

谷歌DeepMind爆火动画18秒解释LLM原理,网友蒙圈!组团求GPT-4下场分析
谷歌DeepMind爆火动画18秒解释LLM原理,网友蒙圈!组团求GPT-4下场分析最近,Google DeepMind发布了一段小视频,据说是在向普通人展示大语言模型的工作原理。网友看后纷纷表示:懂得都懂。
来自主题: AI技术研报
5300 点击 2023-11-13 21:58
最近,Google DeepMind发布了一段小视频,据说是在向普通人展示大语言模型的工作原理。网友看后纷纷表示:懂得都懂。
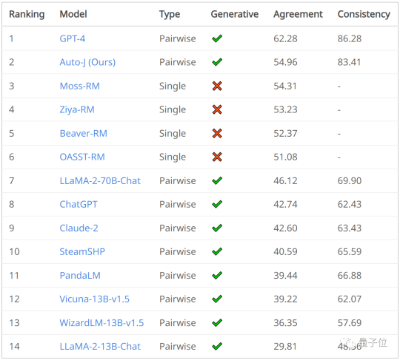
评估大模型对齐表现最高效的方式是?在生成式AI趋势里,让大模型回答和人类价值(意图)一致非常重要,也就是业内常说的对齐(Alignment)。

GitHub公布了今年的Octoverse开源状态报告,AI成为了当仁不让的主角。印度也将替代美国成为最大的开发者社区。还有更多趋势和详细信息,开发者千万不能错过!
OpenAI都搞不定的问题,被堪萨斯大学的一个研究团队解决了?他们开发的学术AI内容检测器,准确率高达98%。如果将这个技术再学术圈广泛推广,AI论文泛滥的可能得到有效缓解。
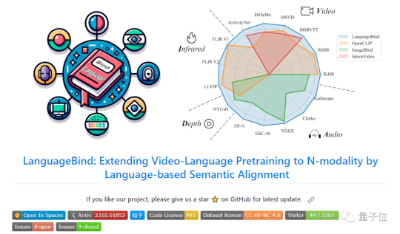
北大联合腾讯打造了一个多模态15边形战士!以语言为中心,“拳打脚踢”视频、音频、深度、红外理解等各模态。

ChatGPT用它自己的方式来理解世界,类似的技术是否也能用来学习动物的语言?
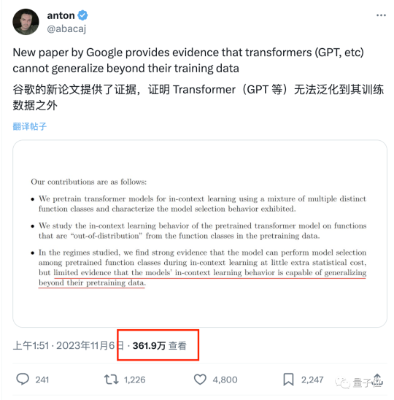
针对Transformer,谷歌DeepMind一项新的发现引起了不小争议: 它的泛化能力,无法扩展到训练数据以外的内容。

最近微软一项研究让Llama 2选择性失忆了,把哈利波特忘得一干二净。 现在问模型“哈利波特是谁?”,它的回答是这样婶儿的:

大模型赛道已经吸引了大量企业或创业者投入,那么,目前大模型赛道都有哪些主流研究方向和共同挑战?这篇文章里,作者梳理了LLM研究的十大挑战,一起来看看

AGI应该如何发展、最终呈什么样子? 现在,业内第一个标准率先发布: AGI分级框架,来自谷歌DeepMind。
最近,NLP 大牛、HuggingFace联合创始人 Thomas Wolf 发了一条推特,内容很长,讲了一个 “全球三大洲的人们公开合作,共同打造出一个新颖、高效且前沿的小型 AI 模型” 的故事。

OpenAI引爆了核弹,让任何人都可以使用自然语言在几分钟内构建应用程序!爆炸性的革命时刻,真的来了。

11月6日发表在科学顶刊《细胞》物理子刊《Cell Reports Physical Science》上的一项研究,科学家已研究出一种机器学习工具,可以很容易地识别出使用聊天机器人ChatGPT撰写的化学论文。

业界最领先的大模型们,竟然集体“越狱”了! 不止是GPT-4,就连平时不咋出错的Bard、Bing Chat也全线失控,有的要黑掉网站,有的甚至扬言要设计恶意软件入侵银行系统

基于LVLM幻觉频发的三个成因(物体共现、物体不确定性、物体位置),北卡教堂山、斯坦福、哥大、罗格斯等大学的研究人员提出幻觉修正器LURE,通过修改描述来降低幻觉问题。

GPT-4V挑战视觉错误图,结果令人“大跌眼镜”。 像这种判断“哪边颜色更亮”的题,一个没做对

大连理工大学信息检索研究室展开了面向生物医学领域大模型的研究,并在wisemodel.cn社区发布初版中英双语生物医学大模型——太一(Taiyi),旨在探索大模型在生物医学领域中双语自然语言处理多任务的能力。

通用模型时代下,当今和未来的前沿AI系统如何与人类意图对齐?通往AGI的道路上,AI Alignment(AI对齐)是安全打开 “潘多拉魔盒” 的黄金密钥。
最近,由CMU/MIT/清华/Umass提出的全球首个生成式机器人智能体RoboGen,可以无限生成数据,让机器人7*24小时永不停歇地训练。AIGC for Robotics,果然是未来的方向。
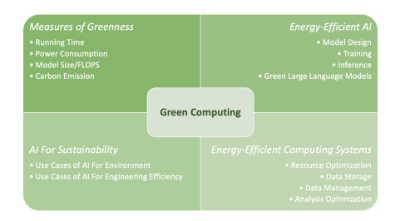
在深度学习时代,尤其是随着大型语言模型(LLMs)的出现,大多数研究人员的注意力都集中在追求新的最先进(SOTA)结果上,使得模型规模和计算复杂性不断增加。
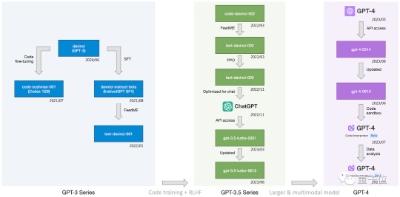
GPT-3究竟是如何进化到GPT-4的? 字节给OpenAI所有大模型来了个“开盒”操作。 结果还真摸清了GPT-4进化路上一些关键技术的具体作用和影响。
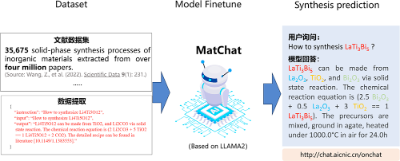
中国科学院物理研究所/北京凝聚态物理国家研究中心SF10组和中国科学院计算机网络信息中心共同合作,将AI大模型应用于材料科学领域,将数万个化学合成路径数据投喂给大语言模型LLAMA2-7b,从而获得了MatChat模型

11月2日,今天 9 : 12 分,midjourney更新了“/tune” 命令,官方名称“Style Tuner”,译为“风格调谐器”,该功能可以通过您调整出满意的风格,并分享这串代码,也就意味着可以训练融合自己的风格。
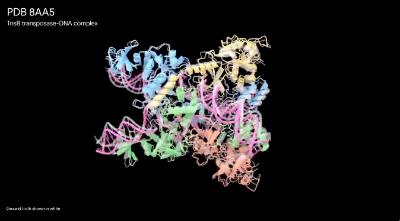
今天,DeepMind公布了AlphaFold的最新版本,不仅预测蛋白质结构的准确性大大提高,而且获得了预测RNA等新的能力。
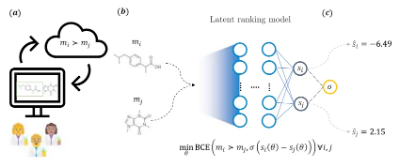
2023年10月31日,诺华生物医学研究所和微软研究院科学智能中心的研究人员合作,在 Nature Communications 期刊发表了题为:Extracting medicinal chemistry intuition via preference machine learning 的研究论文。
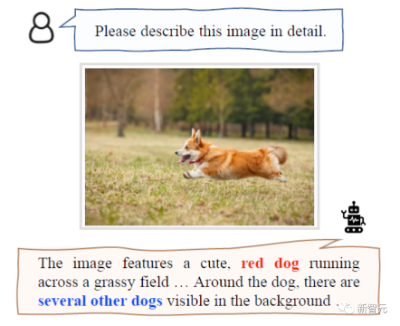
视觉幻觉是常见于多模态大语言模型的一个典型问题。最近,来自中科大等机构的研究人员提出了首个多模态修正架构「啄木鸟」,可有效解决MLLM输出幻觉的问题。

即便大语言模型的参数规模日渐增长,其模型中的参数到底是如何发挥作用的还是让人难以琢磨,直接对大模型进行分析又费钱费力。针对这种情况,微软的两位研究员想到了一个绝佳的切入点
在ChatGPT火爆出圈后,越来越多的人对人工智能、深度学习、神经网络等名词更加好奇,身边的朋友最近也频繁的问我,AI究竟为什么如此强大?今天我就用大家都看得懂的小学数学知识,来带大家感受人工智能的魅力,带大家认识神经网络。

千亿级大模型正迅速耗尽世界的高质量数据。对此,英伟达和UT提出了MimicGen系统。从人工合成数据中获得人工智能,将是未来的发展方向。

在今天的分享中,我将探讨“逆向Prompt提示词工程”技术。这篇文章是该主题的第三部分,旨在给大家演示如何根据已有的文本内容,逆向推导出生成该内容的关键提示词prompt。