独家!腾讯内测AI视频创作工具“TDream”,成片效果让我意外
独家!腾讯内测AI视频创作工具“TDream”,成片效果让我意外《读佳》获知,腾讯“TDream”带着“创造可玩的世界”的定位低调开启内测。“说句肺腑之言,这个产品,我觉得打破了我对腾讯的认知。”一位用户看了TDream生成《山月》视频作品后,十分感慨。他觉得,这个产品可以和字节的Seedance2.0、HappyHorse掰掰手腕。
来自主题: AI资讯
9021 点击 2026-06-12 10:53
 搜索
搜索
《读佳》获知,腾讯“TDream”带着“创造可玩的世界”的定位低调开启内测。“说句肺腑之言,这个产品,我觉得打破了我对腾讯的认知。”一位用户看了TDream生成《山月》视频作品后,十分感慨。他觉得,这个产品可以和字节的Seedance2.0、HappyHorse掰掰手腕。
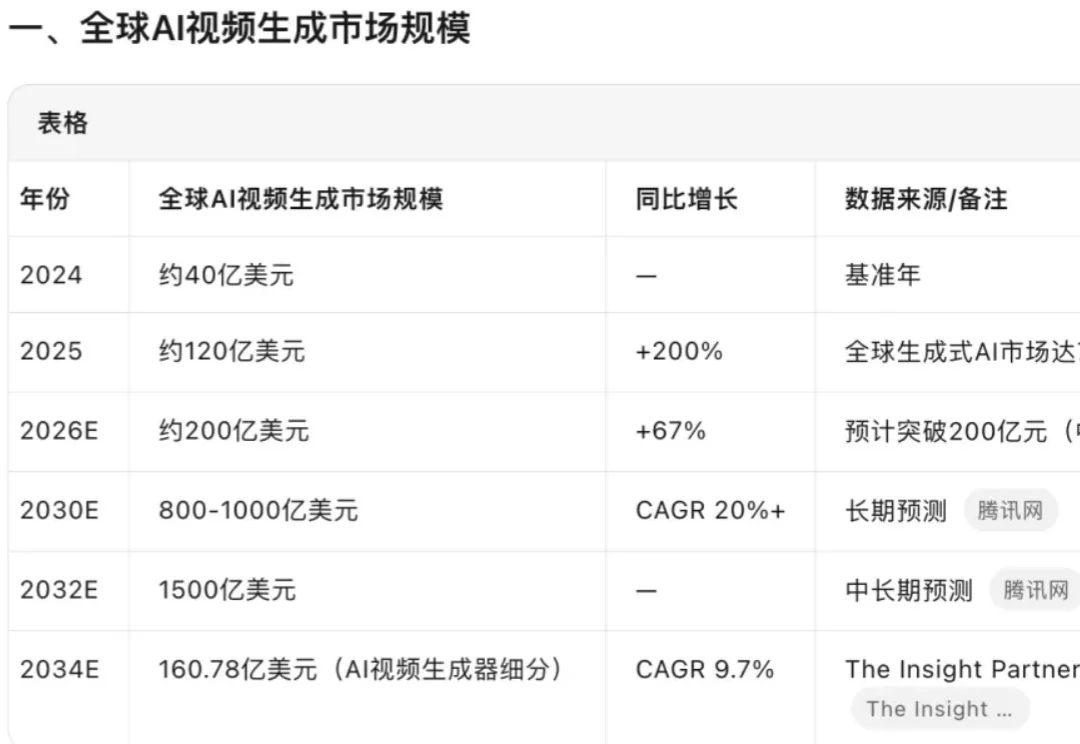
我最近专门调研了一下AI短视频🧐。发现市场规模是越来越大。
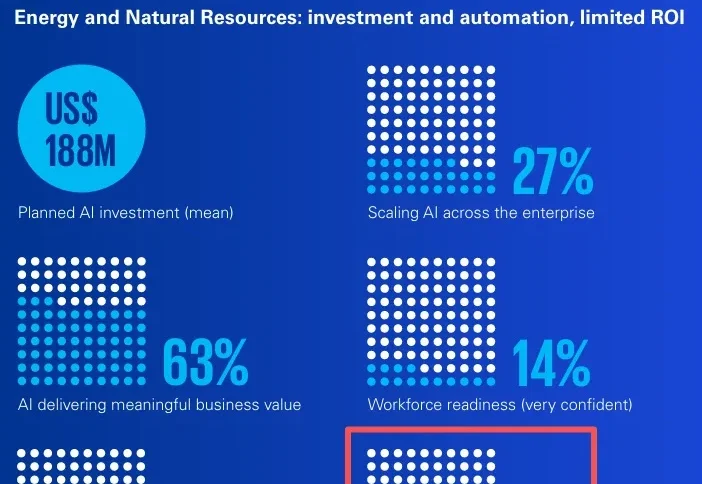
一提到AI的应用和落地,大家就会陷入非共识迷雾。为了拨开营销炒作,我把近期有代表性的几份Enterprise AI调研报告拉通,横跨Menlo Ventures(500+企业AI决策者)、德勤(24个国家,6大行业,3235名高管)、KPMG(20个国家,8大行业,2110名全球高管)、Entelligence(2444家企业)。

Claude Fable 5 发布之后,奥特曼又要被吓到眩晕瘫坐,犹如看到原子弹爆炸了。 短短 24 小时里,社交平台几乎被各种案例淹没。视频一个接一个冒出来,我们还没看完上一个,时间线又跳出一个由

近日,Anthropic 发布了一篇引发广泛关注的文章《When AI builds itself》。文中披露了极其惊人的内部数据:截至 2026 年 5 月,Anthropic 超过 80% 的合并代码已由 Claude 编写,工程师的日常代码产出飙升了 8 倍;更令人瞩目的是,AI 智能体已经可以自主提出假设、执行长达数百小时的强化安全实验。

根据我长期使用的观察,0.3 倍率说是用 Kiro 逆向出来的 Claude,2.0 倍率说是正经 Claude Max 号池接出来的。听起来后者肯定更靠谱。我一开始也这么想的。毕竟倍率差了快七倍,价格摆在那,总不至于拿假货糊弄人吧。

发布24小时,神话级Claude 5光速登顶!不仅创下AI史上最大分差纪录,更将GPT-5.5直接斩落马下。

当 AI 教育从屏幕走向物理世界,松延动力正用小布米、课程体系和「学校—机构—家庭」生态闭环,把 K12 机器人教育变成具身智能走进千家万户的第一站。

视频生成,早已不止于视觉。
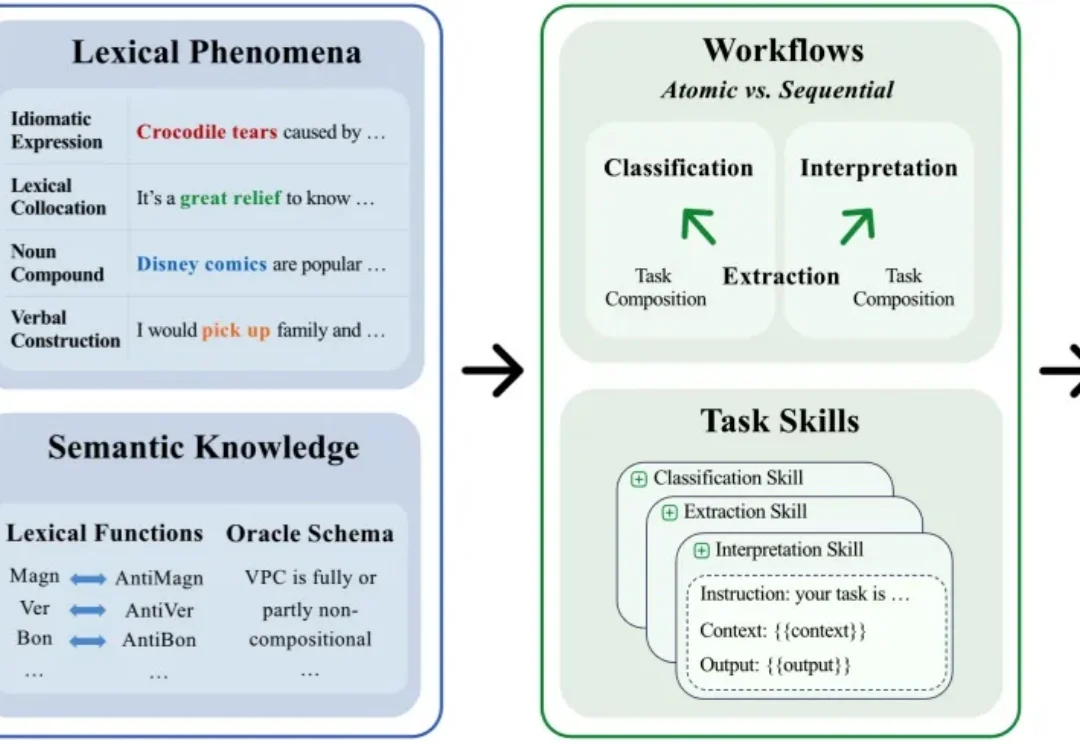
AI 的能力边界正在不断被刷新。从数学推理到代码生成,再到数字化白领,语言模型和语言智能体在诸多基准测试中已展现出超越人类专家的表现。一个看似顺理成章的判断早已成为共识:语言模型已经具备了扎实的语言理解和语义推理能力。然而,ACL 2026 Oral 的一项研究工作从一个更基础的层面重新审视了这个问题:语言模型真的理解(短语)语义吗?