
MiniCPM:揭示端侧大语言模型的无限潜力
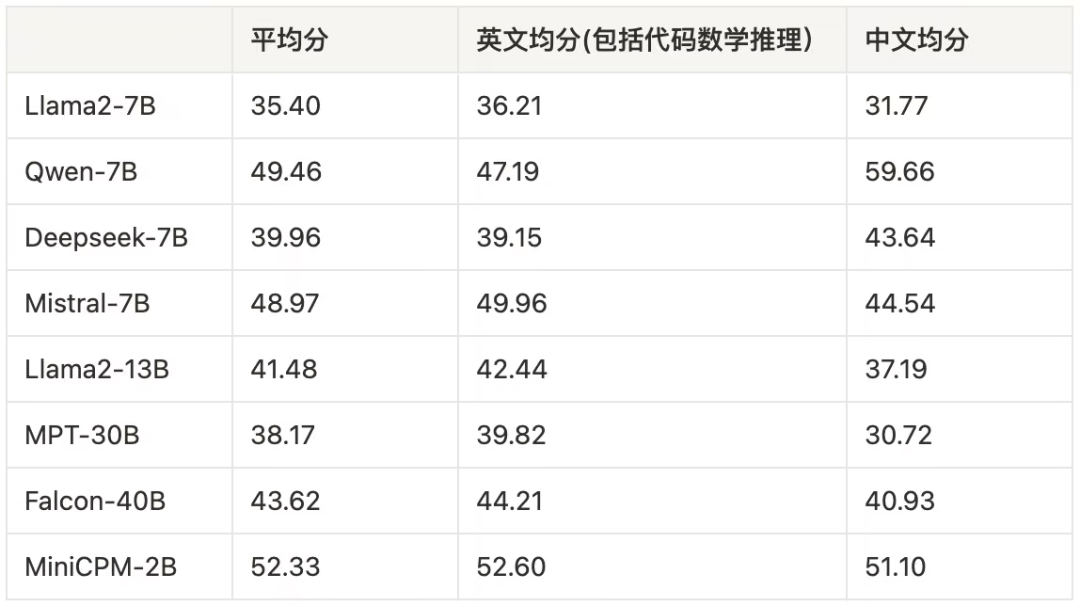
MiniCPM:揭示端侧大语言模型的无限潜力MiniCPM 是一系列端侧语言大模型,主体语言模型 MiniCPM-2B 具有 2.4B 的非词嵌入参数量。
来自主题: AI技术研报
8713 点击 2024-02-05 14:42
MiniCPM 是一系列端侧语言大模型,主体语言模型 MiniCPM-2B 具有 2.4B 的非词嵌入参数量。

今天,穆罕默德・本・扎耶德人工智能大学 VILA Lab 带来了一项关于如何更好地为不同规模的大模型书写提示词(prompt)的研究,让大模型性能在不需要任何额外训练的前提下轻松提升 50% 以上。该工作在 X (Twitter)、Reddit 和 LinkedIn 等平台上都引起了广泛的讨论和关注。
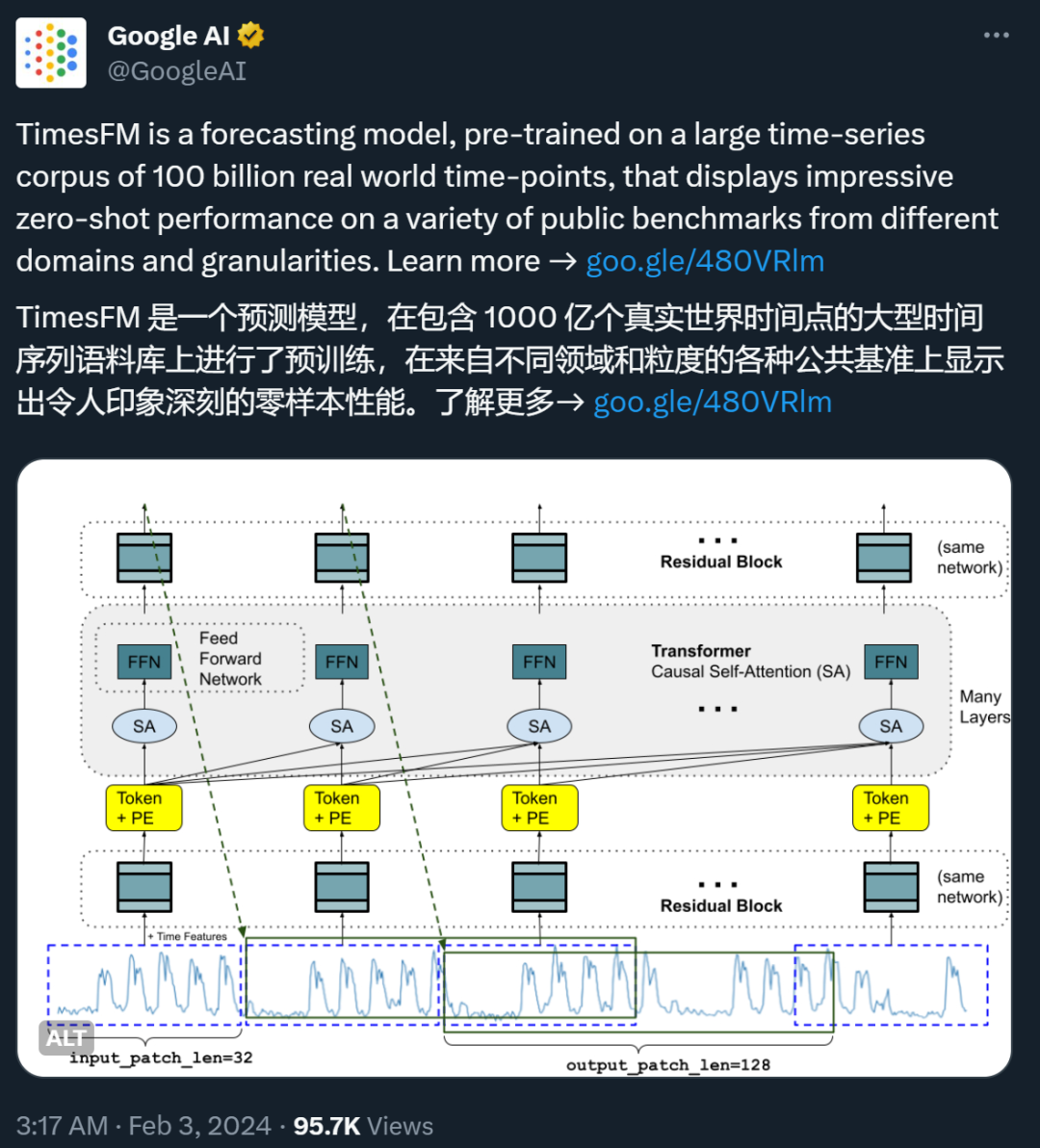
最近,谷歌的一篇论文在 X 等社交媒体平台上引发了一些争议。

最近,来自Meta和UC伯克利的研究人员,发布了一种最新的音频到人像模型。操作简单,输出极致逼真。

最近,来自UCSB和苹果的华人团队提出了MGIE,通过多模态模型引导图像精准编辑,可以10秒完成P图。
这几天,古老的AI应用——「AI换脸」多次破圈,屡屡登上热搜。

分手8个月想挽回,女友却爱上了AI男友,怎么破?这位美国博士小哥选择用错误数据毒害模型,训成一个妥妥的负分男友,结果,女友果真来找他了……
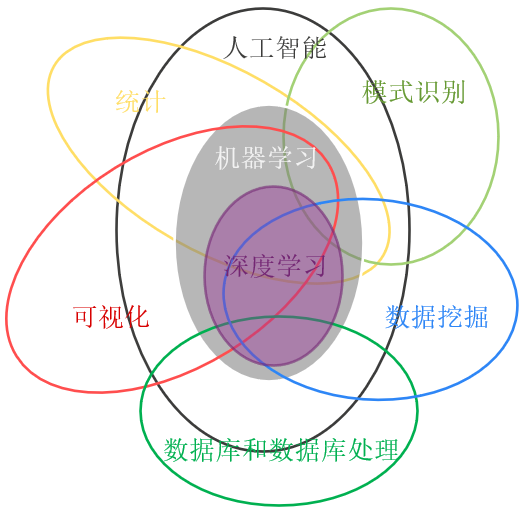
人工智能,即大家说的AI(Artificial Intelligent),当属最热门的技术之一。今天站在嵌入式的角度给大家分享一下人工智能包含的一些要点。
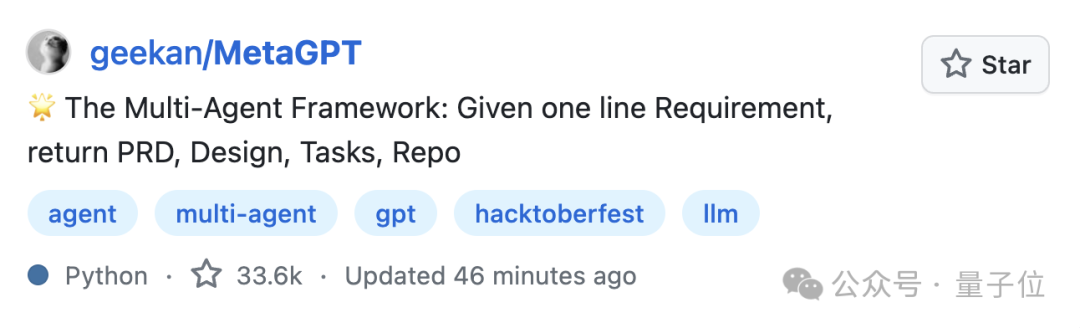
一项名为MetaGPT的研究,通过对智能体角色进行明确分工,并要求多个智能体在协作中采用统一规范的“交流格式”等方法,让智能体性能大增。

模型通过学习这些 token 的上下文关系以及如何组合它们来表示原始文本或预测下一个 token。

2023 年 12 月,首个开源 MoE 大模型 Mixtral 8×7B 发布,在多种基准测试中,其表现近乎超越了 GPT-3.5 和 LLaMA 2 70B,而推理开销仅相当于 12B 左右的稠密模型。为进一步提升模型性能,稠密 LLM 常由于其参数规模急剧扩张而面临严峻的训练成本。

ChatGPT 等通用大模型支持的功能成百上千,但是对于普通日常用户来说,智能写作一定是最常见的,也是大模型最能真正帮上忙的使用场景之一。

作为图领域首个通用框架,OFA实现了训练单一GNN模型即可解决图领域内任意数据集、任意任务类型、任意场景的分类任务。

在软件工程顶会ESEC/FSE上,来自马萨诸塞大学、谷歌和伊利诺伊大学厄巴纳-香槟分校(UIUC)的研究人员发表了新的成果,使用LLM解决自动化定理证明问题。

艾伦人工智能研究所等5机构最近公布了史上最全的开源模型「OLMo」,公开了模型的模型权重、完整训练代码、数据集和训练过程,为以后开源社区的工作设立了新的标杆。

加拿大滑铁卢大学的研究人员在《Nature Computational Science》发表题为《Language models for quantum simulation》 的 Perspective 文章,强调了语言模型在构建量子计算机方面所做出的贡献,并讨论了它们在量子优势竞争中的未来角色。

有的大模型对齐方法包括基于示例的监督微调(SFT)和基于分数反馈的强化学习(RLHF)。然而,分数只能反应当前回复的好坏程度,并不能明确指出模型的不足之处。相较之下,我们人类通常是从语言反馈中学习并调整自己的行为模式。

一周前,OpenAI 给广大用户发放福利,在下场修复 GPT-4 变懒的问题后,还顺道上新了 5 个新模型,其中就包括更小且高效的 text-embedding-3-small 嵌入模型。

一直以来,让 AI 成为手机操作助手都是一项颇具挑战性的任务。在该场景下,AI 需要根据用户的要求自动操作手机,逐步完成任务。

将不同的基模型象征为不同品种的狗,其中相同的「狗形指纹」表明它们源自同一个基模型。

华中科技大学联合华南理工大学、北京科技大学等机构的研究人员对14个主流多模态大模型进行了全面测评,涵盖5个任务,27个数据集。

来自UCLA的华人团队提出一种全新的LLM自我对弈系统,能够让LLM自我合成数据,自我微调提升性能,甚至超过了用GPT-4作为专家模型指导的效果。
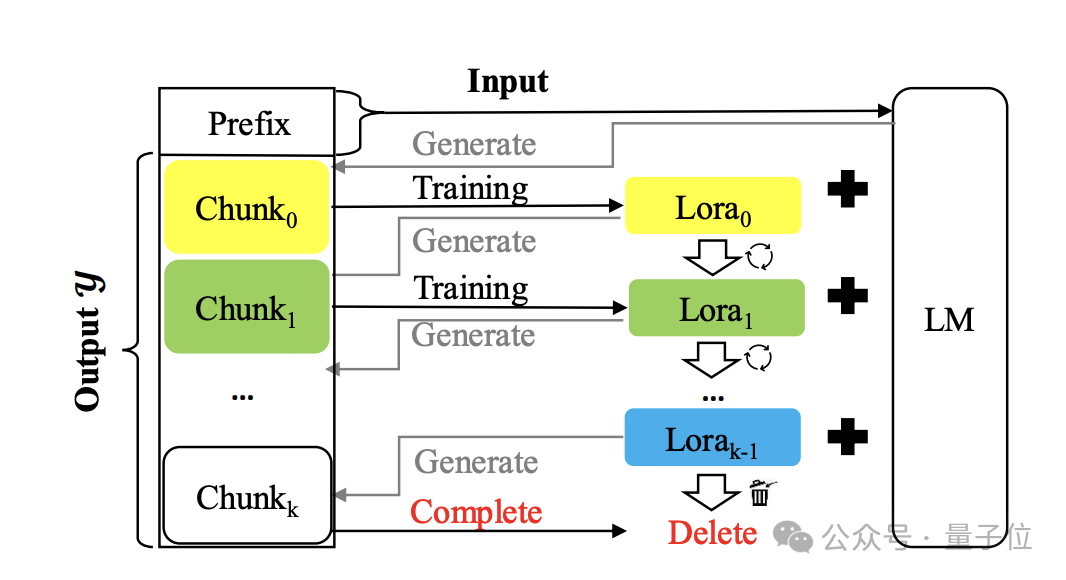
来看一个奇妙新解:和长度外推等方法使用KV缓存的本质不同,它用模型的参数来存储大量上下文信息。

在 AI 赛道中,与动辄上千亿参数的模型相比,最近,小模型开始受到大家的青睐。比如法国 AI 初创公司发布的 Mistral-7B 模型,其在每个基准测试中,都优于 Llama 2 13B,并且在代码、数学和推理方面也优于 LLaMA 1 34B。

过去几个月中,随着 GPT-4V、DALL-E 3、Gemini 等重磅工作的相继推出,「AGI 的下一步」—— 多模态生成大模型迅速成为全球学者瞩目的焦点。
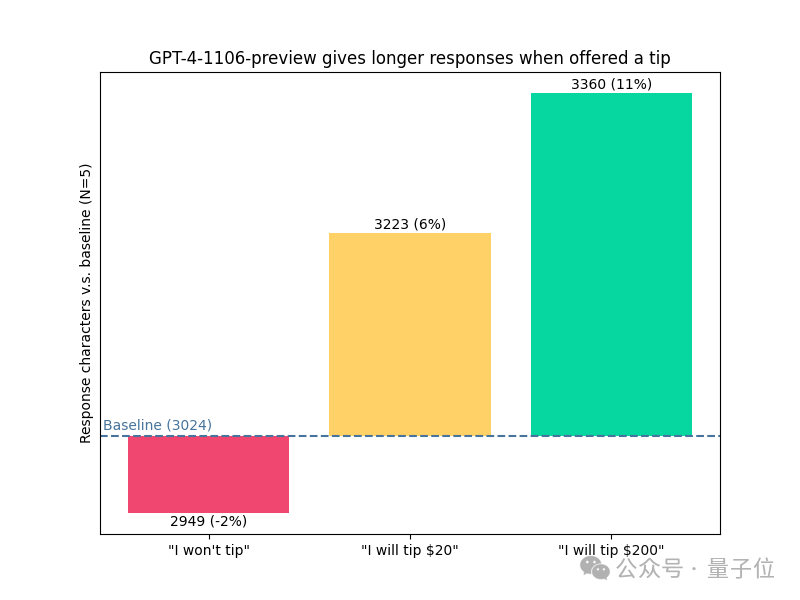
还有谁不知道“假装”给ChatGPT小费可以让它服务更卖力?

多模态大型语言模型进展如何?盘点 26 个当前最佳多模态大型语言模型。

对于大型视觉语言模型(LVLM)而言,扩展模型可以有效提高模型性能。然而,扩大参数规模会显著增加训练和推理成本,因为计算中每个 token 都会激活所有模型参数。
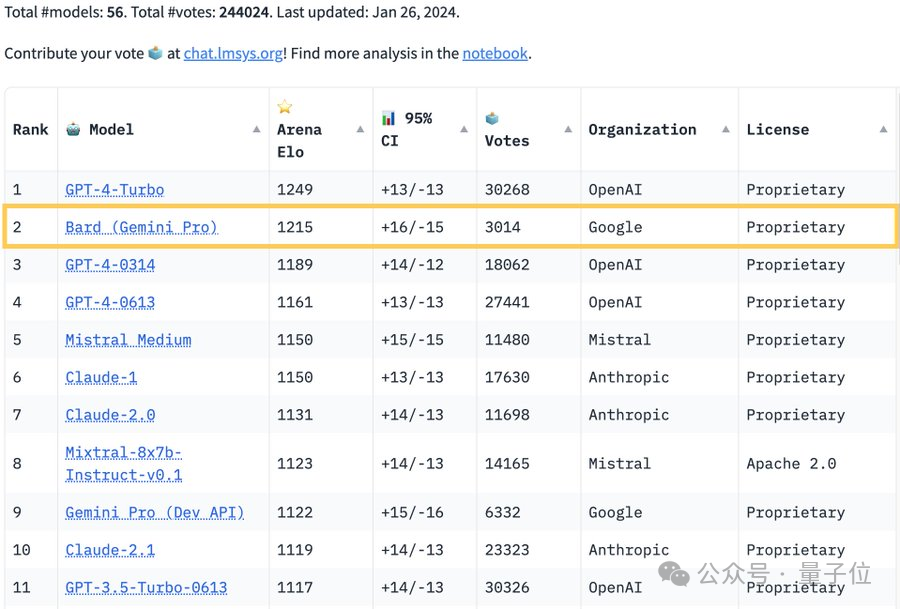
“大模型排位赛”权威榜单Chatbot Arena刷新:谷歌Bard超越GPT-4,排名位居第二,仅次于GPT-4 Turbo。
羊驼家族的“最强开源代码模型”,迎来了它的“超大杯”——就在今天凌晨,Meta宣布推出Code Llama的70B版本。