
GPT-5.5彻底击穿300个黑客评测任务,仅需5000万Token!
GPT-5.5彻底击穿300个黑客评测任务,仅需5000万Token!GPT-5.5 把进攻性网络安全最难的 7 个基准全部打穿,92.4% 正确率,评估体系直接失灵。AI 黑客能力每 6 个月翻一倍,而衡量它有多危险的尺子,已经先被干碎了。
来自主题: AI资讯
9455 点击 2026-05-29 10:11
 搜索
搜索
GPT-5.5 把进攻性网络安全最难的 7 个基准全部打穿,92.4% 正确率,评估体系直接失灵。AI 黑客能力每 6 个月翻一倍,而衡量它有多危险的尺子,已经先被干碎了。
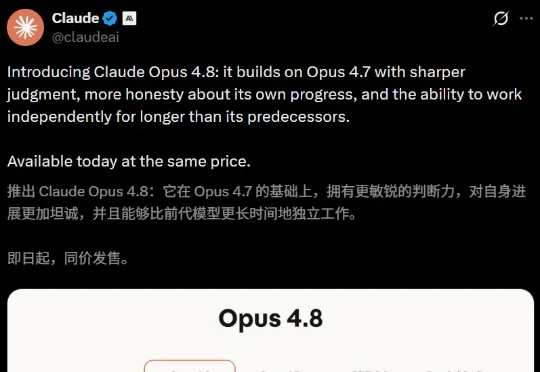
Opus 4.7发布刚43天,Opus 4.8就来了!编程实力暴增,全面霸榜。Claude Code一口气放出上百个agent并行干活,一个人11天就能重写75万行代码、99.8%测试通过。更狠的Claude Mythos,几周后就来。
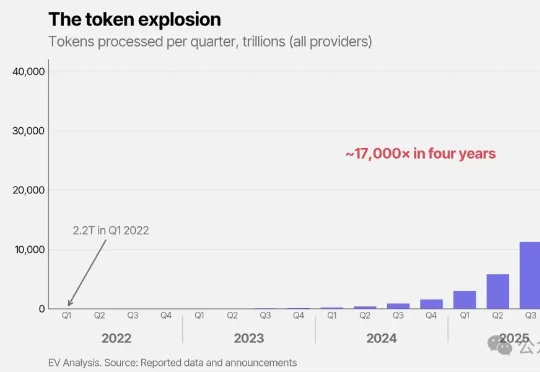
Epoch AI刚刚发布的《梯度更新》报告,做了一件简单粗暴的事:把全球所有Blackwell芯片能处理的Token数量算出来,再和实际需求一比。结论只有一个字——不够。

5 月 22 日,《一人之下》第 763 话更新,国漫圈这回吵得有点凶。

近期,深圳河套学院(SLAI)AI训练平台项目团队,联合哈尔滨工业大学(深圳)、深圳大数据研究院、华为GTS(全球技术服务)团队与深智城AI算力平台,仅用1个月,共同基于昇腾910C国产算力集群实现DeepSeek-V4-Pro全参数续训练/SFT稳定运行,完成长稳训练1500+步,训练MFU超30%,关键训练算子效率提升14%。
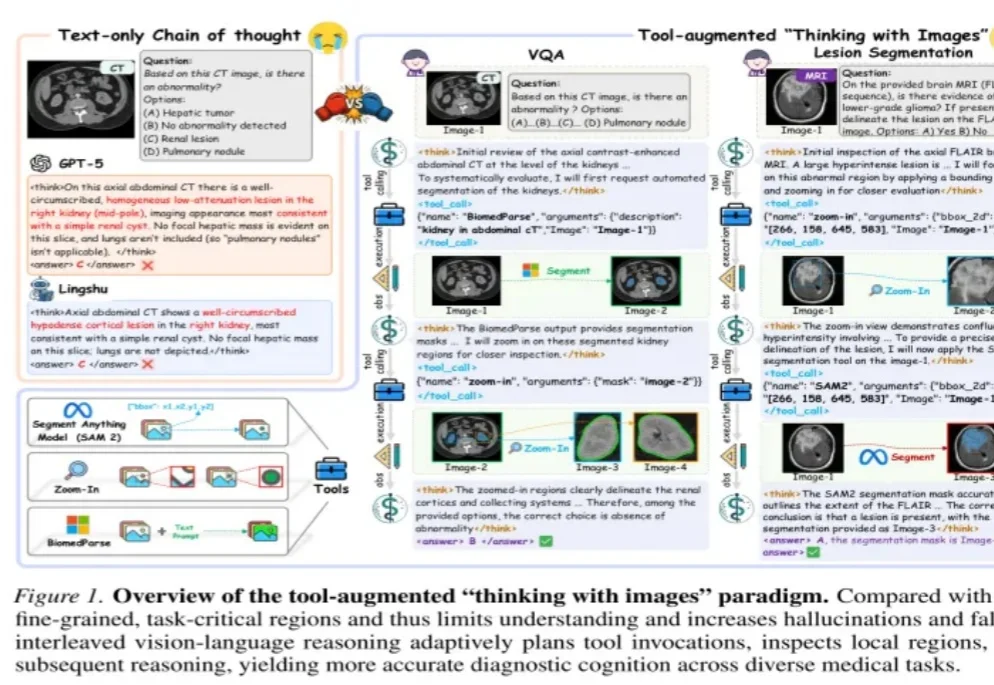
医学AI会写解释,但不代表它真的“看到”了关键证据。

超越 GPT-5.5、Gemini 3.5 Flash、DeepSeek V4 Pro,阿里的最新旗舰模型 Qwen3.7 Max 在编程竞技榜拿下第二名,仅次于 Claude Opus 4.7。除了真实场景的用户选择,在传统的大模型固定评测榜单上,像是终端能力 Terminal Bench、编程能力 SWE Bench 等,Qwen3.7 Max 的表现也是拿下了国产模型的冠军。

Gemini 3.5的闯祸实录。

一个号称「零污染」的新基准 DeepSWE,用113道原创题撕开了旧编程榜单的遮羞布。
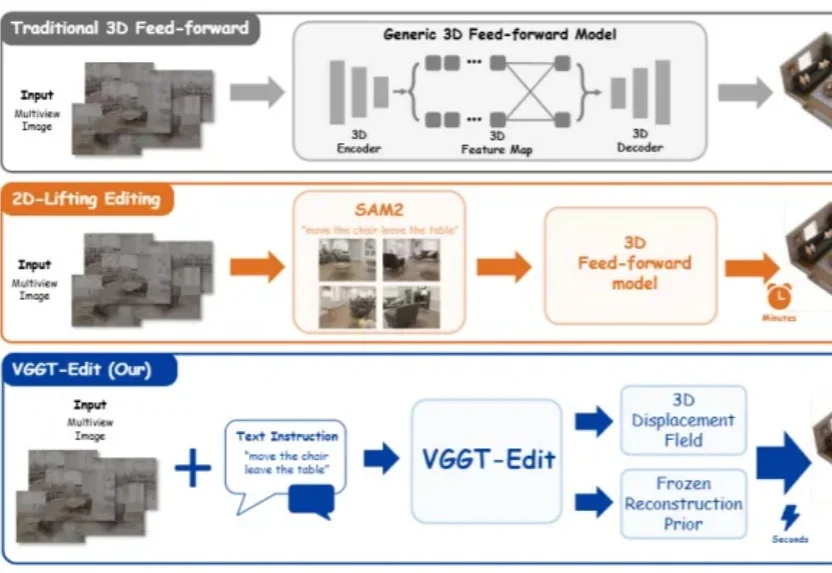
3D世界“会看”了,但还不会“改”。