
提速79%!上交大新方法优化企业级AI流程调度 | IEEE ICDCS’ 25
提速79%!上交大新方法优化企业级AI流程调度 | IEEE ICDCS’ 25复合LLM应用 (compound LLM applications) 是一种结合大语言模型(LLM)与外部工具、API、或其他LLM的高效多阶段工作流应用。
来自主题: AI技术研报
9738 点击 2025-07-25 09:51
 搜索
搜索
复合LLM应用 (compound LLM applications) 是一种结合大语言模型(LLM)与外部工具、API、或其他LLM的高效多阶段工作流应用。

一位从业20年设计师的自白。7月的杭州,潮湿的空气似乎随时都在酝酿一场暴雨。

2025年8月,OpenAI将正式发布下一代大模型GPT-5!这一备受瞩目的升级版AI由CEO奥特曼亲自预热,集成了o系列推理能力,定位为通往AGI(通用人工智能)的关键一步。

大模型的能力再一次被行业验证!7月23日,夸克健康大模型在业界引起广泛关注:其成功通过了中国12门核心学科的主任医师笔试评测,成为国内首个完成此项专业考核的AI大模型。为深入解读其技术路径,我们分享一份关于夸克健康大模型的深度调研报告。

2025年7月21日,斯坦福大学学习加速器(Stanford Accelerator for Learning)发布名为《AI+学习差异:设计无边界的未来》(AI+ Learning Differences: Designing a Future with No Boundaries)白皮书,强调AI可以成为支持有学习差异的学生的有力工具,但前提是其开发要以他们的需求和意见为核心。
Bing Search API 将于2025年8月下线,如果你正寻找替代方案,不妨试试秘塔。 过去一年,我们自建了数百亿规模的多语言索引库,并在“秘塔AI搜索”中每天承受千万级的调用实践。

当AI创业进入高潮,连硅谷人们都重新开始拥抱“996”了。 早九晚九,一周六天,每周72个小时,直接干翻标准工时的两倍!
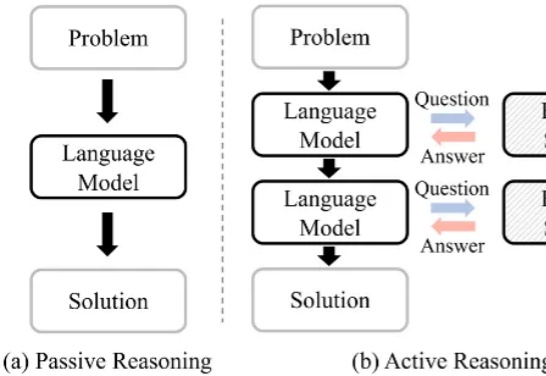
大语言模型(Large Language Model, LLM)在复杂推理任务中表现卓越。借助链式思维(Chain-of-Thought, CoT),LLM 能够将复杂问题分解为简单步骤,充分探索解题思路并得出正确答案。LLM 已在多个基准上展现出优异的推理能力,尤其是数学推理和代码生成。

刚刚,美国AI行动计划正式上线!28页PDF围绕三大支柱:AI创新、AI基础设施、全球AI规则,推出90多项行政令。放松AI监管、全球推广开源模型,大力投资超算、半导体建设等,直指全球AI霸主地位。

7月23日消息,在近日举行的《大型银行资本框架综合审查》会议上,OpenAI首席执行官山姆·奥特曼与美联储副主席米歇尔·鲍曼(Michelle Bowman)展开了一场炉边对话,探讨了AI对经济和金融领域的影响,并强调AI在提高效率和降低成本方面的空前潜力。