

卷积网络又行了?DeepMind推翻Transformer最强传说,LeCun怒赞
卷积网络又行了?DeepMind推翻Transformer最强传说,LeCun怒赞DeepMind最新研究发现,只要模型设计上没有缺陷,决定模型性能的核心可能是训练计算量和数据。在相同计算量下,卷积神经网络模型和视觉Transformers模型的性能居然能旗鼓相当!
来自主题: AI技术研报
7376 点击 2023-10-29 10:24
DeepMind最新研究发现,只要模型设计上没有缺陷,决定模型性能的核心可能是训练计算量和数据。在相同计算量下,卷积神经网络模型和视觉Transformers模型的性能居然能旗鼓相当!

获取原版PDF,请添加官方微信 openai178 免费领取。2023年中国人工智能学会发布了《中国人工智能系列白皮书—深度学习》,白皮书包含了从人工智能历史到深度学习的技术解析,以及AI在各领域的落地应用。报告原文PDF多达461页,24万字。
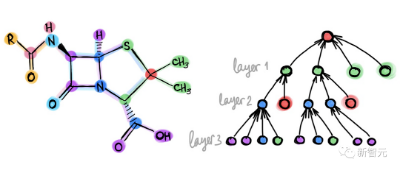
GraphGPT框架将图结构模型和大语言模型进行参数对齐,利用双阶段图指令微调范式提高模型对图结构的理解能力和适应性,再整合ChatGPT提高逐步推理能力,实现了更快的推理速度和更高的图任务预测准确率。
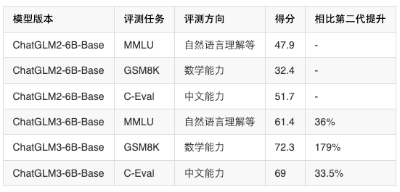
今天,智谱AI开源其第三代基座大语言模型ChatGLM3-6B,官方说明该模型的性能较前一代大幅提升,是10B以下最强基础大模型!

在一项研究中,当类人智能体非常饥饿时,它们会在正餐之外吃点小吃;当感到愤怒时,会去跑步来释放愤怒;当感到伤心时,会寻求信任的朋友的支持;当感到厌恶时,会练习深呼吸和冥想技巧。

相比于一味规避“有毒”数据,以毒攻毒,干脆给大模型喂点错误文本,再让模型剖析、反思出错的原因,反而能够让模型真正理解“错在哪儿了”,进而避免胡说八道。

研究创造了一个神经网络,该人工智能(AI)系统在将新学到的单词添加到现有的词汇表中并在新的上下文中使用它们的能力,超越了ChatGPT,表现与人类相当,而这一能力正是人类认知能力的关键——系统泛化。
2024年元旦将至,很多公司都有做龙年主题海报的需求。我们今天抛砖引玉,给大家介绍用chatGPT和midjourney做龙年主题海报的详细步骤。
今天最新消息,元象XVERSE与腾讯音乐合作推出 lyraXVERSE 加速大模型,将应用于音乐助手 “AI 小琴” 中。用户可以通过点击 QQ 音乐上的 “AI 一起听” 按键来与升级版的 “AI 小琴” 互动,她将根据用户的提问、播放习惯和心情提供闲聊、推歌、音乐解读和词曲创作等服务。

大型语言模型能力惊人,但在部署过程中往往由于规模而消耗巨大的成本。华盛顿大学联合谷歌云计算人工智能研究院、谷歌研究院针对该问题进行了进一步解决,提出了逐步微调(Distilling Step-by-Step)的方法帮助模型训练。
今年爆火的智能体项目AutoGPT,现获得了1200万美元融资。不得不说,Auto-GPT在AI领域掀起了巨大的波澜,它就像是赋予了GPT-4记忆和实体一样,让它能够独立应对任务,甚至从经验中学习,不断提高自己的性能。

本文介绍了一份AI意识检查清单,用于评估AI系统是否具备意识。研究人员根据意识理论提取了6种意识指标,并通过评估Transformer和Perceiver等AI系统,展示了使用这些指标的方法。
无论是科研工作者还是从业者,都希望能在知识和技术的共享基础上,实现更加高效、有深度的协作,推动 AI 领域的进一步发展。在这样的背景下,一个全新的 AI 开源社区平台「SwanHub」诞生了。
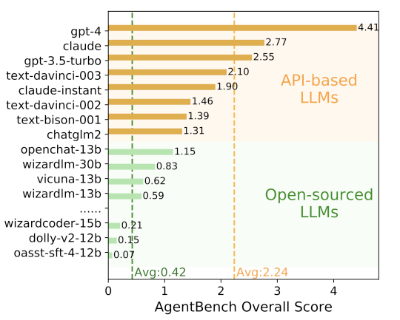
智谱AI&清华KEG提出了一种对齐 Agent 能力的微调方法 AgentTuning,该方法使用少量数据微调已有模型,显著激发了模型的 Agent能力,同时可以保持模型原有的通用能力。
阿里巴巴算法工程师手把手教你部署AI模型

GPT-4根本不知道自己犯错?最新研究发现,LLM在推理任务中,自我纠正后根本无法挽救性能变差,引AI大佬LeCun马库斯围观。

Inc42 题为《2023 年印度生成式 AI 初创公司格局》的最新报告,该国的 GenAI 市场将在未来几年呈指数级增长。预计到 2030 年,这一数字将从 2023 年的 11 亿美元突破 170 亿美元,复合年增长率为 48%。

英伟达最新AI AgentEureka ,用GPT-4生成奖励函数,结果教会机器人完成了三十多个复杂任务。
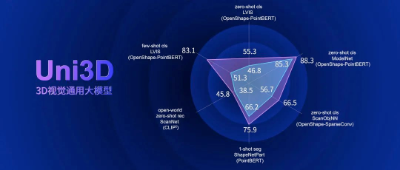
最近,智源、清华和北大联合发布了全新的10亿参数的3D视觉通用模型——Uni3D,在主流3D视觉能力上取得了全方位的性能突出!
Meta AI研发新成果,利用脑电信号将人类大脑活动解码并可视化。这项研究开辟了一条前所未有的新途径,能够帮助科学界了解图像如何在大脑中表示,进一步揭示人类智能的其他方面。

神经网络可以识别出哪些引用是不支持文章观点的,并且搜索出更好的来源作为引用。这是一个对于AI写论文领域的重要发现。

最近多模态大模型是真热闹啊。 这不,Transformer一作携团队也带来了新作,一个规模为80亿参数的多模态大模型Fuyu-8B
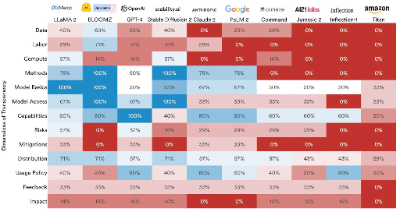
斯坦福大学的研究人员公布了一套 "基础模型透明度指数"评分系统,目的是让大家对AI模型有更深的了解
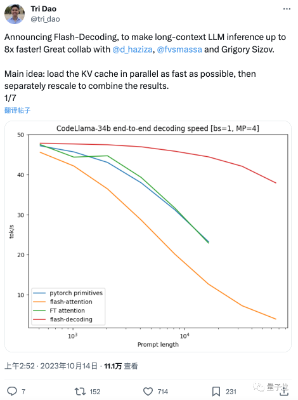
这两天,FlashAttention团队推出了新作: 一种给Transformer架构大模型推理加速的新方法,最高可提速8倍。 该方法尤其造福于长上下文LLM,在64k长度的CodeLlama-34B上通过了验证

ChatGPT之类的AI编码工具来势汹汹,Stack Overflow又裁员了!不过,普林斯顿和芝大竟发现,面对真实世界GitHub问题,GPT-4的解决率竟是0%。

Zilliz和 Dify.AI 达成合作,Zilliz 旗下的产品 Zilliz Cloud、Milvus 与开源 LLMOps 平台 Dify 社区版进行了深度集成。
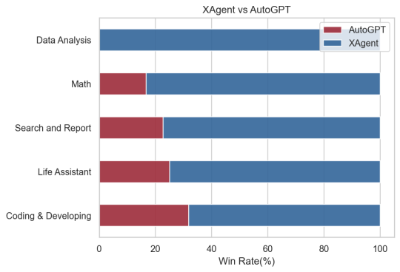
国内领先的人工智能大模型公司面壁智能又放大招,联合清华大学 NLP 实验室共同研发并推出大模型「超级英雄」——XAgent。
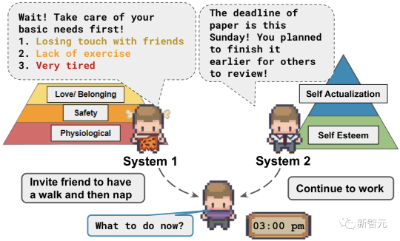
英伟达、华盛顿大学等机构提出的Humanoid Agents,行为竟如此接近人类!累了要休息,孤独要找人陪,发泄怒火时会跑步或冥想。

早就听说笔记本PC就能跑生成式AI,我们也试了试,看看笔记本仅借助CPU能不能在本地自己写代码、自己作图?

Agent 的思路为我们带来了 Software 2.0 的图景:LLM 作为推理引擎能力不断增强,AI Agent 框架为其提供结构化思考的方法,软件生产进入“3D 打印”时代