
不学美国砸钱烧AI,欧洲科技巨头另辟蹊径
不学美国砸钱烧AI,欧洲科技巨头另辟蹊径欧洲科技巨头的CEO最新表示,欧洲在人工智能领域展开竞争时并不需要大量建立数据中心,这一说法与上月黄仁勋访欧时提出的说法相悖。当地时间周四(7月3日),德国思爱普公司(SAP)首席执行官柯睿安(Christian Klein)在接受采访时说道:“我们真的需要建五个数据中心再把高性能芯片放进去吗?”
来自主题: AI资讯
9452 点击 2025-07-05 11:33
 搜索
搜索
欧洲科技巨头的CEO最新表示,欧洲在人工智能领域展开竞争时并不需要大量建立数据中心,这一说法与上月黄仁勋访欧时提出的说法相悖。当地时间周四(7月3日),德国思爱普公司(SAP)首席执行官柯睿安(Christian Klein)在接受采访时说道:“我们真的需要建五个数据中心再把高性能芯片放进去吗?”

图灵奖大佬向97年小孩哥汇报,这是什么魔幻剧情?小扎砸143亿请来的「数据标注少年」,已荣升Meta首席AI官。一边是小扎上亿美元年薪offer引进新员工,另一边是Meta老将GPU告急不得不熬夜借卡差点头秃。网友们痛呼:太为Meta FAIR的员工难过了……

7月3日消息,在近期AMD Advancing AI 2025 大会上,吴恩达与苏姿丰就 AI 的普及、开放生态和硬件基础设施展开交流。两人强调,多层技术栈、快速原型和AI助编工具能大幅提升开发效率。
7月3日,2025全球数字经济大会上,一份重磅榜单面向全球首次揭晓。
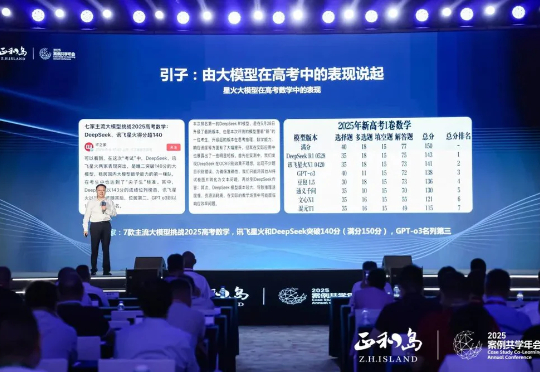
6月27日,“正和岛2025案例共学年会暨AI+先行者创新大集”在合肥继续进行,本次大会以“向新力”为主题,千余位企业家共同探讨AI时代下的组织变革与商业格局。
在 AI 工具风靡开发圈之前,一批经验丰富的资深程序员,对它们始终保持警惕。这些人,包括 Flask 作者 Armin Ronacher(17 年开发经验)、PSPDFKit 创始人 Peter Steinberger(17 年 iOS 和 macOS 开发经验),以及 Django 联合作者 Simon Willison(25 年编程经验)。然而,就在今年,他们的看法都发生了根本转变。

AI非上云不可、非集群不能?万字实测告诉你,32B卡不卡?70B是不是智商税?要几张卡才能撑住业务? 全网最全指南教你如何用最合适的配置,跑出最强性能。

让游戏行业真正成为创意产业,而不是劳动密集型产业。

2023 年 7 月,《晚点 LatePost》曾独家披露,字节 AI Lab 旗下机器人团队正推进机器人量产。当时曾定下到 2023 年年底,量产 200 台的目标。

刚刚,一支华人主导的AI团队打破硅谷融资纪录。