

MATRIX:社会模拟推动大模型价值自对齐,比GPT4更「体贴」
MATRIX:社会模拟推动大模型价值自对齐,比GPT4更「体贴」随着大语言模型(LLMs)在近年来取得显著进展,它们的能力日益增强,进而引发了一个关键的问题:如何确保他们与人类价值观对齐,从而避免潜在的社会负面影响?
来自主题: AI技术研报
10666 点击 2024-02-27 14:03
随着大语言模型(LLMs)在近年来取得显著进展,它们的能力日益增强,进而引发了一个关键的问题:如何确保他们与人类价值观对齐,从而避免潜在的社会负面影响?

大模型的成功很大程度上要归因于 Scaling Law 的存在,这一定律量化了模型性能与训练数据规模、模型架构等设计要素之间的关系,为模型开发、资源分配和选择合适的训练数据提供了宝贵的指导。

问世才两个星期,谷歌的世界模型也来了,能力看起来更强大:它生成的虚拟世界「自主可控」。

2023 年年底,很多人都预测,未来一年将是视频生成快速发展的一年。但出人意料的是,农历春节刚过,OpenAI 就扔出了一个重磅炸弹 —— 能生成 1 分钟流畅、逼真视频的 Sora。

无数人类天才穷尽一生才合伙建立残缺的大统一理论(GUT):它只统一了强相互作用、弱相互作用和电磁力,引力至今无法统一到模型之中。

SemiAnalysis的行业专家对最近爆火的Groq推理系统进行了像素级的拆解,测算出其持有成本依然高达现有H100的10倍,看来要赶上老黄的步伐,初创公司还有很多要做。

谷歌DeepMind最新研究发现,问题中前提条件的呈现顺序,对于大模型的推理性能有着决定性的影响,打乱顺序能让模型表现下降30%。

近日,普林斯顿大学和普林斯顿等离子体物理实验室研究核聚变能的科学家表示,他们已经找到了一种使用人工智能的方法,预测这些潜在不稳定性并实时阻止其发生。

扩散模型,迎来了一项重大新应用——像Sora生成视频一样,给神经网络生成参数,直接打入了AI的底层!

谷歌团队推出「通用视觉编码器」VideoPrism,在3600万高质量视频字幕对和5.82亿个视频剪辑的数据集上完成了训练,性能刷新30项SOTA。

终有一天,LLM可以成为人类数据专家,针对不同领域进行数据分析,大大解放AI研究员。

困扰可控核聚变的一项重大难题,被AI成功攻克了!普林斯顿团队通过训练神经网络,提前300毫秒就预测了核聚变中的等离子不稳定态,因而能够防止等离子体的逃逸。人类离无穷尽的清洁能源,又近了一步。

2 月 16 日,OpenAI Sora 的发布无疑标志着视频生成领域的一次重大突破。Sora 基于 Diffusion Transformer 架构,和市面上大部分主流方法(由 2D Stable Diffusion 扩展)并不相同。

最近几年,基于 Transformer 的架构在多种任务上都表现卓越,吸引了世界的瞩目。使用这类架构搭配大量数据,得到的大型语言模型(LLM)等模型可以很好地泛化用于真实世界用例。
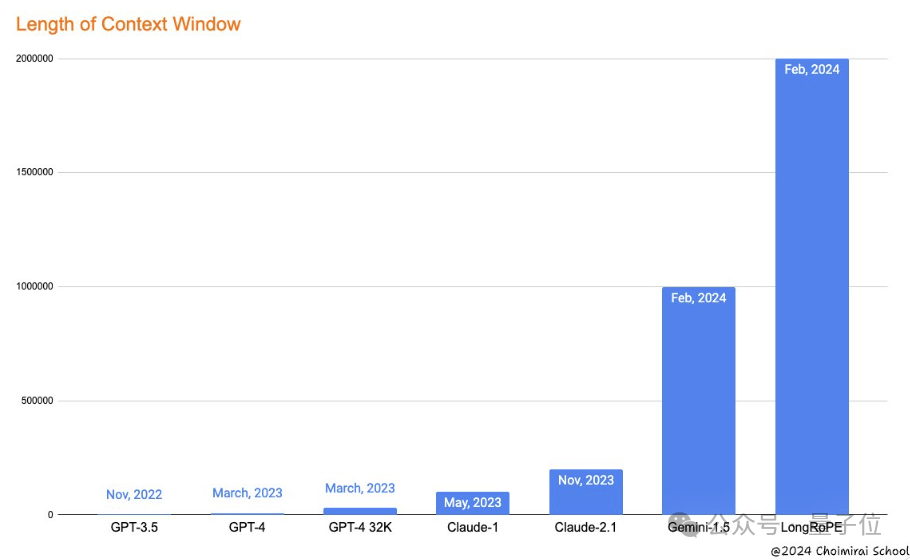
谷歌刚刷新大模型上下文窗口长度记录,发布支持100万token的Gemini 1.5,微软就来砸场子了。

距离YOLOv8发布仅1年的时间,v9诞生了!

继 2023 年 1 月 YOLOv8 正式发布一年多以后,YOLOv9 终于来了!

谷歌Research Lead,负责VideoPoet项目的蒋路,即将加入TikTok,负责视频生成AI的开发。

在过去的 2023 年中,大型语言模型(LLM)在潜力和复杂性方面都获得了飞速的发展。展望 2024 年的开源和研究进展,似乎我们即将进入一个可喜的新阶段:在不增大模型规模的前提下让模型变得更好,甚至让模型变得更小。

由蛋白质和小分子配体形成的结合复合物无处不在,对生命至关重要。虽然最近科学家在蛋白质结构预测方面取得了进展,但现有算法无法系统地预测结合配体结构及其对蛋白质折叠的调节作用。
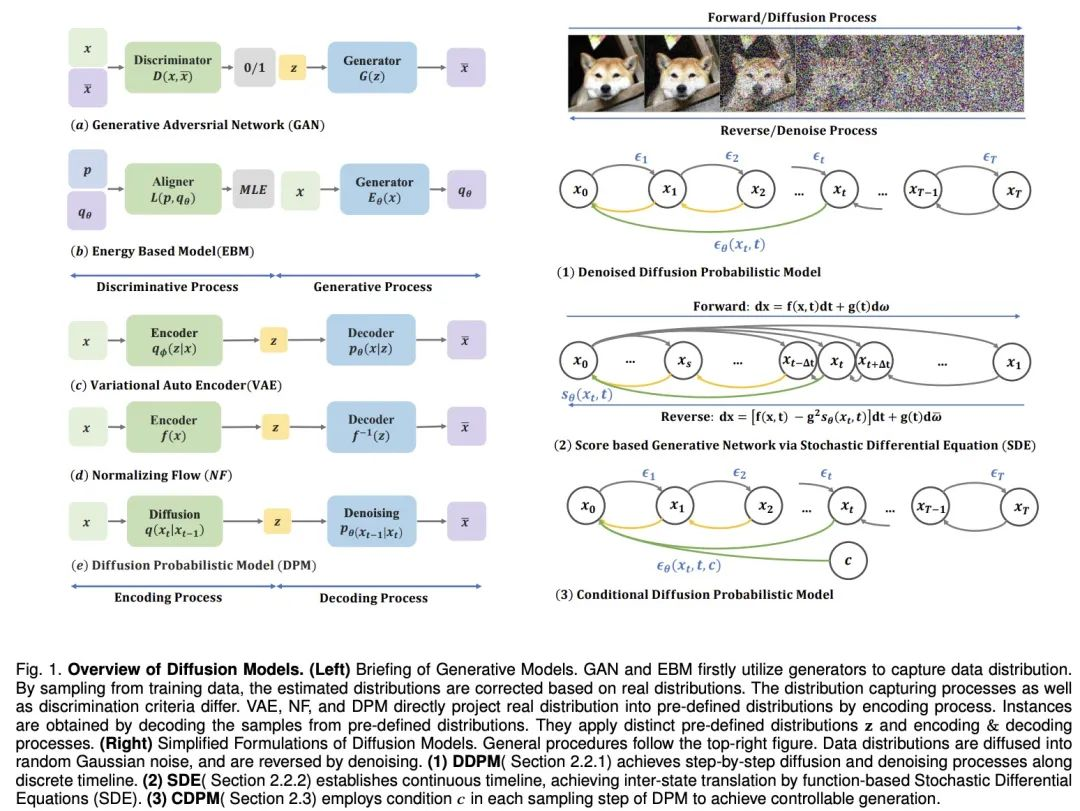
为了使机器具有人类的想象力,深度生成模型取得了重大进展。这些模型能创造逼真的样本,尤其是扩散模型,在多个领域表现出色。扩散模型解决了其他模型的限制,如 VAEs 的后验分布对齐问题、GANs 的不稳定性、EBMs 的计算量大和 NFs 的网络约束问题。
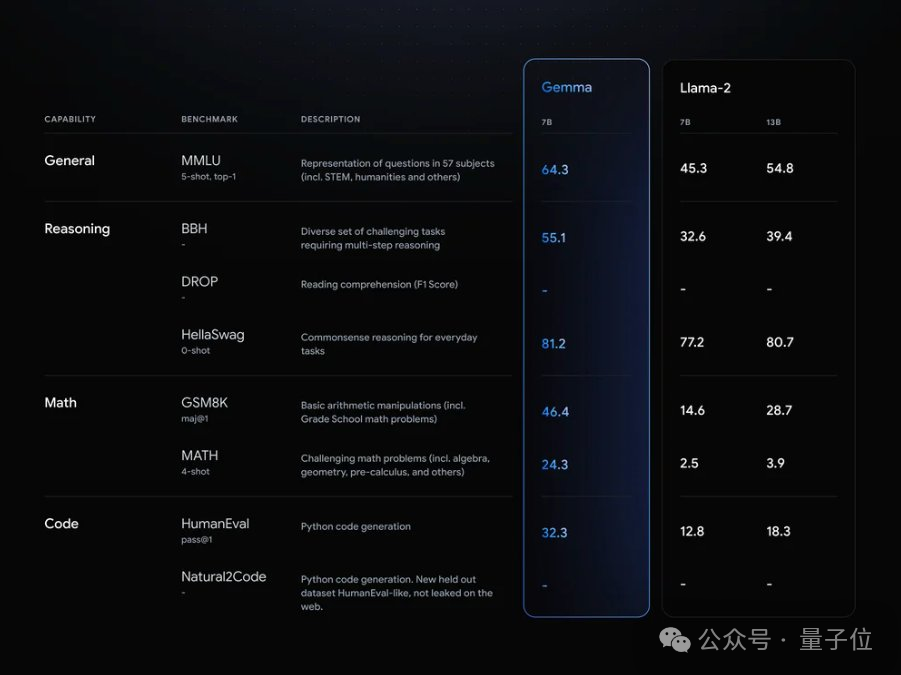
谷歌大模型,开源了!一夜之间,Gemma系列正式上线,全面对外开放。

大语言模型之大,成本之高,让模型的稀疏化变得至关重要。

财报发布前两天,英伟达突然冒出来一个劲敌。一家名叫Groq的公司今天在AI圈内刷屏,杀招就一个:快。

推测解码(Speculative Decoding)是谷歌等机构在 2022 年发现的大模型推理加速方法。它可以在不损失生成效果前提下,获得 3 倍以上的加速比。GPT-4 泄密报告也提到 OpenAI 线上模型推理使用了它。
简单说一下我的见解,以公司和技术趋势而不是个人的角度做一些分析,并预测一些OpenAI下一步的进展。

我们接连被谷歌的多模态模型 Gemini 1.5 以及 OpenAI 的视频生成模型 Sora 所震撼到,前者可以处理的上下文窗口达百万级别,而后者生成的视频能够理解运动中的物理世界,被很多人称为「世界模型」。

大模型内卷时代,也不断有人跳出来挑战Transformer的统治地位,RWKV最新发布的Eagle 7B模型登顶了多语言基准测试,同时成本降低了数十倍
短短几天,「世界模型」雏形相继诞生,AGI真的离我们不远了?Sora之后,LeCun首发AI视频预测架构V-JEPA,能够以人类的理解方式看世界。

视觉语言模型虽然强大,但缺乏空间推理能力,最近 Google 的新论文说它的 SpatialVLM 可以做,看看他们是怎么做的。