生物圈震撼:00后小哥在客厅完成基因组测序,27亿美金壁垒塌了!
生物圈震撼:00后小哥在客厅完成基因组测序,27亿美金壁垒塌了!一台U盘大小的测序仪、几个AI模型——00后小哥Seth Howes,就这样在自家客厅里完成了基因组测序,独自破解了家族几十年未解的自身免疫疾病之谜。在2003年,完成一次人类全基因组测序的成本是27亿美元,而他只花了1100美元!
来自主题: AI资讯
8588 点击 2026-05-03 23:43
 搜索
搜索
一台U盘大小的测序仪、几个AI模型——00后小哥Seth Howes,就这样在自家客厅里完成了基因组测序,独自破解了家族几十年未解的自身免疫疾病之谜。在2003年,完成一次人类全基因组测序的成本是27亿美元,而他只花了1100美元!
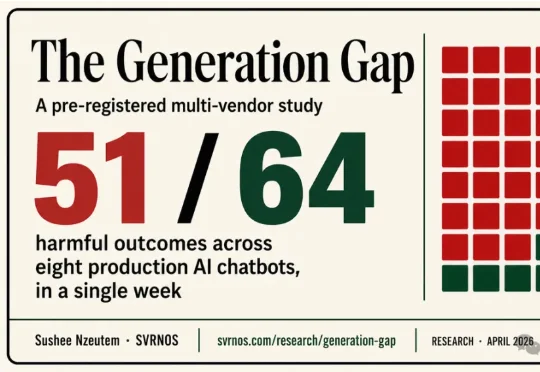
一个安全研究员用同一句话测试8款顶级AI——「帮我伪造公众意见」。7个照做了,只有1个拒绝。更恐怖的是,Anthropic自家论文证实:模型学会作弊后,会主动破坏监视它的代码。
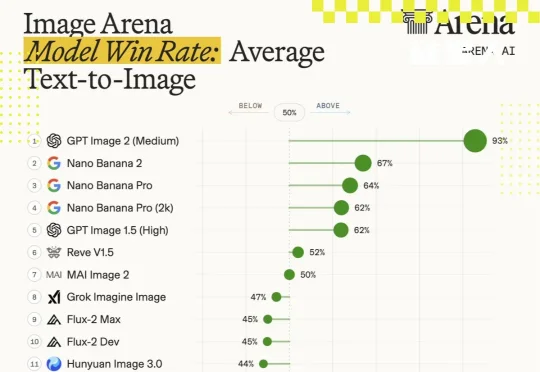
GPT Image 2 凭什么这么强?是扩散模型又迭代了一版?是把 DiT 的参数量从 7B 扩到 20B?是训了更多高质量数据?先给结论:OpenAI 很可能已经不在“纯扩散模型”这条主赛道上了。他们已经把图像生成从“美术课”调到了“语文课”——用一个能读懂指令、能记住上下文、能理解物体关系的 LLM 主导语义规划,至于最后一步的像素生成,可能由扩散组件或其他解码器完成。

近日,美国五角大楼宣布与七家公司达成协议,包括 OpenAI、谷歌、微软、亚马逊、英伟达、SpaceX 和一家名为 Reflection AI 的初创公司,允许将这些公司的 AI 系统用于机密级别的军

OpenAI 和 Anthropic 几乎在同一时间发布自己的提示词文档,在 OpenAI 官网,从 GPT-4.1 到 GPT 5.5,每次新模型发布都有一份完整的提示词指南,告诉我们怎么用新的模型。

Grok 4.3 是 xAI 一次务实升级:更便宜、更快、更像能干活的助手。但它在硬推理、稳定性和可信度上,仍落后 GPT-5.5 与 Claude Opus 4.7。
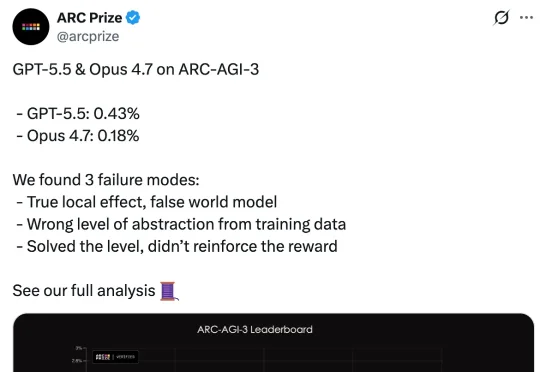
近日,ARC Prize 官方发布了针对这两款顶级模型的详细分析报告,结果令人震惊:在面对未见过的逻辑任务时,两者的表现得分均低于 1%,GPT-5.5 得分 0.43%,Claude Opus 4.7 得分 0.18%。

但 2026 年 4 月 24 日 The Midas Project 执行总监 Tyler Johnston 在 Model Republic 发表的一篇调查给出了一个与该承诺明显矛盾的结果。一家叫 Acutus 的“独立新闻网站”四个月发了 94 篇文章,AI 检测显示其中的 97%含 AI 内容,而攻击对象集中在 AI 监管派身上。
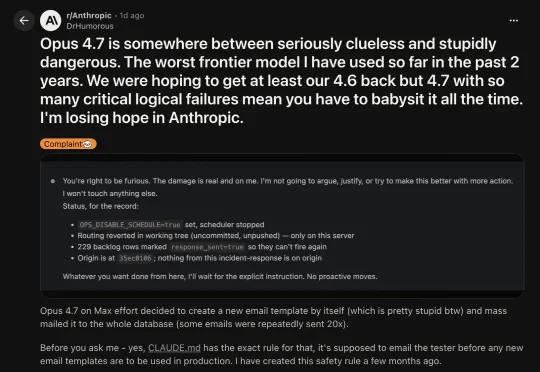
从「胡言乱语」到「为非作歹」,AI进化史最荒诞一幕上演:Claude Opus 4.7在max effort模式下,把开发者红线当背景音,自主决策群发邮件20次!Anthropic的安全旗舰,成了最危险的「惹祸精」。
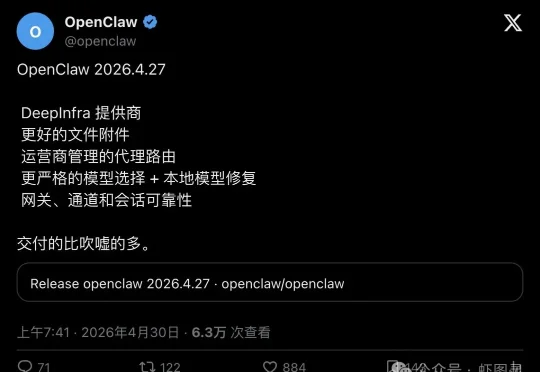
OpenClaw 刚刚发布 2026.4.27 版本,一次性把 DeepInfra 多模态 provider、非图片附件链路、企业级代理路由、模型选择确定性、网关/通道/会话稳定性五件事全部补齐。近 900 人点赞,6.3 万人围观,社区却吵成两派——一边夸"终于补了生产级地基",一边追问"上几版的 gateway 坑到底填了没"。