单了。