

人类偏好优化算法哪家强?跟着高手一文学懂DPO、IPO和KTO
人类偏好优化算法哪家强?跟着高手一文学懂DPO、IPO和KTO尽管收集人类对模型生成内容的相对质量的标签,并通过强化学习从人类反馈(RLHF)来微调无监督大语言模型,使其符合这些偏好的方法极大地推动了对话式人工智能的发展。
来自主题: AI技术研报
8786 点击 2024-02-18 12:25
尽管收集人类对模型生成内容的相对质量的标签,并通过强化学习从人类反馈(RLHF)来微调无监督大语言模型,使其符合这些偏好的方法极大地推动了对话式人工智能的发展。

刚刚,我们经历了LLM划时代的一夜。谷歌又在深夜发炸弹,Gemini Ultra发布还没几天,Gemini 1.5就来了。卯足劲和OpenAI微软一较高下的谷歌,开始进入了高产模式。

如果允许学生用AI“作弊”,他们的成绩分布会发生怎样的变化?
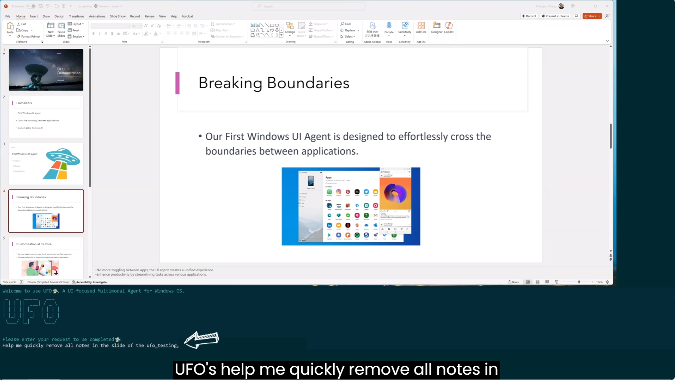
微软首个为Windows而设的智能体(Agent) 亮相:基于GPT-4V,一句话就可以在多个应用中无缝切换,完成复杂任务。整个过程无需人为干预,其执行成功率和效率是GPT-4的两倍,GPT-3.5的四倍。

检索增强生成(RAG)和微调(Fine-tuning)是提升大语言模型性能的两种常用方法,那么到底哪种方法更好?在建设特定领域的应用时哪种更高效?微软的这篇论文供你选择时进行参考。
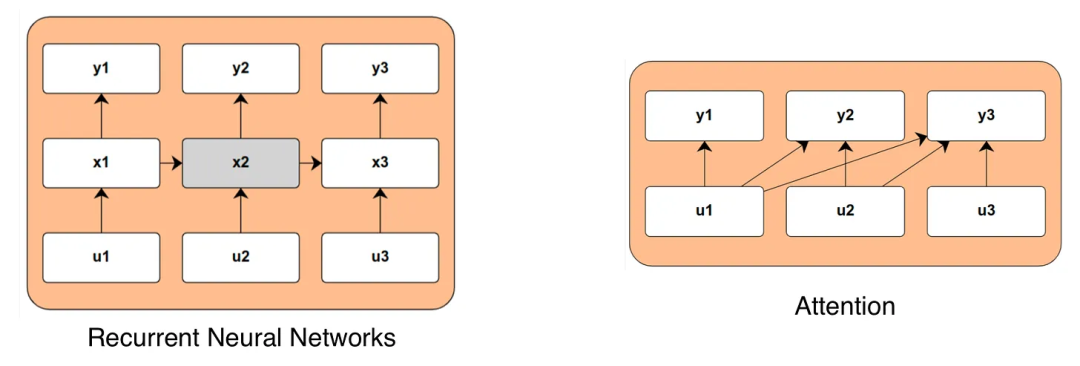
状态空间模型正在兴起,注意力是否已到尽头?
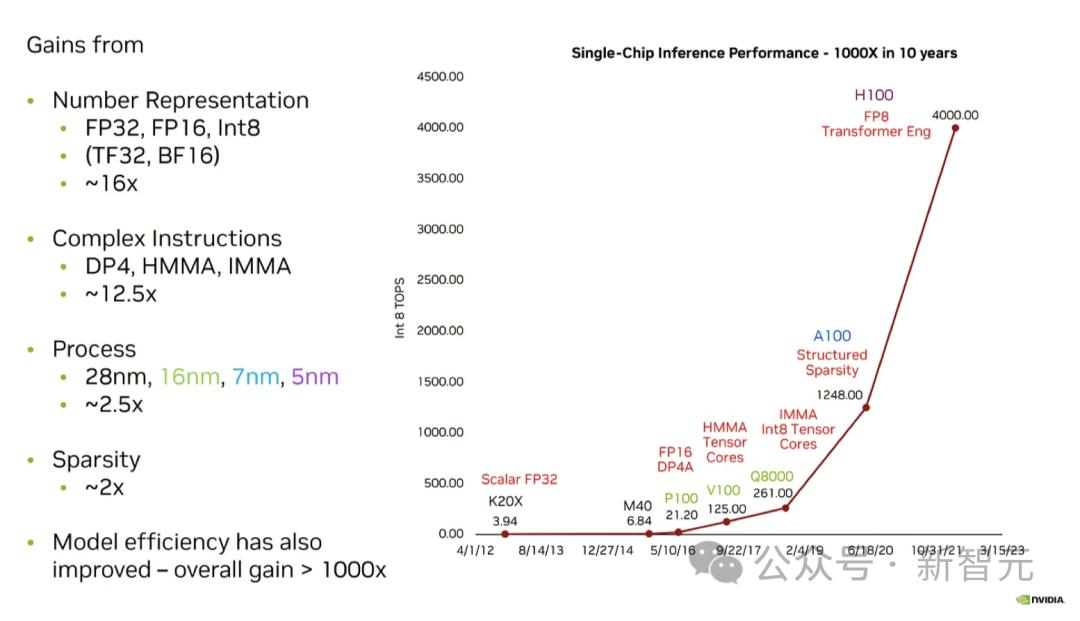
为了应对大模型不断复杂的推理和训练,英伟达、AMD、英特尔、谷歌、微软、Meta、Arm、高通、MatX以及Lemurian Labs,纷纷开始研发全新的硬件解决方案。

近日,北大、斯坦福、以及Pika Labs发布了新的开源文生图框架,利用多模态LLM的能力成功解决文生图两大难题,表现超越SDXL和DALL·E 3
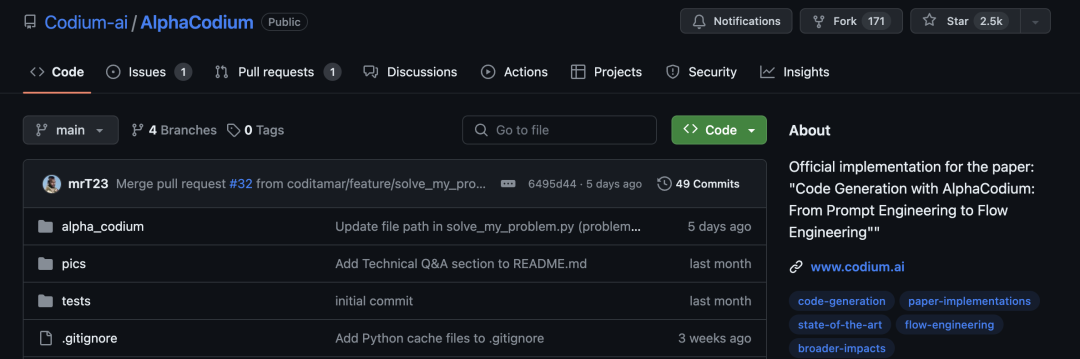
Karpathy力推代码生成任务增强流程,让GPT-4在CodeContests从19%提升到44%,不用微调不用新数据集训练,让大模型代码能力大幅提升。
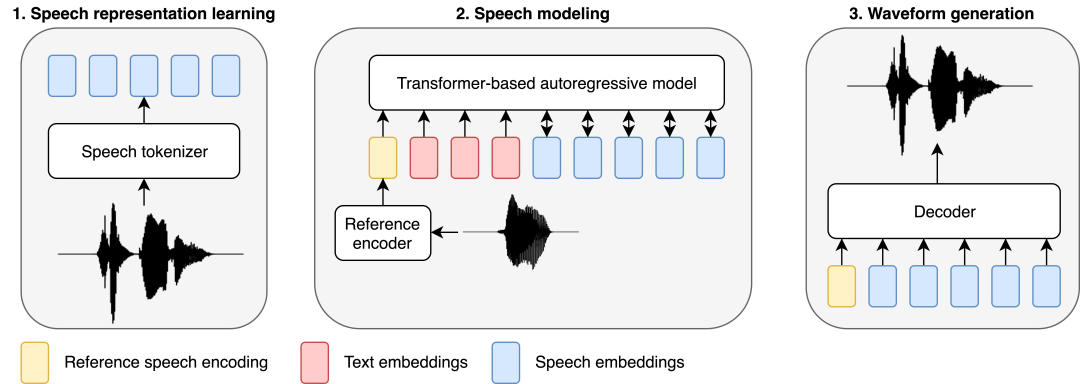
伴随着生成式深度学习模型的飞速发展,自然语言处理(NLP)和计算机视觉(CV)已经经历了根本性的转变,从有监督训练的专门模型,转变为只需有限的明确指令就能完成各种任务的通用模型

分布式强化学习是一个综合的研究子领域,需要深度强化学习算法以及分布式系统设计的互相感知和协同。考虑到 DDRL 的巨大进步,我们梳理形成了 DDRL 技术的展历程、挑战和机遇的系列文章。

最近来自香港科技大学(HKUST)、南洋理工大学(NTU)与加利福尼亚大学洛杉矶分校(UCLA)的研究者们提供了新的思路:他们发现大语言模型如 ChatGPT 可以理解传感器信号进而完成物理世界中的任务。该项目初步成果发表于 ACM HotMobile 2024。

最近,UIUC苹果华人提出了一个通用智能体框架CodeAct,通过Python代码统一LLM智能体的行动。

大模型的新考验来了!近日,来自卡内基梅隆大学的研究人员发布了评估LLM多模态Web代理性能的基准测试。
抱着年终总结,也是对过去一年回顾与展望的态度,来自 Ahead AI 的 Sebastian Raschka 博士为我们带来了 2023 年最值得大家关注,也是最有影响力的十篇 AI 论文,这里我们就和大家一起,用这十篇工作再次为 2023 年写下一段注脚

造大模型的成本,又被打下来了!这次是数据量狂砍95%的那种。陈丹琦团队最新提出大模型降本大法——数据选择算法LESS, 只筛选出与任务最相关5%数据来进行指令微调,效果比用整个数据集还要好。

单图 3D 说话人视频合成 (One-shot 3D Talking Face Generation) 可以被视作解决这一难题的下一代虚拟人技术。它旨在从单张图片中重建出目标人的三维化身 (3D Avatar)
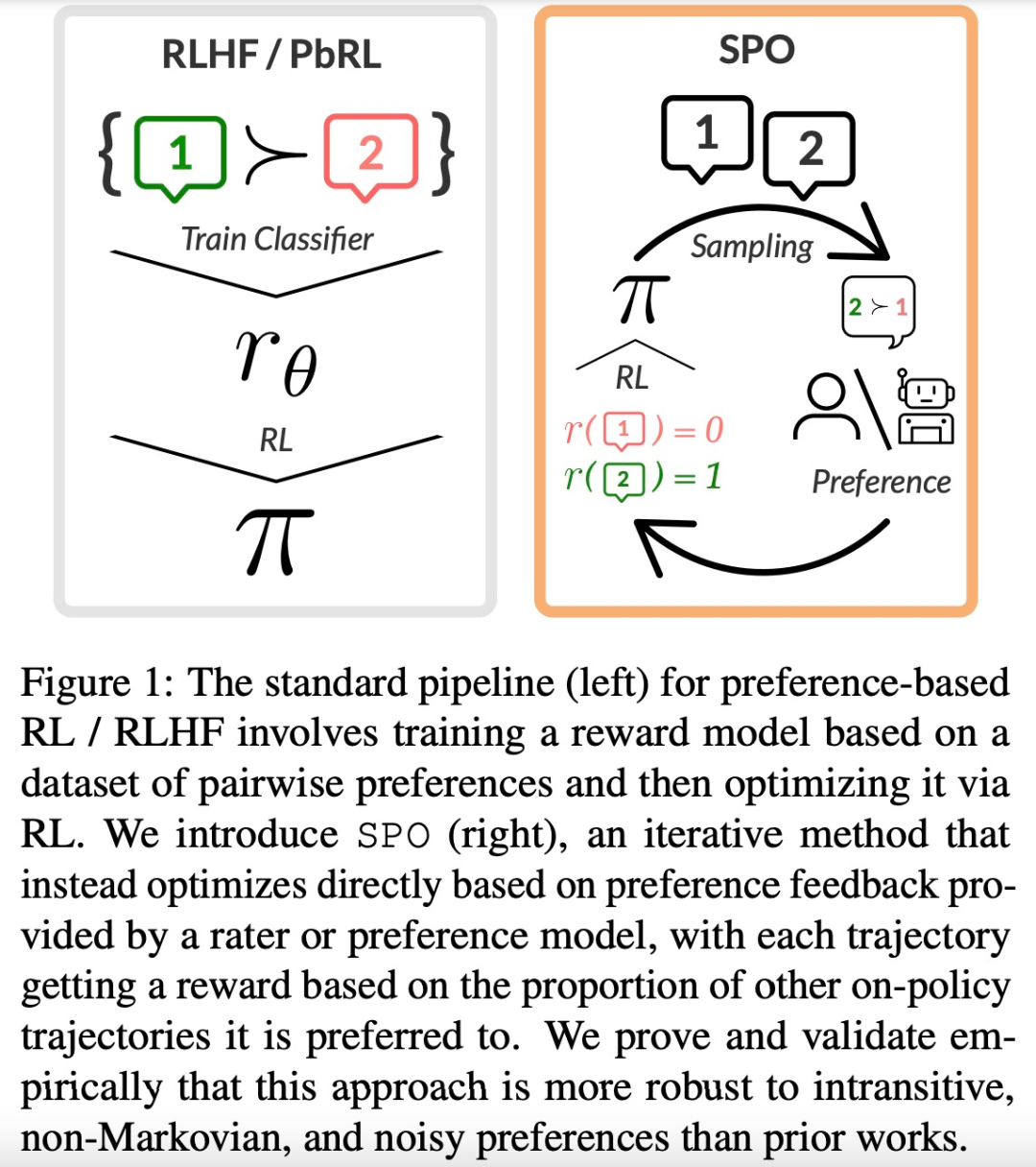
大型语言模型(LLM)的成功离不开「基于人类反馈的强化学习(RLHF)」。RLHF 可以大致可以分为两个阶段,首先,给定一对偏好和不偏好的行为,训练一个奖励模型,通过分类目标为前者分配更高的分数。
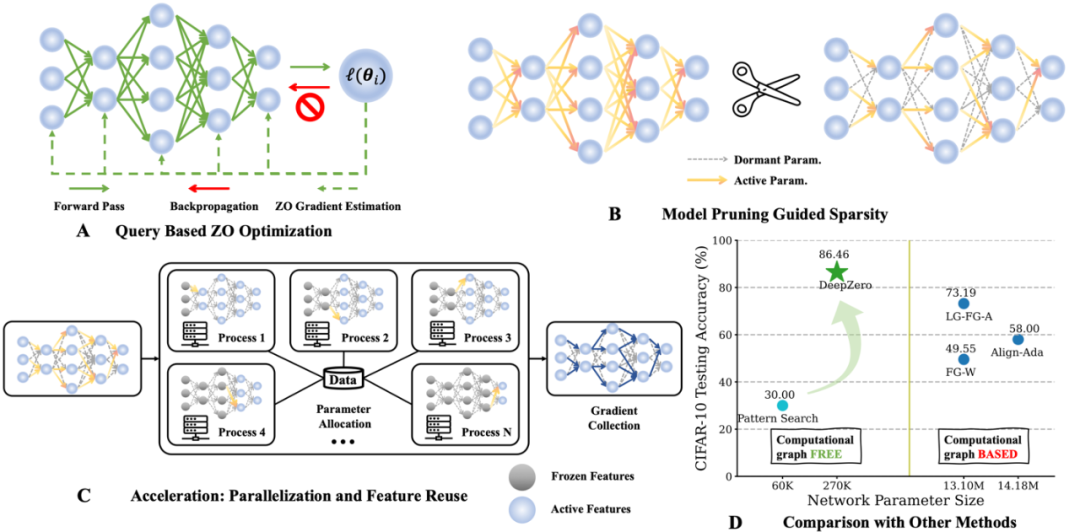
今天介绍一篇密歇根州立大学 (Michigan State University) 和劳伦斯・利弗莫尔国家实验室(Lawrence Livermore National Laboratory)的一篇关于零阶优化深度学习框架的文章 ,本文被 ICLR 2024 接收,代码已开源。

2023 年,大型语言模型(LLM)以其强大的生成、理解、推理等能力而持续受到高度关注。然而,训练和部署 LLM 非常昂贵,需要大量的计算资源和内存,因此研究人员开发了许多用于加速 LLM 预训练、微调和推理的方法。

混合专家(MoE)架构已支持多模态大模型,开发者终于不用卷参数量了!北大联合中山大学、腾讯等机构推出的新模型MoE-LLaVA,登上了GitHub热榜。
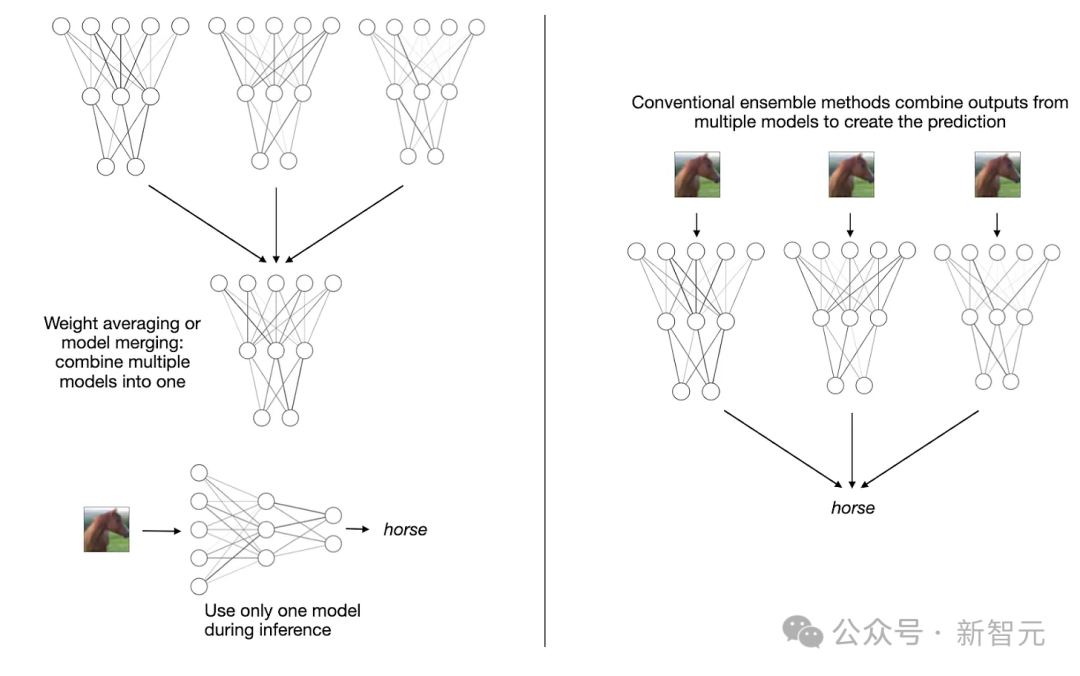
AI大模型并非越大越好?过去一个月,关于大模型变小的研究成为亮点,通过模型合并,采用MoE架构都能实现小模型高性能。
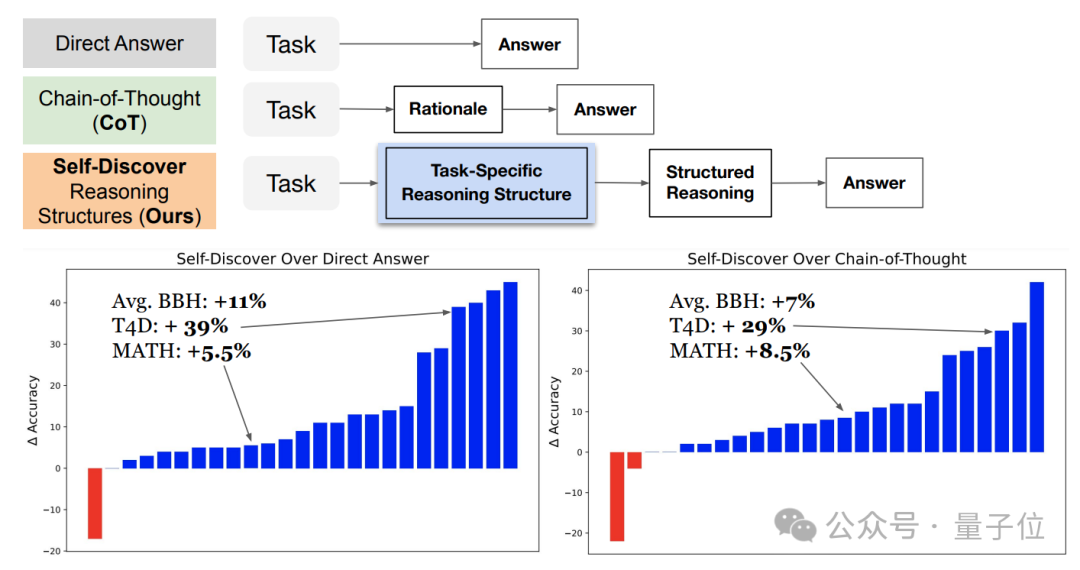
谷歌&南加大推出最新研究“自我发现”(Self-Discover),重新定义了大模型推理范式。与已成行业标准的思维链(CoT)相比,新方法不仅让模型在面对复杂任务时表现更佳,还把同等效果下的推理成本压缩至1/40。
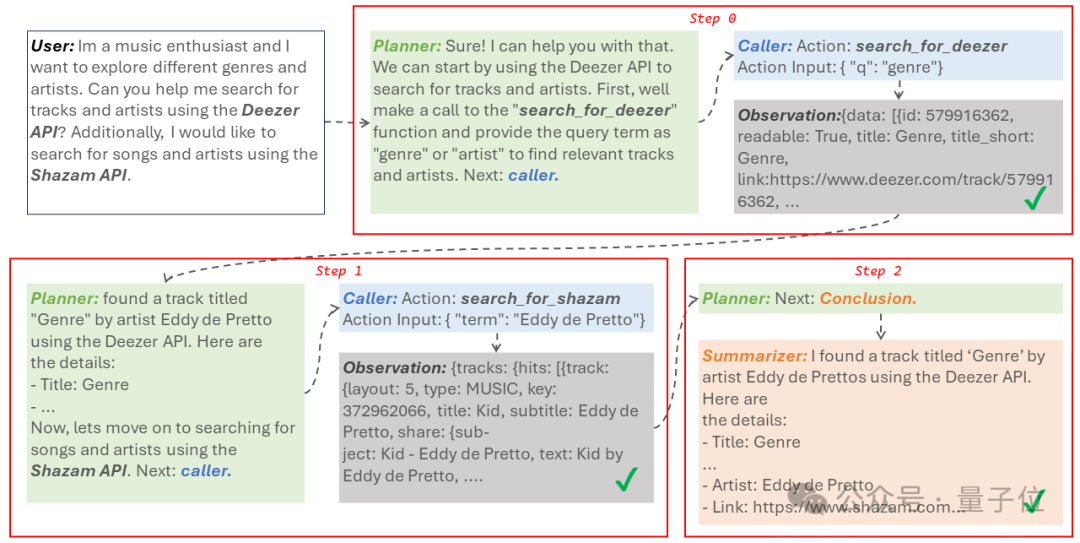

7B开源模型,数学能力超过了千亿规模的GPT-4!它的表现可谓是突破了开源模型的极限,连阿里通义的研究员也感叹缩放定律是不是失效了。
随着越来越多的企业将人工智能应用于其产品,AI芯片需求快速增长,市场规模增长显著。因此,本文主要针对目前市场上的AI芯片厂商及其产品进行简要概述。
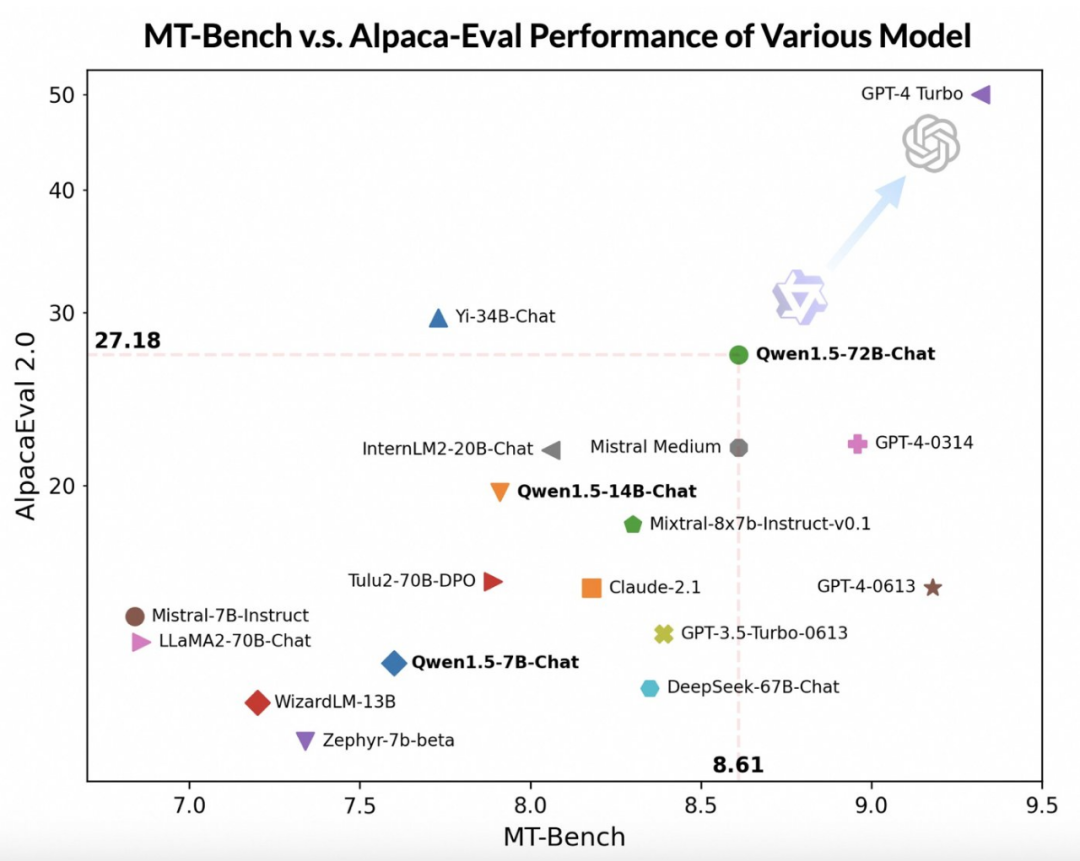
赶在春节前,通义千问大模型(Qwen)的 1.5 版上线了。今天上午,新版本的消息引发了 AI 社区关注。

现有的语义分割技术在评估指标、损失函数等设计上都存在缺陷,研究人员针对相关缺陷设计了全新的损失函数、评估指标和基准,在多个应用场景下展现了更高的准确性和校准性。

最近,复旦、俄亥俄州立大学、Meta和宾夕法尼亚州立大学的研究者发现,GPT-4 Agent规划旅行只有0.6%成功率!离在人类复杂环境中做出规划,智能体还任重道远。
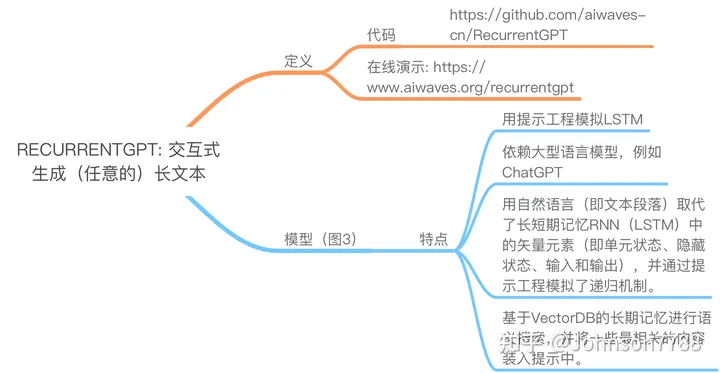
Transformer的固定尺寸上下文使得GPT模型无法生成任意长的文本。在本文中,我们介绍了RECURRENTGPT,一个基于语言的模拟RNN中的递归机制。